基于可编程状态机的Turbo译码器设计
1993年Berrou C. 等学者提出的Turbo码将卷积编码和随机交织结合在一起实现了随机编码的思想[1],并且采用了软输入软输出(SISO)迭代译码的最大似然译码算法,从而使其译码性能接近于Shannon理论的极限。目前,Turbo码的应用已推广到深空通信、卫星通信和移动通信等领域,并被确定为第三代移动通信的信道编码方案之一。
在不同的应用环境中,出于对译码性能和译码复杂度的考虑,通常选用不同的译码参数。其中直接影响到译码性能的关键参数有帧长、交织表和迭代次数等。本文介绍的基于KCPSM的Turbo译码器在设计中引入嵌入式处理器单元,通过存储于外部RAM中的程序控制译码过程,可根据不同的使用需求修改程序代码以适用于各种不同的译码情况。
1 Turbo译码原理
Turbo码的特点:编码器中引入了交织器,减弱了信息序列的相关性,有效地实现了随机性编码;在译码时采取了迭代译码的思想,使其性能可以接近香农理论的极限。
Turbo码的迭代反馈译码结构如图1所示[2]。图中,SISO Decoder 1和SISO Decoder 2是分别对应于编码产生的两组分量码的软输入软输出译码器。两个SISO译码器通过反复的交错重复译码计算完成对输入信息序列的译码。SISO Decoder 1的软输出信息交织后作为SISO Decoder 2译码的先验信息。如果迭代结束,SISO Decoder 2的译码结果硬判决输出;否则,SISO Decoder 2的软输出信息反交织后作为SISO Decoder 1下一次迭代译码的先验信息。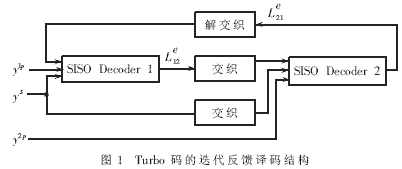
在Turbo码的译码算法中,MAP算法的性能最好,但计算量巨大,硬件实现的复杂度高,译码时延大。所以在硬件设计中采用的是在对数域上简化的Log-MAP算法,这样可以有效地降低硬件设计的复杂度。在Log-MAP译码算法中,需要先从数据序列末端向始端做反向状态概率β的递推计算,之后再从序列的始端向末端开始递推计算前向状态概率α并得到对数概率似然比。为了减少译码的等待延时,在译码时可将原先的一帧数据序列按特定的分组长度分解为数段,分别计算每段的软输出。在每段序列的计算中,仍然是先反向递推计算β值,再正向递推计算α值。其中,α值递推的初始值由上一段的计算结果给出。对于β值的递推,则需由下一段序列提供部分软信息。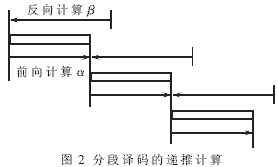
图2表述了分段译码的思想。采用分段译码时,用于存放中间结果的存储器规模取决于分组长度,不再与帧长成正比。对于不同帧长的译码只需改变交织表的大小,而译码单元不用改变。这样的译码器可以更方便地用于各种码长的译码。
2 Turbo译码器的设计
基于KCPSM的Turbo译码器基本可分为两个部分:TurboDec译码模块和KCPSM主控模块。
TurboDec译码模块的结构如图3所示。它由Trace译码单元、存储单元和交织器组成。Trace译码单元的作用是根据Log-MAP算法,对分组后的每段序列做前向或反向的递推计算。存储单元包括ZRAM(用于存放在运算过程中需要交换的外信息)、Input Buffer和Output Buffer(分别用于输入输出的缓存)。交织器的作用是实现对数据序列的交织和反交织,它主要是一块存有交织表的RAM,而交织表内存放有每位数据交织后对应的地址。Trace译码单元通过查找该交织表得到的地址作为以交织顺序读取或写入数据的地址。这块RAM中的交织表可在译码前由外部改写,以满足不同的译码需求。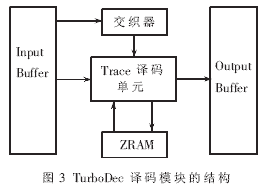
KCPSM主控模块采用的是Xilinx公司提供的PicoBlaze嵌入式处理器设计方案[3]。该模块中主要有两部分:负责数据信号处理及对外信号输入输出的PicoBlaze处理器单元和用于储存程序指令代码的Block Memory。PicoBlaze设计方案的结构如图4所示。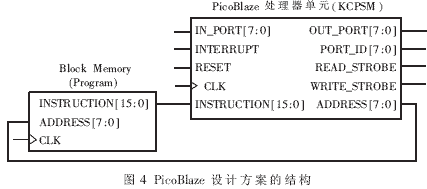
在时钟信号的驱动下,PicoBlaze处理器单元根据当前的8位地址从Block Memory中读取对应的16位指令代码,再根据此指令代码完成运算操作,同时产生下一步指令的地址。根据不同指令的要求,在IN_PORT端和OUT_PORT端分别读入或输出计算的数据,并在PORT_ID端指明对应的I/O端口地址。READ_STROBE端和WRITE_STROBE端则在执行读写操作时输出脉冲信号,该脉冲信号通常用于控制外围电路的读写。
