基于DM642DSP的视频编码优化方法
,那么在频繁的配置EDMA通道参数上就耗费了过多的CPU周期。有限的片内存储空间,制约着不能一次搬太多的宏块,一般一次搬7--9个宏块为宜。由于EDMA的同步信息是由CPU发出的,我们自然想到QDMA,但QDMA适用于单个的,独立的快速搬移数据,对于这种周期性的,重复性的搬移并没有优势。
为了提高EDMA的效率,可以采用EDMA链,最多开辟12个EDMA通道,让其首尾相连,这样只需触发一次CPU,可将待编码的亮度块色度块,参考帧的亮度块和色度块……一次搬完,如图2所示。在配置EDMA通道时,我们注意到频繁更换的只是EDMA的源地址和目的地址,而其它参量是不变的。由于EDMA控制器是基于RAM结构的,每个通道是通过参数表来配置的,每一个通道的参数都可以在0x01A0000h~0x01A07ffh的2KB的配置表中找到自己固定的位置,所以在更新某一通道的源地址和目的地址时,直接往配置表写上新地址就行了,而不必调用CSL库中的相应的cache函数来修改源地址和目的地址。

图2 EDMA链示意图
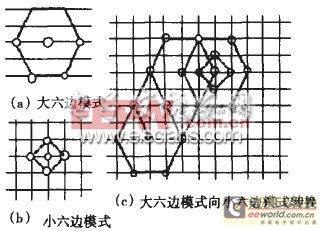
图3 六边形搜索算法
快速运动算法的优化
包括MPEG2,MPEG4和H.261、H.263、H264在内的标准都是采取基于块的运动估计模型。当然不同的标准块的大小也不一样,在H.264标准中,支持七种块大小(16x16、16x8、8x16、8x8、8x4、4x8、4x4)。众所周知:运动估计对减少时间域的冗余起了很大的作用,从而能大大提高编码效率,但同时它的计算量特别大,占用了大概整个编码系统的70%~80%的资源。一个好的编码算法就是要在计算量和编码效率两者之间取得一个很好的平衡。
全搜索(FS)能够保证在全局范围内搜到一个最佳的位置,但是其计算量是惊人的。对于在嵌入式系统中应用是不现实的。一般在实际应用中都是把几种算法结合起来,在本系统中采取的是:六边形搜索法,如图3所示,先以预测点为中心进行大模式搜索,如果最优点不在六边形中心,则将六边形的中心移至改点,重复大模式搜索,直到最优点在六边形中点,然后在这点切换到小模式搜索,此搜索法相对于经典的三步法,四步法搜索的点更少。
由于是在DSP平台上,对监控系统实时性要求比较高,提出几种基于DSP平台的优化方法:为了提高L1D的cache的命中率,根据cache不命中流水的原理,一次将参考帧全部灌入L1D内,然后在做运动估计时将七个宏块一齐做,然后再做七个宏块的运动补偿,DCT,量化,反DCT,反量化,编码,写码流。而不是像一般的步骤,对每一个宏块先做运动估计,然后运动补偿,然后DCT,映射到L1D一次,如果每个宏块单独做,在做第一个宏块运动估计时参考帧会由L2映射到L1D,做第二次运动估计时,因为之前程序做过DCT,量化等运算,映射到L1D里的参考帧数据已经被冲走,还得从L2中重新载入。同样的对于程序段一级缓存L1P来说,DCT、量化、反DCT、反量化、编码、写码流等函数都只需映射一次到L1P,而不必被反复地映射,冲掉,再次映射。
在JVT的提案中有很多运动矢量预测算法,如利用运动矢量在时间域有很强的相关性这一特性,我们能够得到比较精确的起始搜索位置。但他不太适合DSP平台,因为这样我们就要保留整个一帧的运动矢量,以CIF图像格式为例,需要12kB的空间,保存在资源紧张的片内显然是不合适的。保存在片外存储空间,调用的时候,先从片外先映射到L2cache,再从L2映射到L1D,其间流水不命中等待的cycle数,还不如从开始不太精确的初始位置多搜几个点。
整数DCT的优化详解
DCT,量化,反DCT,反量化在整个编码程序中占用了大概20%~25%的时间,所以有必要对他们的优化花一番功夫,本文举整数DCT为例说明如何对程序进行汇编级的优化。H.264采用的整数DCT,不仅满足一般DCT的特性,将图像的能量集中到左上角位置,直流系数和低频系数中,还有它特有的几个优点:
-它是整数变换,所有的运算都是整数算法,变换矩阵系数十分简单,核心变换部分可以仅仅用加法 法和移位来实现。非常有利于在DSP实现。
-可以保证编码端的变换和解码端的反变换完全匹配,没有误差。
首先我们对变换矩阵做必要的调整,如表达式(1),(2)所示,这样做的好处是行变换和列变换的操作完全一样,简化了运算。接下来就是用线性汇编或纯汇编来实现两个矩阵的相乘。

因为DM642CPU有两个类似的可进行数据处理的通路A和B,每个通路有4个完全相同的运算单元(.L,.S,.M,.D)我们可将矩阵的一四两行的运算放在A侧进行,二三两行在B侧进行运算,这样可以保证A,B两侧可同时并行计算。由于整数DCT变换是在16比特精度下完成的,矩阵相乘我们自然会想到汇编指令DOTP2,但是不能全部用DOTP2来完成运算,否则一个
- 视频编码讲坛之H.264前世今生(05-18)
- 新一代视频编码标准H.264/AVC的关键技术研究(09-04)
- 视频编码标准应用或改国内监控产业格局(12-06)
- 如何使用FPGA实现高清低码流视频编码(09-28)
- H.264_AVC视频编码变换量化核实现(07-23)
- H.264/AVC视频编码变换量化核的硬件设计(01-10)