基于FPGA的TD-LTE系统上行同步的实现
在LTE系统中,当进行随机接入eNB(网络端)和UE端建立上行同步之后,由于无线信道环境的改变需要进行时域和频率的同步调整,所以需要一种算法来完成定时同步的功能。OFDM符号定时同步的目的是找到CP和FFT的起始位置。因符号定时同步发生错误会导致符号间干扰,将影响到UE上行信道性能与容量。因此,性能良好的同步方法对于OFDM系统非常重要[1,2]。符号定时算法有很多,主要有数据辅助算法、非数据辅助盲算法和基于循环前缀的算法[3,4]。前两种算法相对于基于循环前缀的算法,实现难度大,而基于循环前缀算法的计算量比较大。本文为了能更好地完成定时同步,用FPGA的思想来简化最大似然 (ML)估计算法,并在此基础上进行一些算法的改进,利用Xilinx的Virtex-5芯片[5]作为硬件平台实现其算法,完成上行同步定时的功能,并应用到项目中。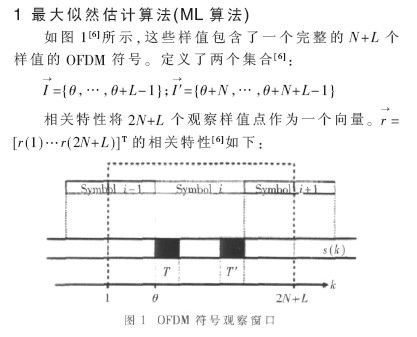


适用情况:适合高斯白噪声多径衰落或多普勒平移偏小的情况。
优缺点:算法简单,相对精确。但同时实现三个公式,对于硬件来说需要很多的乘法器,占用资源比较大,所需时间也比较长。
方案2:直接采用滑动相关的方法,实现公式(1)。由于绝对能量对相关能量的影响是一定的,而且数据有很好的相关性。因此,通过相关能量的运算,运用开方运算比较大小,能够找到相关能量最大值?酌(?兹)。
适用情况:信道环境和数据的相关性都特别好的情况下。
优缺点:算法简单、易实现,精准度和复杂度相对于方案1较小。但乘法器使用较多,完成所需要的时间比较长,占用资源比较大。
优缺点:算法简单、易实现、使用乘法器很少,占用资源相对较小,但精准度低于方案1。
从FPGA的速度和面积的角度考虑,方案3比较合理,既占用很少的资源,也能较快地实现同步。
3 FPGA实现的处理流程
3.1 整体流程
整体设计流程图如图2所示。数据由中频通过接口,经过接收和存储模块,进入乘法模块对360个数据操作,乘法器结果存储之后进入到求和模块,在求和模块中实现160个160点求和,经过开方和比较模块找到最大值max。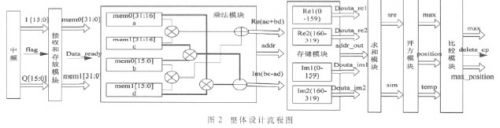
3.2 模块的解析
(1)接收和存放模块
数据从中频分I、Q两路数据输出,接收模块采用2片32 bit寄存器组存放。mem0[31:16]存放0~159的实部,mem0[15:0]存放0~159的虚部。mem1[31:16]存放2 048~2 207的实部,mem1[15:0]存放2 048~2 207的虚部。
(2)乘法模块
图2中,a对应的是0~159的实部,b对应的是0~159的虚部,c对应的是2 048~2 207的实部,d对应的是2 048~2 207的虚部。乘法模块实现了一个复数的相乘。一对共轭复数需要4个乘法器(a+bj)×(c-dj)=(ac+bd)+(bc-ad)j。由于需要320个复数对应相乘,为了更快地完成同步,同时又要考虑资源的情况,一次采用多少乘法器,需要根据后面的测试和评估情况做出选择。在权衡资源与速度后,本设计一次使用20个乘法器。
(3)存储模块
存储模块的作用是把上一个模块数据相乘后的320数据存储起来。为了方便后面求和模块的取值,此处采用了4个RAM。图2中,Re1存放乘法模块输出的0~159的实部,Re2存放乘法模块输出的160~319的实部,Im1存放乘法模块输出的0~159的虚部,Im2存放乘法模块输出的160~319的虚部。对应的RAM 的输入和输出地址是根据程序中标志位来控制的,对应的RAM 的输入值与采用乘法器的个数有关,采用多个乘法器时输入值采用位拼接的方式存入输入端。当给出输出端地址时,读出的数据也是很多个数据的位拼接,对应取出需要的位数即可。
