车载后视场景分布式视频监控系统
时间:04-14
来源:互联网
点击:
引言
据媒体报道,我国由于后视镜盲区造成的交通事故约占30%。而且,随着“考驾照”热不降温的现象出现,未来的汽车后视镜盲区问题更是不容小觑。数字社会的形成为数字化实时监控提供了契机,汽车后视场景的数字化实时监控成为解决后视镜盲区问题的研究热点。
目前,市场上已经出现了一些数字化的汽车监控系统,常见的有分屏显示的监控系统、有缝拼接的监控系统和第8代“卫星”全景行车安全系统。分屏显示的监控系统只是对图像进行简单的分屏显示,不能实时地将车辆周围的景象显示在屏幕上;有缝拼接的监控系统不是将图像简单地叠加,而是对图像拼接处理,形成中间是车子,周围是图像的全景图,缺点在于四个图像拼接之处存在明显的拼接缝;第8代“卫星”全景行车安全系统采用超广角摄像头,它能够更好地消除图像拼接之处的拼接缝,形成汽车全景俯视图。
Android系统具有平台开放性,而且谷歌的“开放汽车联盟(OAA)”致力于实现汽车与Android设备的无缝连接以及直接在汽车上内置Android车载系统;DM3730
集成了1GHz的ARM Cortex-A8核和800MHz的TMS320C64x+ DSP核,DSP在数字信号处理上具有无可比拟的优势,更适合进行图像处理。因此,基于Android和DM3730设计的车载分布式视频监控系统有着广阔的应用前景。
车载分布式视频监控系统集成了Android平台的开放性、ARM+DSP的高性能、以太网的可扩展性和USB摄像头的即插即用性,对实现汽车数字化实时监控有研究意义和应用价值。
1系统的整体设计
车载分布式视频监控系统由视频采集模块、视频传输模块、视频拼接模块和视频显示模块四个模块组成。图1展示了系统的整体设计,图2展示了系统各模块之间的硬件接口。
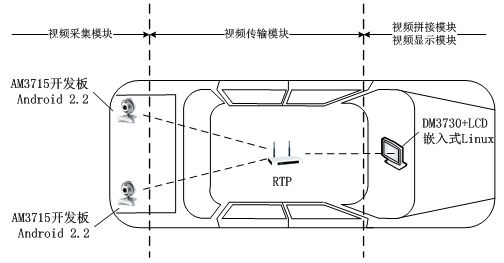
图1 车载分布式视频监控系统整体设计示意图
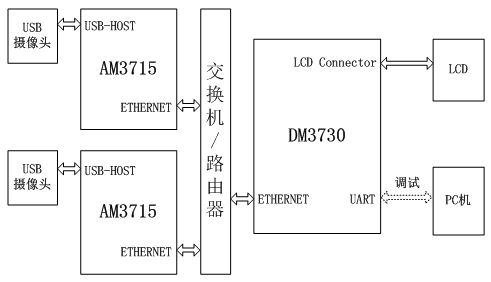
图2 车载分布式视频监控系统硬件接口框图
① 视频采集模块:AM3715开发板通过USB-HOST接口外接USB摄像头,通过Android操作系统的Java本地调用接口[3](JNI)和V4L2 (video 4 linux 2)视频驱动框架实时采集视频并显示。
② 视频传输模块:两个(或多个)AM3715和DM3730开发板之间通过以太网相连,利用RTP组播协议和自定义同步机制将USB摄像头采集的图像实时传输至DM3730开发板的ARM端。
③ 视频拼接模块:DM3730开发板的ARM端运行嵌入式Linux操作系统(或Android操作系统),通过TI Codec Engine模块同时在ARM端和DSP端映射共享内存,使得同步接收的两幅(或多幅)图像能够被ARM和DSP同时访问。针对车载应用扩充嵌入式计算视觉库(EMCV),并移植和优化SURF开源项目OpenSURF,DSP端能够实时拼接两幅(或多幅)图像,最后将拼接结果由共享内存返回ARM端。
④ 视频显示模块:视频显示是通过跨平台多媒体库SDL(Simple DirectMedia Layer)来完成的。其中,AM3715开发板显示分离的USB摄像头图像,DM3730开发板显示拼接完成的图像。
2 视频采集传输和显示
2.1 Android V4L2视频采集模块
V4L2从Linux 2.5.x版本的内核开始出现,为使能UVC驱动和V4L2编程框架,首先需检查Android内核配置选项,以生成视频设备文件/dev/videoX(X表示次设备号)。
利用V4L2进行USB摄像头视频采集的流程[7]包括:(1)打开视频设备文件;(2)检查设备属性;(3)设置视频格式;(4)帧缓冲区管理;(5)循环采集视频;(6)关闭视频设备。
V4L2介于应用程序和硬件设备之间,应用程序可以通过三种方式访问内核层的数据:直接读/写方式、内存映射方式和用户指针方式。直接读/写方式需要在用户空间和内核空间不断拷贝数据,效率低下;内存映射方式把内核地址映射到用户地址空间,进程可以直接读写内存,避免了数据的拷贝,具有较高的效率;用户指针方式的内存片段是由应用程序自己分配的。
车载分布式视频监控系统采用效率较高的内存映射方式,系统调用mmap()能够将内核地址映射到用户地址空间。
2.2 RTP视频传输模块
鉴于以太网具有高速的传输能力和良好的可扩展性能,车载分布式视频监控系统通过RTP组播的方式在Android系统与嵌入式Linux系统之间传输USB摄像头采集的图像。文献[8]描述了利用RTP库JRTPLIB实现视频实时传输的过程。为了确保两个AM3715开发板与DM3730开发板之间图像传输的同步性,车载分布式视频监控系统设计了同步传输协议,协议描述如下:
(1)发送端
① 每个发送端等待来自接收端的视频帧请求命令’R’,否则不执行发送操作。
② 收到帧请求命令后,发送端首先向组播地址发送视频帧传输开始标识0xFE,以标识一帧视频传输的开始。
