通过GC Nano技术提升用户界面体验
时间:12-24
来源:互联网
点击:
GPU是提升HMI用户体验的基础技术,可以实现屏幕/UI合成,包括多个源(ISP/照相机、视频等)的多层混合、图像过滤、字体渲染/加速、3D效果(变换、透视等)等很多其他功能。Vivante拥有一条基于GPU技术的综合产品线,包括GC Vega系列和GC Nano系列。
GC Vega系列适用于需要最新、最好GPU硬件和功能的SoC,这些功能包括:OpenGL ES 3.1,完整安卓扩展包(AEP)支持,包括硬件镶嵌/几何着色器(TS/GS)、DirectX 12、CTM(closetothemetal) GPU编程、混合射线跟踪、零驱动开销、传感器融合以及针对使用OpenVX、OpenCV或OpenCL视觉处理的GPU计算,都纳入到最积极的PPA(性能、功耗和面积)和全功能设计方案中。目标市场覆盖高端可穿戴设备和近距离/中距离移动设备、4K电视以及用于服务器虚拟化的GPU。
GC Nano系列则属于另一范畴,适用于为具备GPU渲染的HMI/UI的可穿戴设备和IoT设备(智能家庭/家电、信息设备……)等消费类产品带来革命性推动的器件。该内核专为在CPU、内存(片上和DDR)、电池及带宽非常有限的资源受限型环境下工作而设计。GC Nano还进行了优化,与需要在30/60fps及以上速率下提供UI合成加速的较小尺寸的MCU平台配合工作。GC Nano系列的优势包括:
·优化的硅片面积和功率。硅片占位极小,可使受限SoC的单位面积性能达到最佳;这就意味着,厂商可在不超出硅片/功率预算且保证灵敏、平滑的UI性能的前提下,在其设计中添加增强图像功能。GC Nano可在超低功耗和热量(最小动态功率和接近零的泄漏功率)下最大限度地延长电池寿命。
·智能合成。Vivante的即时模式渲染(IMR)架构通过智能化的方式,仅合成和更新发生改变的屏幕区域,减少了合成带宽、延迟、开销及功率。合成可以通过两种方式进行:利用GC Nano合成所有屏幕层(图形、背景、图像、视频、文本等);或通过紧耦合的设计,其中GC Nano与显示控制器/处理器(第三方或Vivante DC核)同时工作实现UI合成。想要进一步减少带宽,还可以通过Vivante的DEC压缩IP核对数据进行压缩/解压缩。
·可穿戴和IoT 设备即用。超轻量级向量图形(GC Nano Lite ) 和OpenGLES 2.0(GC Nano、GC Nano Ultra)驱动、SDK及工具可很容易地将可穿戴设备及物联网设备屏幕过渡到消费级图形界面。GC Nano包还包括教程、示例代码及其他文档,以帮助开发人员优化或移植其代码。
·为MCU/MPU平台设计。可卸载并极大降低系统资源的有效设计,包括完整UI/合成及显示控制器集成、最小CPU开销、无DDR且仅含闪存的配置、带宽调制、CTM GPU驱动以及针对可穿戴/IoT设备的、可减少硅片尺寸的GPU特性。软件代码量极小,减少了对内存大小的限制,缩短了GPU初始化/启动时间,同时对于需要一键显示信息的屏幕,可以瞬间启动UI合成。
·生态系统和软件支持。开发人员可以利用轻量级NanoUI或OpenGL ES API进一步扩展或定制解决方案。业界对于现有Vivante产品提供的大量支持,包括覆盖字体、插图工具及Qt开发环境的重要合作伙伴的、针对Android、AndroidWear及嵌入式UI解决方案的GC Nano/GC Nano Ultra产品线。
