云中的机器学习:FPGA上的深度神经网络
加法。通过流水线处理,第一个输出的时延略有增加,但每个周期我们都可获得一个输出。
使用AuvizDNN在FPGA上实现的完整CNN就像从C/C++程序中调用一连串函数。在建立对象和数据容器后,首先通过函数调用来创建每个卷积层,然后创建致密层,最后是创建softmax层,如图 4 所示。
AuvizDNN是Auviz Systems公司提供的一种函数库,用于在FPGA上实现CNN。该函数库提供轻松实现CNN所需的所有对象、类和函数。用户只需要提供所需的参数来创建不同的层。例如,图5中的代码片段显示了如何创建AlexNet中的第一层。
AuvizDNN提供配置函数,用以创建CNN的任何类型和配置参数。AlexNet仅用于演示说明。CNN 实现内容作为完整比特流载入FPGA并从C/C++程序中调用,这使开发人员无需运行实现软件即可使用AuvizDNN。
FPGA具有大量的查找表(LUT)、DSP模块和片上存储器,因此是实现深度CNN的最佳选择。在数据中心,单位功耗性能比原始性能更为重要。数据中心需要高性能,但功耗要在数据中心服务器要求限值之内。
像赛灵思Kintex UltraScale 这样的FPGA器件可提供高于14张图像/秒/瓦特的性能,使其成为数据中心应用的理想选择。图6介绍了使用不同类型的FPGA所能实现的性能。
一切始于C/C++
卷积神经网络备受青睐,并大规模部署用于处理图像识别、自然语言处理等众多任务。随着CNN从高性能计算应用(HPC)向数据中心迁移,需要采用高效方法来实现它们。
FPGA可高效实现CNN。FPGA的具有出色的单位功耗性能,因此非常适用于数据中心。
AuvizDNN函数库可用来在FPGA上实现CNN。AuvizDNN能降低FPGA的使用复杂性,并提供用户可从其C/C++程序中调用的简单函数,用以在FPGA上实现加速。使用AuvizDNN时,可在AuvizDNN 库中调用函数,因此实现FPGA加速与编写C/C++程序没有太大区别。
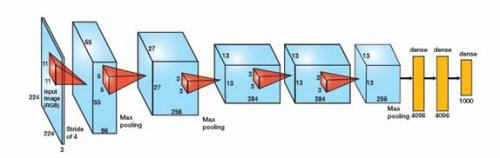
图 1 – AlexNet是一种图像识别基准,包含五个卷积层(蓝框)和三个致密层(黄)。

图 2 – AlexNet中的卷积层执行3D卷积、激活和子采样。

图 3 – 图表展示了AlexNet中涉及的计算复杂性和数据传输数量。

图 4 - 实现CNN时的函数调用顺序。
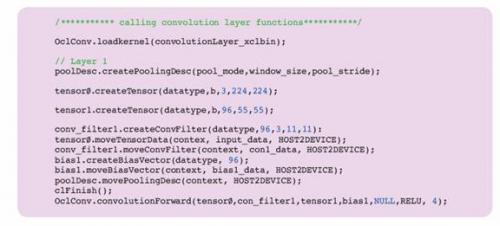
图 5 – 使用AuvizDNN创建AlexNet的L1的代码片段。
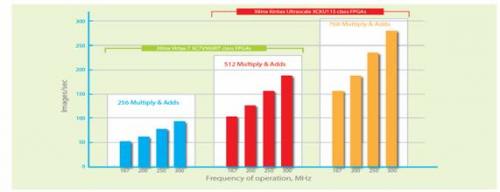
图 6 – AlexNets的性能因FPGA类型不同而不同。
- 2017年存储技术新趋势,谁才是最终的王者?(01-22)
- 科技新势力:机器视觉让人类看到的世界更精彩(12-21)
- 盘点之人工智能四巨头(12-19)
- 改变世界的黑科技,中国怎能甘心落后?(12-13)
- 关于PID系列仪表的人工智能控制算法(05-04)
- 传感器技术进步推动机器人智能化发展(02-16)