③ 将YUY2格式的图像依次向组播地址传输,每次传输m行,传输n次,并在每个RTP数据包的首字节位置添加RTP包传输序号(序号从0开始,依次增1)。假设YUY2图像宽度为width,高度为height,由于平均一个像素占2B,所以每次传输的RTP包数据大小为(2m*width+1)B,传输次数n = height/m。
④ 传输结束时,向组播地址发送视频帧传输结束标识0xFF,以标志一帧视频传输的结束。
(2)接收端
① 接收端向组播地址发送帧请求命令’R’,然后启动软件电子狗,并处于阻塞等待状态。
② 若软件电子狗计时结束时仍未被喂狗,说明网络通信出现故障,重新向组播地址发送帧请求命令’R’,并重启软件电子狗。
③ 依次接收来自每个发送端的RTP数据包,并根据IP地址和RTP包传输序号还原每帧视频,直至收到视频帧传输结束标识0xFF。
2.3 SDL视频显示模块
YUV格式在存储方式上分为打包格式(Packed Format)和平面格式(Planner Format),打包格式的Y、U、V三个分量连续交叉存储,而平面格式的Y、U、V三个分量分开存储。实验中USB摄像头采集的图像格式是YUY2格式,而经过拼接完成的图像是YV12格式。YUY2格式是一种打包格式,以4:2:2方式打包,每个像素保留Y分量,而UV分量在水平方向上的采样率仅为Y分量的1/2,即存储顺序为[Y0 U0 Y1 V0] [Y2 U2 Y3 V2] ……[Y2n U2n Y2n+1 V2n]。YV12是一种平面格式,UV分量在水平方向和垂直方向上的采样率均为Y分量的1/2。特殊地,YV12格式在UV提取时,需先将图像划分为若干个2 x 2的方阵,然后在每个方阵上提取一个U分量和一个V分量。例如,对于6x4的图像,YV12的采样方式如下图所示,其存储顺序为[Y0 Y1 Y2 Y3 Y4 Y5 Y6 Y7 Y8 Y9 Y10 Y11 Y12 Y13 Y14 Y15 Y16 Y17 Y18 Y19 Y20 Y21 Y22 Y23] [U0 U1 U2 U3 U4 U5] [V0 V1 V2 V3 V4 V5 V6]。
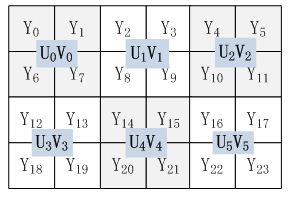
YV12采样方式示意图
SDL支持FrameBuffer,利用SDL可以在Android和Linux上直接显示YUY2和YV12格式的图像,不需要经过YUV格式到RGB格式的转换。不同的是,标准Linux的FrameBuffer设备文件为/dev/fb0,而Android Linux的FrameBuffer设备文件是/dev/graphics/fb0。利用SDL显示YUV格式图像的流程包括:(1)初始化视频设备;(2)设置视频显示模式;(3)创建YUV覆盖层;(4)轮询事件处理;(5)绘制YUV覆盖层;(6)显示YUV覆盖层;(7)释放YUV覆盖层;(8)退出SDL。
3 ARM+DSP双核视频拼接模块
3.1 Codec Engine双核通信设计
Codec Engine是ARM和DSP通信的桥梁,采用远程过程调用(RPC)的思想。ARM端作为客户端,DSP端作为服务器端,ARM和DSP之间的通信链路是共享内存,通信协议是DSP Link。Codec Engine有专门的内存管理驱动CMEM来管理ARM和DSP之间的共享内存,CMEM以内存池或内存堆的方式管理一个或者多个连续的物理块内存并提供地址转换(虚拟地址和物理地址之间的转换)功能。
Codec Engine有核心引擎接口和VISA接口。核心引擎接口包括引擎的初始化接口、引擎运行状态的控制接口和内存的系统抽象层接口;VISA接口包括视频编/解码接口、音频编/解码接口、图像编/解码接口和语音编/解码接口。VISA接口的使用分为VISA创建、VISA控制、VISA处理和VISA删除四部分,图3展示了通过VISA控制/处理的流程。
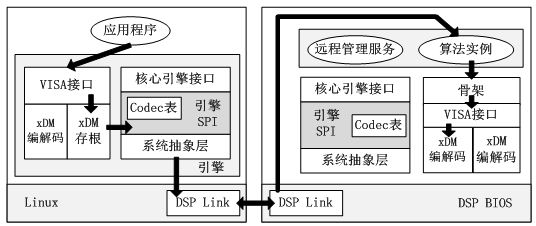
图3 VISA 控制/处理示意图
Codec Engine的使用分为创建应用程序、实现Codec算法和集成Codec Server三部分。应用程序运行在ARM端,通过调用核心引擎接口和VISA接口与DSP进行通信;对于符合XDM(eXpressDSP Digital Media)规范的Codec算法,Codec Engine的VISA接口不需要附加条件就能支持远端运行,对于符合XDAIS(eXpressDSP Algorithm Interface Standard)规范的非XDM算法,必须提供Codec Engine的存根和骨架中间件才能支持远端运行;Codec Server运行在DSP端,负责管理调度不同的Codec算法。
车载分布式视频监控系统接收端使用视频编码接口(VIDENC_)实现ARM端调用DSP端基于SURF的图像拼接算法。应用程序的执行流程如图4所示。
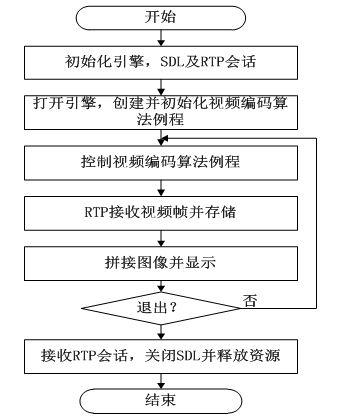
图4 车载分布式视频监控系统接收端应用程序流程图
3.2基于SURF的视频拼接
