基于FPGA的活套高度和张力系统解耦控制器设计
热连轧系统大多采用活套装置,通过其缓冲作用来吸收咬钢过程中形成的套量,并保持恒定的小张力控制.在实际应用中,张力的设定值既不能过大,也不可以过小.张力过大对带材品质有影响;张力过小会使活套系统不稳定,不利于稳定轧制.
传统的活套控制是通过调整上游机架轧辊速度使活套高度维持在设定值附近,通过控制活套电机力矩使机架间张力恒定.在这种控制策略中,活套高度与张力控制是完全独立进行的,没有考虑二者之间存在的耦合关系.而实际情况是活套高度变化时,机架间张力也发生变化,反之亦然.即活套高度与张力系统是一个典型的双输入,双输出耦合系统.此外,活套控制系统还与其他控制系统(如AGC系统、机架间的喷水系统)之间存在着相互作用,这使得活套控制比较复杂消除耦合关系,使活套稳定工作.提高产品的尺寸精度,已成为活套控制的一个重要课题.
为了实现活套高度与张力系统解耦控制,需建立其动态数学模型.在鞍钢1700热轧厂,对F3,F4机架间活套耦合系统建模,选用FPGA器件进行了基于BP神经网络比例、积分、微分参数自学习的PID控制器的设计,为先进的控制策略在热轧现场应用奠定了基础.
1 系统建模
活套系统是非线性、时变的,要想获取其精确的数学模型是不可能的.在过程控制中,大多数使用线性时不变模型来描述.当过程偏离平衡点的变化很小时,控制系统的动态行为就可以用线性时不变模型来描述.这样可避免大量非线性方程联解的困难,即完成对非线性系统线性化处理.这里只考虑F3压下、F4不动作时对系统建模.
1.1 活套张力系统建模
张力增量方程为 
1.2 活套高度系统建模
由于活套臂的动作,产生角加速度,即当活套处于动作过程中,除了承受张力矩MT、重力矩外MW、活套电机实际上还将承受一个动力矩,打破原有的平衡关系,使张力矩发生变化.由于实际的活套机构有减速装置,传动比为GR,电机转速为n,则整个活套电机输出力矩为: 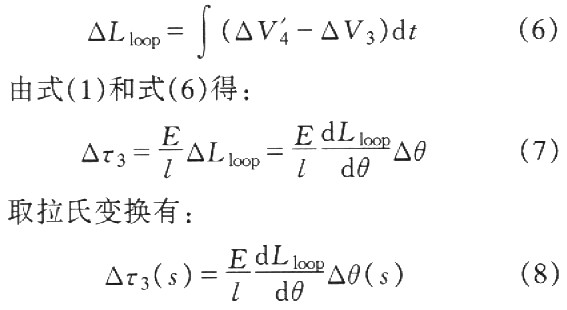
将主电机与活套电机近似为一阶惯性环节,由式(5)和(13)得到系统的耦合框图1.
活套高度和张力的工作点取为:活套臂升角θ=21°,张应力τ3=4.8N·mm-2,弹性模量E=150N·mm-2,机架间距l=6m,活套器支点与F3的距离la=2.2m,活套臂交点离轧制线的距离ha=0.18m,活套臂全长R=O.796m,活套辊半径r=O.11m,传动比GR=14:1;f3,Ti,Tv,Ki分别为0.082,0.18,0.09,8.25;J=7.85kg·m2;V03,V04分别为3.246m·s-1,4.786 m·s-1:F3机架入口厚度为H=9.44mm,出口厚度为h=5.69mm,工作辊半径R1=0.332m;α,β为F3,F4板带出口、入口与轧制线的角度,在线性工作点(θ,τ3)处线性化处理,相应的非线性函数是: 
式中,B为板宽,γ为中性角,ε为相对变形程度,K为金属变形阻力,τf为前张应力,τb为后张应力.
可得到: 


应该指出线性化后所得到的传递函数是被控对象的近似数学模型,系数是慢时变的,可作为解耦控制器(经典传函、奈氏方法等)的设计依据.对于绝大多数情况来说,解耦器的增益不应该是常数.如果要达到最优化,则解耦器必须是非线性的,甚至是适应性的.如果解耦器是线性和定常的,那么可以预料解耦将不完善.在某些情况下解耦器的误差可能引起不稳定.文中采用BP神经网络整定的PID解耦控制器,进行了仿真研究,具体算法见文献.
