云中的机器学习:FPGA上的深度神经网络
凭借出色的性能和功耗指标,赛灵思FPGA成为设计人员构建卷积神经网络的首选。新的软件工具可简化实现工作。
人工智能正在经历一场变革,这要得益于机器学习的快速进步。在机器学习领域,人们正对一类名为“深度学习”算法产生浓厚的兴趣,因为这类算法具有出色的大数据集性能。在深度学习中,机器可以在监督或不受监督的方式下从大量数据中学习一项任务。大规模监督式学习已经在图像识别和语音识别等任务中取得巨大成功。
深度学习技术使用大量已知数据找到一组权重和偏差值,以匹配预期结果。这个过程被称为训练,并会产生大型模式。这激励工程师倾向于利用专用硬件(例如GPU)进行训练和分类。
随着数据量的进一步增加,机器学习将转移到云。大型机器学习模式实现在云端的CPU上。尽管GPU对深度学习算法而言在性能方面是一种更好的选择,但功耗要求之高使其只能用于高性能计算集群。因此,亟需一种能够加速算法又不会显著增加功耗的处理平台。在这样的背景下,FPGA 似乎是一种理想的选择,其固有特性有助于在低功耗条件下轻松启动众多并行过程。
让我们来详细了解一下如何在赛灵思FPGA上实现卷积神经网络(CNN)。CNN是一类深度神经网络,在处理大规模图像识别任务以及与机器学习类似的其他问题方面已大获成功。在当前案例中,针对在FPGA上实现CNN做一个可行性研究,看一下FPGA是否适用于解决大规模机器学习问题。
卷积神经网络是一种深度神经网络(DNN),工程师最近开始将该技术用于各种识别任务。图像识别、语音识别和自然语言处理是CNN比较常见的几大应用。
什么是卷积神经网络?
卷积神经网络是一种深度神经网络 (DNN),工程师最近开始将该技术用于各种识别任务。图像识别、语音识别和自然语言处理是 CNN 比较常见的几大应用。
2012年,Alex Krishevsky与来自多伦多大学(University of Toronto)的其他研究人员 [1] 提出了一种基于CNN的深度架构,赢得了当年的“Imagenet 大规模视觉识别挑战”奖。他们的模型与竞争对手以及之前几年的模型相比在识别性能方面取得了实质性的提升。自此,AlexNet成为了所有图像识别任务中的对比基准。
AlexNet有五个卷积层和三个致密层(图1)。每个卷积层将一组输入特征图与一组权值滤波器进行卷积,得到一组输出特征图。致密层是完全相连的一层,其中的每个输出均为所有输入的函数。
卷积层
AlexNet中的卷积层负责三大任务,如图2所示:3D卷积;使用校正线性单元(ReLu)实现激活函数;子采样(最大池化)。3D卷积可用以下公式表示:
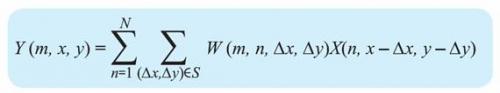
其中Y(m,x,y)是输出特征图m位置(x,y)处的卷积输出,S是(x,y)周围的局部邻域,W是卷积滤波器组,X(n,x,y)是从输入特征图n上的像素位置(x,y)获得的卷积运算的输入。
所用的激活函数是一个校正线性单元,可执行函数Max(x,0)。激活函数会在网络的传递函数中引入非线性。最大池化是 AlexNet 中使用的子采样技术。使用该技术,只需选择像素局部邻域最大值传播到下一层。
定义致密层
AlexNet中的致密层相当于完全连接的层,其中每个输入节点与每个输出节点相连。AlexNet中的第一个致密层有9,216个输入节点。将这个向量乘以权值矩阵,以在4,096个输出节点中产生输出。在下一个致密层中,将这个 4,096 节点向量与另一个权值矩阵相乘得到4,096个输出。最后,使用4,096个输出通过softmax regression为1,000个类创建概率。
在FPGA上实现CNN
随着新型高级设计环境的推出,软件开发人员可以更方便地将其设计移植到赛灵思FPGA中。软件开发人员可通过从C/C++代码调用函数来充分利用 FPGA与生俱来的架构优势。Auviz Systems的库(例如AuvizDNN)可为用户提供最佳函数,以便其针对各种应用创建定制CNN。可在赛灵思SD-Accel这样的设计环境中调用这些函数,以在FPGA上启动内核。
最简单的方法是以顺序方式实现卷积和向量矩阵运算。考虑到所涉及计算量,因此顺序计算会产生较大时延。
顺序实现产生很大时迟的主要原因在于CNN所涉及的计算的绝对数量。图3显示了AlexNet中每层的计算量和数据传输情况,以说明其复杂性。
因此,很有必要采用并行计算。有很多方法可将实现过程并行化。图6给出了其中一种。在这里,将11x11的权值矩阵与一个11x11的输入特征图并行求卷积,以产生一个输出值。这个过程涉及121个并行的乘法-累加运算。根据FPGA的可用资源,我们可以并行对512抑或768个值求卷积。
为了进一步提升吞吐量,我们可以将实现过程进行流水线化。流水线能为需要一个周期以上才能完成的运算实现更高的吞吐量,例如浮点数乘法和
- 2017年存储技术新趋势,谁才是最终的王者?(01-22)
- 科技新势力:机器视觉让人类看到的世界更精彩(12-21)
- 盘点之人工智能四巨头(12-19)
- 改变世界的黑科技,中国怎能甘心落后?(12-13)
- 关于PID系列仪表的人工智能控制算法(05-04)
- 传感器技术进步推动机器人智能化发展(02-16)