系统采用SURF算法检测特征点和描述特征点。SURF具有尺度和旋转不变性,对光照和视点变换具有不错的鲁棒性,并且经过优化后可以满足实时性要求。根据特征点之间的欧氏距离进行粗匹配,使用RANSAC(随机一致性)方法去除错匹配点,计算图像之间的透视变换矩阵,最终采用渐入渐出平均法融合图像。
针对本系统,可以对算法进行进一步的优化,提高系统的实时性。由于系统中摄像头的位置相对固定,因而可以预先计算图像之间的重叠位置,不需检测完全没有图像重叠的区域;同时,由于摄像头相对位置不变,图像之间的透视变化矩阵不会变化,因此可以只计算一次透视变化矩阵,后续拼接使用第一次的透视变化矩阵,可进一步提高实时性。
(1)SURF特征点检测
SURF特征点检测是在尺度空间中进行的,并使用Hessian矩阵行列式值检测特征点,尺度为σ的点X(x,y)的Hessian矩阵H(X,σ)定义如式(3-1),其中Lxx (X,σ),Lxy (X,σ),Lyy (X,σ)为在尺度σ下的高斯函数的二阶偏导数在图像点X处的卷积。

SURF使用基于积分图的盒型滤波器(box filter)近似此高斯卷积过程,图3-2所示为9*9盒型滤波器对分别对x,y,xy方向的二维高斯滤波的近似。通过近似,将在点X(x,y)的二维高斯卷积转化为对其周围的加权计算过程,在此加权计算过程中,使用积分图计算图3-2中黑色矩形区域和白色矩形区域灰度值之和,将高斯滤波中的大量的乘法运算转换为简单的加减运算。
设对x,y,xy方向的二维高斯卷积的近似分别用Dxx,Dyy,Dxy表示,则可以通过式(3-2)近似Hessian矩阵H(X,σ)行列式值,其中w通常取0.9。当Det(H(X,σ))>0时,Dxx>0时,点X(x,y)为局部极小值点;Dxxxx*Dyy-(w*Dxy)2 (3-2)
(2)SURF特征点描述
特征点描述主要分两步:第一步是获取特征点的主方向,主要目的是为了保证旋转不变性。第二步是生成64维的特征点描述符,主要目的是描述特征点的特征。
为了获取特征点的主方向,计算以特征点为中心,半径为6σ(σ为特征点所在的尺度)内的所有点在x,y方向的Harr小波响应。并选取一个大小为60度的扇形窗口旋转整个圆形区域,将窗口内所有x,y方向的响应值相加得到一个新矢量,最终以最长的矢量所在的方向作为特征点的主方向。
特征点描述需要将坐标轴旋转到主方向上,并将以特征点为中心的边长为20σ的区域划分为4×4个子窗口,每个子窗口分为5×5个采样点,计算每个采样点的沿主方向和垂直主方向的Harr小波响应,记为d_x和d_y,最终生成一个4维矢量v=(∑dx,∑dy ,∑|dx|,∑|dy|),并将其归一化。总共4×4个子窗口,生成64维的描述符。
3.3 SURF在DM3730上的移植和优化
(1)SURF的移植
SURF算法实现基于OpenCV1.0,OpenCV库针对x86架构作了许多优化,在DSP上的执行效率难以得到保证。EMCV是一个可运行在DSP上的OpenCV库,但只实现了部分OpenCV的数据结构和库函数。因此,车载分布式视频监控系统需要扩充EMCV库,以支持SURF在DM3730上的运行。扩充的库函数包括:cvAdd、cvAddWeighted、cvConvertScale、cvCvtColor、cvGEMM、cvInvert、cvMerge、cvResetImageROI、cvResize、cvSVD、cvSetImageROI、cvSplit、cvWarpPerspective。
为了便于EMCV库的扩充和优化,EMCV库通过CCS(Code Composer Studio)软件以lib静态库的形式提供给Codec算法使用,如下所示:
[package.bld]
packageti.sdo.ce.examples.codecs.videnc_mosaic.emcv{
}
[package.xs]
functiongetLibs(prog){
var name = null;
if (prog.build.target.isa == "64P") {
var name = "emcv.lib";
print(" will link with " + this.$name + ":" + name);
}
return (name);
}
此外,为了消除SURF对C++标准模板库的依赖,车载分布式视频监控系统设计了专门的容器结构和相应的操作,主要代码如下:
typedefstruct _Vector{
void *pdata; // 数据块首地址
int count; // 数据块元素数目
int size; // 数据块已用大小
int totalSize; // 数据块总大小
}Vector;
#define PRE_CALLOC_SIZE 20 // 预分配元素个数
/* 添加nElem个元素,每个元素大小elSize */
intvector_pushback( Vector *pVector, intnElem, intelSize ){
int n = nElem> PRE_CALLOC_SIZE? nElem:PRE_CALLOC_SIZE;
if(pVector->size + nElem*elSizetotalSize ){
pVector->size += nElem*elSize;