3 KCPSM控制系统的设计
3.1KCPSM设计的特点
KCPSM是常变量可编程状态机的简称,其主要组成部分为嵌入式处理器单元,用于实现基于常量的状态机主控单元。与传统的基于时序电路的状态机控制设计相比,使用KCPSM作为主控单元有以下特点:
(1)结构简单,占用资源少。以Xilinx公司推出的8位嵌入式微处理器IP核PicoBlaze为例,其逻辑模块仅占用Spartan-IIE的76个slice,相当于最小的XC2S50E器件可用资源的9%,或XC2S300E器件可用资源的2.5%。对于较大规模的设计几乎可以忽略这样的资源占用。虽然该IP核占用的硬件资源很少,但它的运算性能可以达到40MIPS。因其占用资源少,在实际设计中可以同时使用多个KCPSM以完成复杂的控制功能。
(2)使用灵活,易于调试。对于KCPSM单元,控制状态的转换及相关信号的处理都是以程序指令的形式存储于Block RAM单元中,不涉及到IP核的逻辑模块单元。使用时只需要根据不同的目的编写相应的指令代码就可实现不同的功能。特别是在对电路进行调试时,易于实现特定的非正常运行状态。
(3)指令周期相对较长。KCPSM采用的是从Block RAM单元读取指令的操作模式,每步操作的完成包括确定RAM地址和读取指令两步,需要花费两个时钟周期。与由时序电路组成的状态机相比,KCPSM的运行效率较低,不适合用于对时钟沿敏感情况下的控制需要。
由上面几点可以看出,KCPSM作为可编程的控制单元,适合用于情况比较复杂但对时间要求不高的系统级控制,特别是有大量控制参数需要计算调整的情况。相对于由时序单元组成的控制电路,它在节省硬件开销的同时,降低了设计的复杂性,增强了设计的灵活性。
3.2Turbo译码的控制设计
根据Turbo码的迭代译码原理,KCPSM控制系统的基本流程如图5所示。从图中可以看出,该控制系统根据Turbo译码器当前的工作状态检测对应的控制信号并改变输出参数。当译码器没有处于译码状态时,KCPSM会周期性地检测译码启动信号。该信号有效后,Turbo译码器进入译码状态,KCPSM向TurboDec译码模块输出第一次反向递推译码计算的起始地址、译码段长度等参数和控制信号,同时准备下一次前向递推的相关参数。译码器进入译码状态后,KCPSM改为检测TurboDec译码模块的译码完成信号。当TurboDec完成递推译码计算后,KCPSM根据迭代次数决定是否还需要进行下一次的递推计算。若迭代译码过程尚未结束,KCPSM会控制TurboDec译码模块开始新一次的递推计算,并为下次的递推计算相关参数。迭代译码结束后,KCPSM使TurboDec译码模块输出译码结果,并控制Turbo译码器退出译码状态。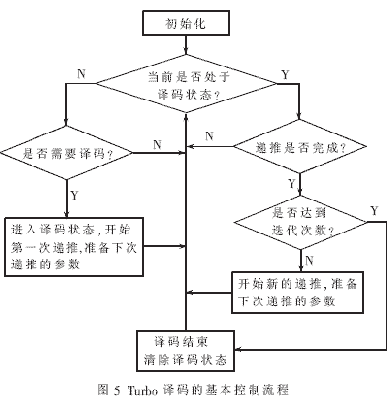
在整个译码过程中,KCPSM将Turbo译码器的状态以编码的形式存储在内部的寄存器中,并根据译码的要求和递推计算的次数确定下次递推译码的参数。TraceDec译码单元对前向状态概率的计算与对反向状态概率的计算是交替进行的,在每次译码操作后都要改变下次译码递推的方向。译码的起始地址和译码段的长度由译码方向和已完成的译码长度确定。对位于帧尾的最后一段序列,译码的起始地址和译码段的长度需根据剩余的序列长度进行调整。由于只有一个TurboDec译码模块作为SISO译码器,在结束一次MAP译码后,下一次的MAP译码需采用不同的校验序列,以实现对两组校验信息的充分利用。
在Turbo译码过程中,KCPSM要将多个参数传递给TurboDec译码模块,为此需要同时使用OUT_PORT和PORT_ID两个输出端口。将这些参数分别看作KCPSM的不同“虚拟端口”,为每个输出参数设定一个特定的PORT_ID。KCPSM输出数据后,TurboDec译码模块根据PORT_ID的数值判断当前OUT_PORT端输出的是什么参数。
可编程状态机 Turbo译码 嵌入式处理器IP核 相关文章:
- Windows CE 进程、线程和内存管理(11-09)
- RedHatLinux新手入门教程(5)(11-12)
- uClinux介绍(11-09)
- openwebmailV1.60安装教学(11-12)
- Linux嵌入式系统开发平台选型探讨(11-09)
- Windows CE 进程、线程和内存管理(二)(11-09)