·计算即用。未来几年内,可穿戴/物联网(处理)节点数量将以数百亿个的速度增加,由于节点始终保持开启、互联和处理状态,数据网络的带宽可能成为问题。GC Nano通过在节点上进行超低功率处理(GFLOP/GINT ops),且仅根据需求发送有用的压缩数据,可以有效缓解带宽压力。案例包括传感器融合计算和图像/视频带宽降低。
Vivante的软件驱动栈、SDK以及工具包将支持NanoUI API,其可为无操作系统/无DDR 的GC Nano Lite提供CTM GPU加速,同时还可为更先进的解决方案(包括专有或高级操作系统,例如嵌入式Linux、Tizen、Android、AndroidWear 及其他在最小内存空间中需要OpenGL ES 2.0+的RTOS)提供OpenGLES 2.0 API(3.x可选)。这些各种各样的操作系统/无操作系统平台将构成下一代可穿戴设备和物联网的基础,为每个人带来独特的最佳个性化体验。GC Nano驱动包括主动节能、智能合成与渲染以及带宽调制,使OEM厂商和开发人员能够使用超轻UI/合成或3D图形驱动为可穿戴设备和物联网构建丰富的视觉体验。
GC Nano的很多创新创建了一个完整“视觉”可穿戴设备MCU/SoC平台(图1),能够实现PPA和软件效率最优化,从而改善设备的整体性能和BOM成本,同时提供最紧凑的UI图形软硬件开销,不会降低或限制屏幕上的用户体验。随着可穿戴设备和物联网逐步融入人们的生活,这些新的GPU将会越来越多地应用到身边的新奇产品中。
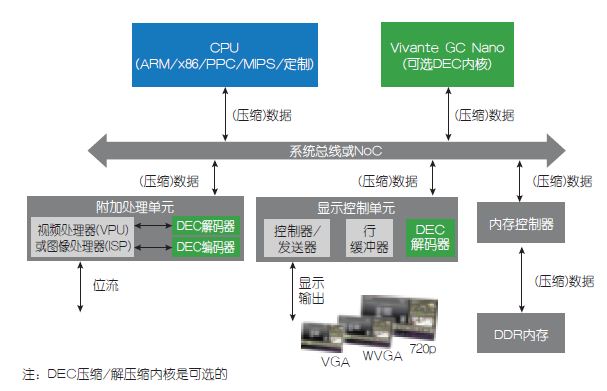
图1:GC Nano系列SoC/MCU实现案例。
3D UI渲染的趋势和重要性
如图2智能家庭设备的UI案例所示,下一代产品将采用智能手机、平板电脑及智能电视中精心策划的UI设计元素,并将它们整合到物联网设备及可穿戴设备中,使产品保持一致界面。相似的UI外观(look -and-feel)可以减少使用学习曲线,加快设备采用速度。另外,由于不同设备的处理能力/性能水平不同,会依据较小尺寸屏幕采用最低水平配置(基准性能),但是随着设备性能上升到操作系统供应商划分的更高层级,还可添加附加特性/更高性能。
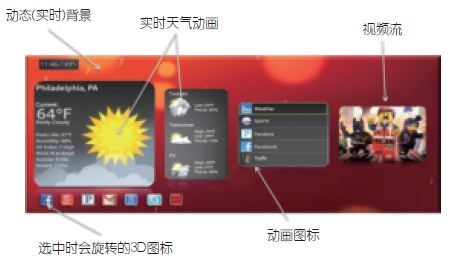
图2:智能家庭设备上的HMI用户界面样例。
更新后的UI包括以下新特性:
·动画图标—为用户轻松呈现选中的菜单项或输入光标指向的位置,使用户无需花费时间寻找屏幕上的光标位置。在选中图标前,图标可以旋转、摆动、弹出、闪现等。
·实时动画—动态内容可以将简单的背景(壁纸)转化成动态的移动场景,为用户设备增加个性修饰。背景图像和设计也可搭配装饰、照明、主题及气氛等实现个性化设置。一些大型白色家电制造商正在测试这些概念设计,希望不远的将来能够展现一二。
·3D效果—文本、图标和图像可超越简单的阴影效果,其中,GPU功能可利用强大的着色器指令渲染,为UI各个部分增添3D特征(例如:转盘、视差、深度模糊、部件/图标渲染成3D/2D形状、图标运动的程序/模板动画、粒子系统的物理仿真、透视图等)。这些效果可以利用GCNano的超低功率OpenGL ES 2.0/3.x流水线实现。
GC Nano的架构在HMI UI合成方面表现出色,可以呈现3D UI效果并降低带宽和延迟,详见下文。
GC Nano带宽计算
本节将会逐步叙述多种用户界面场景示例,并对GC Nano GPU渲染的30和60fpsUI HMI计算系统带宽。