pVector->count += nElem;
return 0;
}else{ // 预分配的内存不足,需重新分配内存
pVector->totalSize += n*elSize;
void *pNewData = (void*)realloc( pVector->pdata, pVector->totalSize );
if(pNewData ){
pVector->pdata = pNewData;
pVector->size += nElem*elSize;
pVector->count += nElem;
return 0;
}else{ // 内存分配失败
return -1;
}
}
}
/* 销毁容器,释放内存 */
voidvector_destroy( Vector*pVector ){
if(pVector->pdata ){
free(pVector->pdata );
pVector->pdata = NULL;
}
pVector->size = pVector->count = pVector->totalSize = 0;
}
(2)SURF在DM3730上的优化
SURF在DM3730上的优化分为项目级优化、指令级优化和缓存优化三个方面。项目级优化是通过合理地选择和配置相关的编译器优化选项,主要包括:调试模式选项(Debugging Model)、优化等级选项(opt_level)、代码大小选项(opt_for_sapce)、代码速度选项(opt_for_speed)、程序级优化(-op)等。为了最大限度地提高代码的执行效率,车载分布式视频监控系统选择的编译器优化选项为-o3、-ms0、-mf5、-op2、-mt、-mh、-mw。指令级优化包括选择合适的数据类型,消除指令和数据之间的相关性,使用内联(intrinsic)函数以及改善软件流水等。缓存优化是将CPU近期访问过的数据或者程序放置在Cache中,以提高CPU的执行速度。
4 测试结果及分析
图6展示了车载分布式视频监控系统的拼接效果,表1比较了SURF和SIFT算法在DM3730和PC机上的拼接效率。从拼接效果可以看出,车载分布式视频监控系统能适应图像的平移、旋转和缩放等特性。图6中的两幅待拼接的图像存在明显的旋转特性,并且拼接完成的图像有一定的缩放效果。从表1中可以看出,车载分布式视频监控系统在视频采集、视频传输和视频显示上总耗时约为257ms,远远小于视频拼接所需时间3264ms。这是由于视频拼接模块使用了许多EMCV和OpenCV库函数,它们在DM3730处理器上还有待进一步被优化。作为SIFT算法的加速版,SURF算法的执行效率要远远大于SIFT算法的执行效率。从本次测试结果看,在DM3730上,SURF算法的执行效率是SIFT算法执行效率的3.68倍左右;而在以Intel Core2 Duo T5870为处理器的PC机上,SURF算法的执行效率是SIFT算法执行效率的1.40倍左右。
在摄像头相对位置固定情况下,图像之间的透视变化矩阵固定,因此只需计算一次透视变化矩阵,后续的图像拼接只需进行图像配准和融合。表2中列出了DM3730上SURF算法的时间组成,其中SURF算法透视变换矩阵计算时间占95%以上,实际的图像拼接时间为图像配准和如何时间,平均时间约为66ms。

结语
本文从视频采集、视频传输、视频拼接和视频显示等四个方面详细阐述了基于Android和DM3730的汽车分布式视频监控系统的设计原理和优势。从测试结果看,车载分布式视频监控系统基本上能达到实时采集、实时传输、实时显示,经过优化后,图像拼接的效率基本能满足实时性要求,但系统整体性能还有待提高,可以采用多核处理器代替单核处理器,进一步提高系统的实时性。
参考文献
[1] Google launches the Android-based Open Automotive Alliance with Audi, Honda, GM, and more, The Verge, January 6, 2014.
[2] Instruments T. DM3730, DM3725 Digital Media Processors[R]. Tech. Rep. July, 2011.
[3] Lee Y H, Chandrian P, Li B. Efficient java native interface for android based mobile devices[C]//Trust, Security and Privacy in Computing and Communications (TrustCom), 2011 IEEE 10th International Conference on. IEEE, 2011: 1202-1209.
[4] 龚泽挚, 蓝晓柯, 郑雅羽. 基于 Android 和 DM3730 的视频编码软件开发[J]. 电视技术, 2013, 37(17): 76-79.
[5] 胡楠. EMCV 库扩充及车辆检测系统的嵌入式实现[D]. 大连海事大学, 2011.