(4)求和模块
由于未采用滑动相关的方案,所以需要对得出的数据进行加减,才能完成滑动相关求和的过程。滑动次数为0及滑动次数为1时,乘法器的数据相乘部分有159个数据是重复相乘。所以可以采用sre=sum_re+re2[0]-re1[0]求和。其中,sre相对于滑动一次的实部数据和,sum_re是未滑动数据的实部和,re2[0]是第160个实部(已完成了ad+bc即是一个复数和对应的复数相乘后的实部), re1[0]是第0个实部(已完成了ad+bc是一个复数和对应的复数相乘后的虚部)。对应的虚部也是这样操作。实部和虚部分别需要完成160次,即:

(6)比较模块
比较由开方模块出来的max和temp出来的数据大小,找出对应的位置max_position输出delete_cp信号,为后面数据送到CP、FFT模块做指示。
4 FPGA实现结果及分析
图3是FPGA设计的仿真图,max_position是用ML算法找到的最大值,即为CP的起始位置值。delete_cp为标志位,是为了给后面数据输送到CP模块、FFT模块的开始标志。仿真程序中设置了同步的噪声为33个,max_position的值是33。仿真中,噪声设为任意一个小于160的数X,max_position的值是X。说明ML算法在数据相关性很好的情况下,能准确地实现同步。图4是连接项目板子后,用Xilinx ISE10.1中的ChipScope Pro采集到的图样。ChipScope Pro主要是在板级调试过程中,观察FPGA芯片内部的信号。可以看出max_position的值是50,之所以和仿真图的值不一样,因为这个数据是真实的数据。基于ML算法,可以通过板级调试,成功地实现定时同步。图5是联机调试(FPGA、DSP与协议栈一起调试)中用Agilent的示波器采集到的波形。B1总线值为50(即max_position的值)。数字线14中的信号代表delete_cp信号。可以看出,图5采集到的信号和图4的一样,证明在联机调试中,能够成功实现同步。从图3、4、5中观察到的现象看,方案3的设计能正确实现ML算法,能够准确地实现上行同步。
ML算法的程序已通过Xilinx ISE10.1[6]的编译、仿真验证、板级验证和联机验证。其结果和理论值一致,可以精确到LTE系统要求。该算法满足了硬件对算法的模块化、规则化的要求,因此,它可以充分发挥硬件的优势,利用硬件的资源和速度,从而实现硬件与算法相结合的一种优化方案。在FPGA设计中,使速度与面积达到了很好的平衡,主要体现在乘法模块。此外,在实现过程中采取了一次做20次乘法的方案,使整个同步的过程完成只需要1 000多个周期,时间比较短,且占用资源很小(Slice LUT=7%)。由于该算法的FPGA实现在这个项目的联机调试中,性能稳定,所以该算法的FPGA实现已经应用到国家科技重大专项项目“TD-LTE无线终端综合测试仪表”开发中。
- TD-LTE综合测试仪表关键模块的研究与实现(06-05)
- DSP48E Slice(06-06)
- RocketIO GTX 收发器(06-06)
- PowerPC 440 处理器模块(06-06)
- DIY你的体感游戏:人体动作识别系统的设计,提供软硬件实现方案(06-04)
- 如何通过Virtex-5系统监控器加强系统管理和诊断?(12-20)