合成方法
将评估的屏幕显示合成有两种选择:第一,GPU完成所有层(或表面,包括视频)的整个屏幕合成,显示控制器仅将已合成的HMI U I输出到屏幕上(图3);第二,显示控制器对GPU和视频解码器(VPU)合成的层进行最后的混合和合并,再显示出来(图4)。顶层示意图未显示DDR内存事务,但将在后续UI步骤的描述中给出。
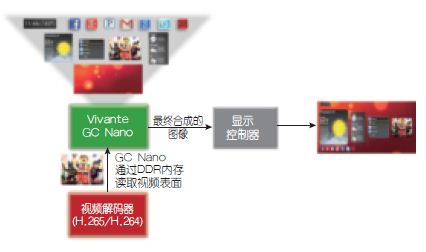
图3 :GC Nano全合成:在向显示控制器发送最终输出帧前,GN Nano对所有UI层进行处理。
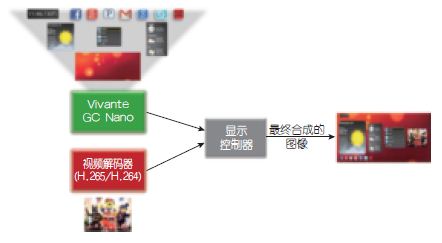
图4:显示控制器合成:最终输出帧由显示控制器利用来自GCNano和视频处理器的输入层合成。
UI带宽计算
计算假设。GC Nano UI处理采用ARGB8(每像素32位)格式。当GC Nano进行全合成时,GPU会自动将16位YUV视频格式转换成32位ARGB格式。
视频帧为YUV422(每像素16位)格式,并且与屏幕尺寸分辨率相同(GC Nano将输入视频作为视频纹理对待)。最终合成的帧为ARGB8格式(每像素32位)。读取视频的请求突发长度为32字节。GC Nano UI请求突发长度为64位字节。写出UI渲染和最终帧的写长度为64字节。
这些情况假设UI渲染为32位。如果显示格式为16位(适用于较小屏幕),则以下所列的带宽计算将会大大降低。带宽计算将以WVGA(800x480)和720p(1280x720)为例。本例中,需要刷新/更新的每帧UI像素的大小包括以下比例:15%(标准UI);25%; 50%(最差UI)。
·GC Nano全UI合成。图5 描述了来/去DDR内存的数据流利用GC Nano进行整个UI合成的过程。采用这种方法的好处包括:利用GPU在图像或视频上进行一些前后处理、过滤、为图像/视频添加标准3D效果(视频转盘、弯曲/去弯曲等)以及增强实境(GC Nano在视频流顶部覆盖渲染的3D内容)。由于可以对GC Nano编程使其执行图像/UI相关任务,这种方法灵活度最高。


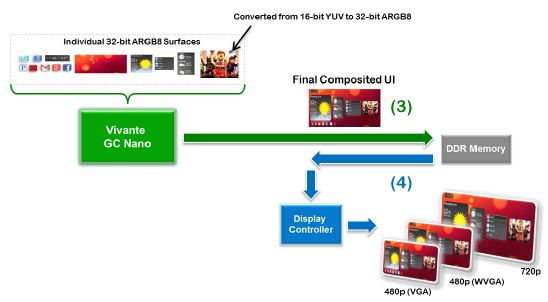
图5 描述了来/去DDR内存的数据流利用GC Nano进行整个UI合成的过程。
·本显示控制器UI合成。本节描述了来/去DDR内存的数据流利用显示控制器对来自GC Nano和视频处理器的各层进行最终合并/合成的过程(图6)。这种方法在一定程度上降低了带宽消耗,这是因为GPU不进行最终帧合成,也就无需读取视频表面。GPU仅负责合成帧的UI部分,而不涉及来自SoC/MCU中其他IP模块的任何附加层。这种方法的一个好处就是,可降低系统总带宽,但会牺牲UI的灵活性。如果视频(或图像) 流仅需要与U I剩余部分合并,那么这个方法正好合适。如果输入视频(或图像)流需要以任意方式处理(添加3D效果、过滤、增强实境等),那么这个方法就有局限性,最好利用GPU进行全帧UI合成。
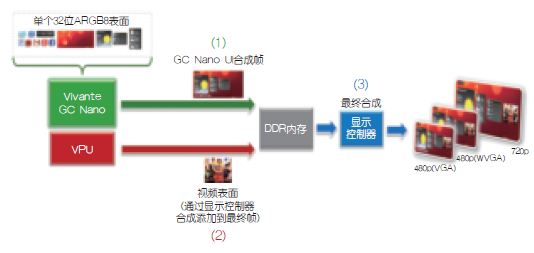
图6:显示屏控制器对来自GC Nano和视频处理器(VPU)的两个输入层进行最终帧合成。
显示控制器包含一个能够直接从系统内存中读取数据的DMA引擎,其支持多种数据格式,包括ARGB、RGB、YUV444/422/420及其重排格式。
GC Nano合成UI的架构优势