[6] 于海. OpenSURF在TI DM642上的移植[J]. 电子科技, 2012, 25(5): 133-136.
[7] 王飞, 孔聪. 基于 V4L2 的 Linux 摄像头驱动的实现[J]. 电子科技, 2012, 25(2): 86-87.
[8] 赵学良. 基于 Android 的流媒体引擎设计与实现[D]. 电子科技大学, 2012.
[9] Bay H, Tuytelaars T, Van Gool L. Surf: Speeded up robust features[M]//Computer Vision–ECCV 2006. Springer Berlin Heidelberg, 2006: 404-417.
[10] 杨小辉, 王敏. 基于 ASIFT 的无缝图像拼接方法[J]. 计算机工程, 2013, 39(2): 241-244.
[11] 刘旭. 多图像全景拼接技术研究[D]. 武汉理工大学, 2012.
据媒体报道,我国由于后视镜盲区造成的交通事故约占30%。而且,随着“考驾照”热不降温的现象出现,未来的汽车后视镜盲区问题更是不容小觑。数字社会的形成为数字化实时监控提供了契机,汽车后视场景的数字化实时监控成为解决后视镜盲区问题的研究热点。
目前,市场上已经出现了一些数字化的汽车监控系统,常见的有分屏显示的监控系统、有缝拼接的监控系统和第8代“卫星”全景行车安全系统。分屏显示的监控系统只是对图像进行简单的分屏显示,不能实时地将车辆周围的景象显示在屏幕上;有缝拼接的监控系统不是将图像简单地叠加,而是对图像拼接处理,形成中间是车子,周围是图像的全景图,缺点在于四个图像拼接之处存在明显的拼接缝;第8代“卫星”全景行车安全系统采用超广角摄像头,它能够更好地消除图像拼接之处的拼接缝,形成汽车全景俯视图。
Android系统具有平台开放性,而且谷歌的“开放汽车联盟(OAA)”致力于实现汽车与Android设备的无缝连接以及直接在汽车上内置Android车载系统;DM3730
集成了1GHz的ARM Cortex-A8核和800MHz的TMS320C64x+ DSP核,DSP在数字信号处理上具有无可比拟的优势,更适合进行图像处理。因此,基于Android和DM3730设计的车载分布式视频监控系统有着广阔的应用前景。
车载分布式视频监控系统集成了Android平台的开放性、ARM+DSP的高性能、以太网的可扩展性和USB摄像头的即插即用性,对实现汽车数字化实时监控有研究意义和应用价值。
1系统的整体设计
车载分布式视频监控系统由视频采集模块、视频传输模块、视频拼接模块和视频显示模块四个模块组成。图1展示了系统的整体设计,图2展示了系统各模块之间的硬件接口。
图1 车载分布式视频监控系统整体设计示意图
图2 车载分布式视频监控系统硬件接口框图
① 视频采集模块:AM3715开发板通过USB-HOST接口外接USB摄像头,通过Android操作系统的Java本地调用接口[3](JNI)和V4L2 (video 4 linux 2)视频驱动框架实时采集视频并显示。
② 视频传输模块:两个(或多个)AM3715和DM3730开发板之间通过以太网相连,利用RTP组播协议和自定义同步机制将USB摄像头采集的图像实时传输至DM3730开发板的ARM端。
③ 视频拼接模块:DM3730开发板的ARM端运行嵌入式Linux操作系统(或Android操作系统),通过TI Codec Engine模块同时在ARM端和DSP端映射共享内存,使得同步接收的两幅(或多幅)图像能够被ARM和DSP同时访问。针对车载应用扩充嵌入式计算视觉库(EMCV),并移植和优化SURF开源项目OpenSURF,DSP端能够实时拼接两幅(或多幅)图像,最后将拼接结果由共享内存返回ARM端。
④ 视频显示模块:视频显示是通过跨平台多媒体库SDL(Simple DirectMedia Layer)来完成的。其中,AM3715开发板显示分离的USB摄像头图像,DM3730开发板显示拼接完成的图像。
2 视频采集传输和显示
2.1 Android V4L2视频采集模块
V4L2从Linux 2.5.x版本的内核开始出现,为使能UVC驱动和V4L2编程框架,首先需检查Android内核配置选项,以生成视频设备文件/dev/videoX(X表示次设备号)。
利用V4L2进行USB摄像头视频采集的流程[7]包括:(1)打开视频设备文件;(2)检查设备属性;(3)设置视频格式;(4)帧缓冲区管理;(5)循环采集视频;(6)关闭视频设备。
V4L2介于应用程序和硬件设备之间,应用程序可以通过三种方式访问内核层的数据:直接读/写方式、内存映射方式和用户指针方式。直接读/写方式需要在用户空间和内核空间不断拷贝数据,效率低下;内存映射方式把内核地址映射到用户地址空间,进程可以直接读写内存,避免了数据的拷贝,具有较高的效率;用户指针方式的内存片段是由应用程序自己分配的。
车载分布式视频监控系统采用效率较高的内存映射方式,系统调用mmap()能够将内核地址映射到用户地址空间。
2.2 RTP视频传输模块
鉴于以太网具有高速的传输能力和良好的可扩展性能,车载分布式视频监控系统通过RTP组播的方式在Android系统与嵌入式Linux系统之间传输USB摄像头采集的图像。文献[8]描述了利用RTP库JRTPLIB实现视频实时传输的过程。为了确保两个AM3715开发板与DM3730开发板之间图像传输的同步性,车载分布式视频监控系统设计了同步传输协议,协议描述如下:
(1)发送端
① 每个发送端等待来自接收端的视频帧请求命令’R’,否则不执行发送操作。