2 BP-PID在FPGA上的设计
在构造实际的神经网络应用系统时,必然要考虑到硬件实现问题,特定应用下的高性能专用神经网络硬件是神经网络研究的最终目标.为此选用FPGA器件进行这项工作,采用数据驱动的脉动阵列并行处理方式,进行了由13个神经元组成的三层(4-6-3)电路设计.由于电原理图设计很直观,因此在顶层采用了电原理图的设计方式,而功能模块则采用VHDL,描述方式进行设计.
基于上述方法,对于三层BP前馈神经网络硬件设计的系统总体框图见图2. 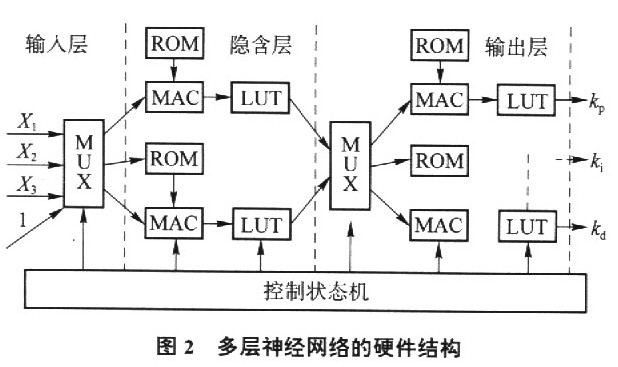
在图2中,X1,X2,X3是神经网络的输入,对应于r(k),y(k),e(k),Y1,Y2,Y3对应于PID控制器的三个可调参数kp,ki,kd ROM模块存储的是每一神经元对应的权值向量(整个神经网络共需对42个权值修正);MAC是神经元的乘累加模块;LUT是作用函数查找表模块;MUX是多路选通器,负责数据流的扇入扇出.从神经元的数学模型可以看出,其最基本也是最复杂的运算为权值与输入的乘累加运算.脉动阵列结构(Systolic结构)是一种有节奏地计算并通过系统传输数据的处理单元网络.Systolic结构的优势在于它可以用流水线的方式实现矩阵向量乘法,因此这种结构非常适合神经网络的实现;同时,由于其具有模块化及规则化的特征,非常适合用数字VLSI实现为了便于在硬件上实现,考虑到运算复杂度和速度,使用定点格式的数据,一般来说,16位的定点数是不消弱神经网络能力的最小要求.其他需要说明的是:对于前馈多层网络,只用于前向传播所需的数据精度一般可小于后向传播所需的精度;采用常用的Wallace树乘法器,其计算速度快,占用面积小;对于FPCA硬件来说,其可实现的运算极为有限,而BP网络中的作用函数是非线性的,是硬件实现的一个难点,例如BP网络中的作用函数为Sigmoid函数;常用的实现方法是查表法,这种方法比较简单,但需要占用较多资源,当需要实现的网络规模较大且精度要求较高时,查表法的实现有很大障碍;其他可以考虑的实现方法是用多项式去逼近这一非线性函数在硬件实现中,考虑到Sigmoid函数在输入大于一定数值后即进入饱和区的特点,只对原点附近的函数值进行存储,可节约大量资源并简化问题,其工作效果与非查表方式实现的仿真软件很接近.神经网络硬件实现的优势主要是速度快,尤其当运算量大时,其优越性才能体现出来.在实时控制中,特别是在高速轧制过程中,先进的控制算法其运算的快速性是尤为重要的,是在工业控制中能够应用的前提学习算法的硬件实现面临着两个难题,一是数据流控制复杂,二是数据精度对收敛性的影响.关于数据精度对收敛性的影响,为简化起见,评价函数选择为误差的平方和.
活套系统 解耦控制 数据精度 脉动阵列 FGPA 相关文章:
- FAE讲堂:利用赛灵思FGPA实现降采样FIR滤波器(05-06)
- Windows CE 进程、线程和内存管理(11-09)
- RedHatLinux新手入门教程(5)(11-12)
- uClinux介绍(11-09)
- openwebmailV1.60安装教学(11-12)
- Linux嵌入式系统开发平台选型探讨(11-09)