GPU渲染包括两个主要架构,即瓦片纹理渲染(TBR)和直接渲染(IMR)。TBR在全帧所有相关信息都可用时,将屏幕图像分解成方块并进行渲染。在IMR下,图形命令直接向GPU发布并立即执行。Vivante架构中的技术可以剔除帧中隐藏或不可见的部分,因而不会在渲染最终将被去除的场景部分上浪费执行、带宽和功率等。Vivante的IMR在为最新AAA级游戏(利用全硬件加速呈现精细的几何图形和PC水平的图形质量)渲染逼真的3D图像时也具有显著优势,例如其高端GC Vega内核(DirectX 11.x、OpenGL ES 3.1及安卓扩展包AEP)可支持高级GS/TS着色器等。注:GC/TS等一些高级特性不适用于GC Nano系列。
UI瓦片纹理渲染(TBR)架构
下面说明在TBR架构下渲染UI的过程。
·场景分解成块。TBR架构将图像分解成独立的瓦片(小方块)进行渲染。每个方块都有自己的数据库/命令列表(方块列表),并且在GPU开始渲染和进入下一帧之前,整个帧的所有命令都需处于可用状态。数据库/方块列表缓冲区的大小在渲染(可能导致溢出)前也是未知的,并且依赖于帧—简单帧数据库较小,而复杂帧数据库较大。任何方块在处理过程中发生变化都意味着整个帧数据库需要再次更新,而且在某些情况下,需要刷新全帧并重启。
图7a 场景分解成块
·但是在渲染帧之前,所有UI表面在处理前都需通过瓦片前处理。在UI 合成之前,TBR架构需要每个UI表面都通过瓦片前处理。在本样本图中,12个表面中的每一个都被分割成三角形来进行渲染—本例为两个三角形,但三角形的数量也可以更多。由于每个帧都需要经过预处理,这就极大地增加了合成的时延。
图7b 每一个都被分割成三角形来进行渲染。
·将预处理步骤和分块步骤相结合,可实现以下效果。图8展现了当前帧的情况,所有的UI表面都被分割为三角形,整个帧被分块,并准备好进行渲染。如果帧不发生任何变化(静态UI),则可按原样渲染。
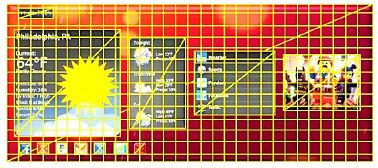
图8a 展现了当前帧的情况,所有的UI表面都被分割为三角形,整个帧被分块,并准备好进行渲染。
·如果UI为动态,则帧各部分需要进行重处理。如果帧各部分为动态,则只有被标注为“dirty”的方块将根据变化进行重处理。对于细小的变化,只要UI表面保持原样,且只有一小块区域在任何给定时间进行更新,则可以接受。较新的UI为前景和背景表面增加了动态特征—帧内容、图像、文本等很多部分不断发生变化。例如,天气图标(如雨和云)可能是动态的,菜单项会自动滚动,内容会不断更新,视频在播放,背景墙纸也是动态的。在各种情况下,所有的UI表面将需要经过预处理,为渲染做准备,而这就增加了时延。

图8b 如果UI为动态,则帧各部分需要进行重处理。
·图9(详见本刊网站) 展示了UI 内部的“dirty”方块。每个黄色板块代表一个“dirty”方块,需要进行更新。每次表面发生变化时,都需要经过预处理,相应的方块也需要经过预处理。如果在帧完成数据库和命令列表时发生任何变化,则在TBR GPU移动至下一个帧前,整个数据库都需要进行更新。

图9 UI内部的“ dirty”方块。