② 收到帧请求命令后,发送端首先向组播地址发送视频帧传输开始标识0xFE,以标识一帧视频传输的开始。
③ 将YUY2格式的图像依次向组播地址传输,每次传输m行,传输n次,并在每个RTP数据包的首字节位置添加RTP包传输序号(序号从0开始,依次增1)。假设YUY2图像宽度为width,高度为height,由于平均一个像素占2B,所以每次传输的RTP包数据大小为(2m*width+1)B,传输次数n = height/m。
④ 传输结束时,向组播地址发送视频帧传输结束标识0xFF,以标志一帧视频传输的结束。
(2)接收端
① 接收端向组播地址发送帧请求命令’R’,然后启动软件电子狗,并处于阻塞等待状态。
② 若软件电子狗计时结束时仍未被喂狗,说明网络通信出现故障,重新向组播地址发送帧请求命令’R’,并重启软件电子狗。
③ 依次接收来自每个发送端的RTP数据包,并根据IP地址和RTP包传输序号还原每帧视频,直至收到视频帧传输结束标识0xFF。
2.3 SDL视频显示模块
YUV格式在存储方式上分为打包格式(Packed Format)和平面格式(Planner Format),打包格式的Y、U、V三个分量连续交叉存储,而平面格式的Y、U、V三个分量分开存储。实验中USB摄像头采集的图像格式是YUY2格式,而经过拼接完成的图像是YV12格式。YUY2格式是一种打包格式,以4:2:2方式打包,每个像素保留Y分量,而UV分量在水平方向上的采样率仅为Y分量的1/2,即存储顺序为[Y0 U0 Y1 V0] [Y2 U2 Y3 V2] ……[Y2n U2n Y2n+1 V2n]。YV12是一种平面格式,UV分量在水平方向和垂直方向上的采样率均为Y分量的1/2。特殊地,YV12格式在UV提取时,需先将图像划分为若干个2 x 2的方阵,然后在每个方阵上提取一个U分量和一个V分量。例如,对于6x4的图像,YV12的采样方式如下图所示,其存储顺序为[Y0 Y1 Y2 Y3 Y4 Y5 Y6 Y7 Y8 Y9 Y10 Y11 Y12 Y13 Y14 Y15 Y16 Y17 Y18 Y19 Y20 Y21 Y22 Y23] [U0 U1 U2 U3 U4 U5] [V0 V1 V2 V3 V4 V5 V6]。
YV12采样方式示意图
SDL支持FrameBuffer,利用SDL可以在Android和Linux上直接显示YUY2和YV12格式的图像,不需要经过YUV格式到RGB格式的转换。不同的是,标准Linux的FrameBuffer设备文件为/dev/fb0,而Android Linux的FrameBuffer设备文件是/dev/graphics/fb0。利用SDL显示YUV格式图像的流程包括:(1)初始化视频设备;(2)设置视频显示模式;(3)创建YUV覆盖层;(4)轮询事件处理;(5)绘制YUV覆盖层;(6)显示YUV覆盖层;(7)释放YUV覆盖层;(8)退出SDL。
3 ARM+DSP双核视频拼接模块
3.1 Codec Engine双核通信设计
Codec Engine是ARM和DSP通信的桥梁,采用远程过程调用(RPC)的思想。ARM端作为客户端,DSP端作为服务器端,ARM和DSP之间的通信链路是共享内存,通信协议是DSP Link。Codec Engine有专门的内存管理驱动CMEM来管理ARM和DSP之间的共享内存,CMEM以内存池或内存堆的方式管理一个或者多个连续的物理块内存并提供地址转换(虚拟地址和物理地址之间的转换)功能。
Codec Engine有核心引擎接口和VISA接口。核心引擎接口包括引擎的初始化接口、引擎运行状态的控制接口和内存的系统抽象层接口;VISA接口包括视频编/解码接口、音频编/解码接口、图像编/解码接口和语音编/解码接口。VISA接口的使用分为VISA创建、VISA控制、VISA处理和VISA删除四部分,图3展示了通过VISA控制/处理的流程。
图3 VISA 控制/处理示意图
Codec Engine的使用分为创建应用程序、实现Codec算法和集成Codec Server三部分。应用程序运行在ARM端,通过调用核心引擎接口和VISA接口与DSP进行通信;对于符合XDM(eXpressDSP Digital Media)规范的Codec算法,Codec Engine的VISA接口不需要附加条件就能支持远端运行,对于符合XDAIS(eXpressDSP Algorithm Interface Standard)规范的非XDM算法,必须提供Codec Engine的存根和骨架中间件才能支持远端运行;Codec Server运行在DSP端,负责管理调度不同的Codec算法。
车载分布式视频监控系统接收端使用视频编码接口(VIDENC_)实现ARM端调用DSP端基于SURF的图像拼接算法。应用程序的执行流程如图4所示。
图4 车载分布式视频监控系统接收端应用程序流程图
3.2基于SURF的视频拼接
系统采用SURF算法检测特征点和描述特征点。SURF具有尺度和旋转不变性,对光照和视点变换具有不错的鲁棒性,并且经过优化后可以满足实时性要求。根据特征点之间的欧氏距离进行粗匹配,使用RANSAC(随机一致性)方法去除错匹配点,计算图像之间的透视变换矩阵,最终采用渐入渐出平均法融合图像。
针对本系统,可以对算法进行进一步的优化,提高系统的实时性。由于系统中摄像头的位置相对固定,因而可以预先计算图像之间的重叠位置,不需检测完全没有图像重叠的区域;同时,由于摄像头相对位置不变,图像之间的透视变化矩阵不会变化,因此可以只计算一次透视变化矩阵,后续拼接使用第一次的透视变化矩阵,可进一步提高实时性。
(1)SURF特征点检测
SURF特征点检测是在尺度空间中进行的,并使用Hessian矩阵行列式值检测特征点,尺度为σ的点X(x,y)的Hessian矩阵H(X,σ)定义如式(3-1),其中Lxx (X,σ),Lxy (X,σ),Lyy (X,σ)为在尺度σ下的高斯函数的二阶偏导数在图像点X处的卷积。
SURF使用基于积分图的盒型滤波器(box filter)近似此高斯卷积过程,图3-2所示为9*9盒型滤波器对分别对x,y,xy方向的二维高斯滤波的近似。通过近似,将在点X(x,y)的二维高斯卷积转化为对其周围的加权计算过程,在此加权计算过程中,使用积分图计算图3-2中黑色矩形区域和白色矩形区域灰度值之和,将高斯滤波中的大量的乘法运算转换为简单的加减运算。
设对x,y,xy方向的二维高斯卷积的近似分别用Dxx,Dyy,Dxy表示,则可以通过式(3-2)近似Hessian矩阵H(X,σ)行列式值,其中w通常取0.9。当Det(H(X,σ))>0时,Dxx>0时,点X(x,y)为局部极小值点;Dxxxx*Dyy-(w*Dxy)2 (3-2)
(2)SURF特征点描述
特征点描述主要分两步:第一步是获取特征点的主方向,主要目的是为了保证旋转不变性。第二步是生成64维的特征点描述符,主要目的是描述特征点的特征。
为了获取特征点的主方向,计算以特征点为中心,半径为6σ(σ为特征点所在的尺度)内的所有点在x,y方向的Harr小波响应。并选取一个大小为60度的扇形窗口旋转整个圆形区域,将窗口内所有x,y方向的响应值相加得到一个新矢量,最终以最长的矢量所在的方向作为特征点的主方向。
特征点描述需要将坐标轴旋转到主方向上,并将以特征点为中心的边长为20σ的区域划分为4×4个子窗口,每个子窗口分为5×5个采样点,计算每个采样点的沿主方向和垂直主方向的Harr小波响应,记为d_x和d_y,最终生成一个4维矢量v=(∑dx,∑dy ,∑|dx|,∑|dy|),并将其归一化。总共4×4个子窗口,生成64维的描述符。
3.3 SURF在DM3730上的移植和优化
(1)SURF的移植
SURF算法实现基于OpenCV1.0,OpenCV库针对x86架构作了许多优化,在DSP上的执行效率难以得到保证。EMCV是一个可运行在DSP上的OpenCV库,但只实现了部分OpenCV的数据结构和库函数。因此,车载分布式视频监控系统需要扩充EMCV库,以支持SURF在DM3730上的运行。扩充的库函数包括:cvAdd、cvAddWeighted、cvConvertScale、cvCvtColor、cvGEMM、cvInvert、cvMerge、cvResetImageROI、cvResize、cvSVD、cvSetImageROI、cvSplit、cvWarpPerspective。
为了便于EMCV库的扩充和优化,EMCV库通过CCS(Code Composer Studio)软件以lib静态库的形式提供给Codec算法使用,如下所示:
[package.bld]
packageti.sdo.ce.examples.codecs.videnc_mosaic.emcv{
}
[package.xs]
functiongetLibs(prog){
var name = null;
if (prog.build.target.isa == "64P") {
var name = "emcv.lib";
print(" will link with " + this.$name + ":" + name);
}
return (name);
}
此外,为了消除SURF对C++标准模板库的依赖,车载分布式视频监控系统设计了专门的容器结构和相应的操作,主要代码如下:
typedefstruct _Vector{
void *pdata; // 数据块首地址
int count; // 数据块元素数目
int size; // 数据块已用大小
int totalSize; // 数据块总大小
}Vector;
#define PRE_CALLOC_SIZE 20 // 预分配元素个数
/* 添加nElem个元素,每个元素大小elSize */
intvector_pushback( Vector *pVector, intnElem, intelSize ){
int n = nElem> PRE_CALLOC_SIZE? nElem:PRE_CALLOC_SIZE;
if(pVector->size + nElem*elSizetotalSize ){
pVector->size += nElem*elSize;
pVector->count += nElem;
return 0;
}else{ // 预分配的内存不足,需重新分配内存
pVector->totalSize += n*elSize;
void *pNewData = (void*)realloc( pVector->pdata, pVector->totalSize );
if(pNewData ){
pVector->pdata = pNewData;
pVector->size += nElem*elSize;
pVector->count += nElem;
return 0;
}else{ // 内存分配失败
return -1;
}
}
}
/* 销毁容器,释放内存 */
voidvector_destroy( Vector*pVector ){
if(pVector->pdata ){
free(pVector->pdata );
pVector->pdata = NULL;
}
pVector->size = pVector->count = pVector->totalSize = 0;
}
(2)SURF在DM3730上的优化
SURF在DM3730上的优化分为项目级优化、指令级优化和缓存优化三个方面。项目级优化是通过合理地选择和配置相关的编译器优化选项,主要包括:调试模式选项(Debugging Model)、优化等级选项(opt_level)、代码大小选项(opt_for_sapce)、代码速度选项(opt_for_speed)、程序级优化(-op)等。为了最大限度地提高代码的执行效率,车载分布式视频监控系统选择的编译器优化选项为-o3、-ms0、-mf5、-op2、-mt、-mh、-mw。指令级优化包括选择合适的数据类型,消除指令和数据之间的相关性,使用内联(intrinsic)函数以及改善软件流水等。缓存优化是将CPU近期访问过的数据或者程序放置在Cache中,以提高CPU的执行速度。
4 测试结果及分析
图6展示了车载分布式视频监控系统的拼接效果,表1比较了SURF和SIFT算法在DM3730和PC机上的拼接效率。从拼接效果可以看出,车载分布式视频监控系统能适应图像的平移、旋转和缩放等特性。图6中的两幅待拼接的图像存在明显的旋转特性,并且拼接完成的图像有一定的缩放效果。从表1中可以看出,车载分布式视频监控系统在视频采集、视频传输和视频显示上总耗时约为257ms,远远小于视频拼接所需时间3264ms。这是由于视频拼接模块使用了许多EMCV和OpenCV库函数,它们在DM3730处理器上还有待进一步被优化。作为SIFT算法的加速版,SURF算法的执行效率要远远大于SIFT算法的执行效率。从本次测试结果看,在DM3730上,SURF算法的执行效率是SIFT算法执行效率的3.68倍左右;而在以Intel Core2 Duo T5870为处理器的PC机上,SURF算法的执行效率是SIFT算法执行效率的1.40倍左右。
在摄像头相对位置固定情况下,图像之间的透视变化矩阵固定,因此只需计算一次透视变化矩阵,后续的图像拼接只需进行图像配准和融合。表2中列出了DM3730上SURF算法的时间组成,其中SURF算法透视变换矩阵计算时间占95%以上,实际的图像拼接时间为图像配准和如何时间,平均时间约为66ms。
结语
本文从视频采集、视频传输、视频拼接和视频显示等四个方面详细阐述了基于Android和DM3730的汽车分布式视频监控系统的设计原理和优势。从测试结果看,车载分布式视频监控系统基本上能达到实时采集、实时传输、实时显示,经过优化后,图像拼接的效率基本能满足实时性要求,但系统整体性能还有待提高,可以采用多核处理器代替单核处理器,进一步提高系统的实时性。
参考文献
[1] Google launches the Android-based Open Automotive Alliance with Audi, Honda, GM, and more, The Verge, January 6, 2014.
[2] Instruments T. DM3730, DM3725 Digital Media Processors[R]. Tech. Rep. July, 2011.
[3] Lee Y H, Chandrian P, Li B. Efficient java native interface for android based mobile devices[C]//Trust, Security and Privacy in Computing and Communications (TrustCom), 2011 IEEE 10th International Conference on. IEEE, 2011: 1202-1209.
[4] 龚泽挚, 蓝晓柯, 郑雅羽. 基于 Android 和 DM3730 的视频编码软件开发[J]. 电视技术, 2013, 37(17): 76-79.
[5] 胡楠. EMCV 库扩充及车辆检测系统的嵌入式实现[D]. 大连海事大学, 2011.
[6] 于海. OpenSURF在TI DM642上的移植[J]. 电子科技, 2012, 25(5): 133-136.
[7] 王飞, 孔聪. 基于 V4L2 的 Linux 摄像头驱动的实现[J]. 电子科技, 2012, 25(2): 86-87.
[8] 赵学良. 基于 Android 的流媒体引擎设计与实现[D]. 电子科技大学, 2012.
[9] Bay H, Tuytelaars T, Van Gool L. Surf: Speeded up robust features[M]//Computer Vision–ECCV 2006. Springer Berlin Heidelberg, 2006: 404-417.
[10] 杨小辉, 王敏. 基于 ASIFT 的无缝图像拼接方法[J]. 计算机工程, 2013, 39(2): 241-244.
[11] 刘旭. 多图像全景拼接技术研究[D]. 武汉理工大学, 2012.
Android ARM Cortex DSP 视频监控 USB 嵌入式 Linux EMC 电子 滤波器 相关文章:
- 基于Android的车载导航系统的研究与设计(01-14)
- 基于Android车载虚拟仪表人机界面设计(06-22)
- 9种常见导航系统的设计,软硬件协同(04-05)
- 实现向车载信息娱乐技术过渡(11-22)
- 辰汉发布面向工业汽车领域的Cortex-A9四核iMX6xMDK开发平台(04-19)
- GPS车载导航仪可以进行多媒体娱乐的双屏异显(06-27)