·TBR UI渲染总结。从上述步骤可看出,由于预处理的UI三角形需要首先储存在内存中,然后在使用时会被读取,基于TBR的GPU具有额外开销,这就增加了UI渲染的时延。TBR GPU也需要大量的片上L2缓存来存储整个帧(方块)数据库,但随着UI复杂性增强,片上L2缓存大小(裸片面积)只能同时增加,或TBR内核只能不断溢出至DDR内存,这会导致时延、带宽和功率增加。TBR具备确认和追踪U I的哪些部分(方块)和哪些表面发生了变化的机制,可尽可能简化预处理过程,但对于拥有很多移动区域的较新UI来说,这仍构成了限制。此外,随着屏幕尺寸/分辨率和内容复杂性的增加,在所有屏幕上,由此导致的时延在使用统一UI的谷歌、微软和其他操作系统平台上甚至显得更为明显。
UI的直接渲染(IMR)架构
最先进的GPU使用的是IMR技术,它是基于目标的渲染技术,在PC(台式机/笔记本)显卡中直到Vivante的GC系列产品线上都能看到。IMR技术使GPU可以渲染逼真的图像,并绘制屏幕上最新的复杂、动态、交互式内容。在该架构中,图形API调用命令被直接发送至GPU,收到命令和数据后即刻进行对象渲染。这一流程显著提升了3D渲染性能。
对UI来说,无需进行预通过处理,这消除了上一节中看到的TBR相关延迟。此外,UI中加入了许多智能事务消除机制,使得帧中的隐藏(看不到的)部分甚至不必通过GPU流水线发送;或是如果隐藏部分已经处于发送状态(例如,UI表面发生变化),它们也可以立即丢弃掉,这样流水线即可继续执行有意义的工作。
出于灵活性考虑,合成处理过程在着色器中进行,Vivante GPU可以自动增加矩形图元,以便将整个屏幕纳入考虑范围,进而实现100%的效率(使用两个三角形仅发挥50%的效率)。对于简单UI和3D帧而言,内存带宽等效于TBR架构,但对于更高级的UI和3D场景来说,TBR设计需接入远超过IMR的外存,因为TBR的片上缓存中无法容纳大量的复杂场景数据。
图10描绘了Vivante的IMR架构使用的动态UI渲染流程。该流程相较于TBR来说更为简单,UI或图形的动态变化更为一目了然。
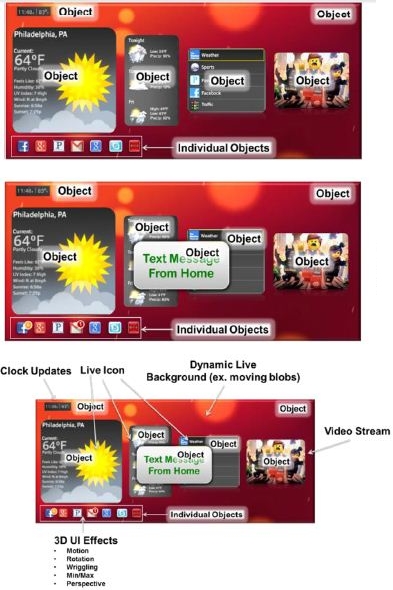
图10 描绘了Vivante的IMR架构使用的动态UI渲染流程。
·基于对象的IMR UI渲染。IMR GPU是基于对象的,即每个UI表面都被视为一个待渲染的个体对象。GPU收到与一个对象的命令列表后,它会立即执行命令,并绘制出表面。与此同时,GC Nano中也会添加一个新的图元,使矩形图元能够被渲染,进而实现100%的效率(使用两个三角形绘制矩形仅有50%的效率)。
·附加UI内容被视为新对象。新的UI表面(弹出式视窗、通知、新内容、新窗口等)也仅被视为对象进行处理。
·IMR GPU 是下一代动态UI 的理想之选。GPU收到某一对象的命令列表后,就会立即对其进行静态或动态渲染。同时,GPU也会对各个对象进行测试,利用各种剔除和深度/Z方法确定哪些是看得见的部分,并丢弃隐藏的部分。对象中看不见的部分会被立刻丢弃。那些最初看得见(位于GPU流水线中)但后来被隐藏(弹出通知覆盖了一个表面)的部分会被立刻摒弃,这样GPU就可以对另一个可视对象进行渲染。与TBR不同的是,IMR在处理前不必等待整个帧命令列表。
·IMR UI渲染总结。对于动态3D UI、复杂3D图形和映射应用等,IMR在延迟、带宽和功率方面更具优势。内存消耗与内存I/O是IMR的另一明显优势—对新型动态实时3D UI来说,IMR实属不二之选;对于标准UI来说,IMR和TBR势均力敌,但IMR 可为SoC / MCU 赋予灵活性且更适用于未来。注:在过去,TBR更适用于简单UI和简单的3D游戏(矩形/多边形数量少、复杂度低),因为TBR可以将完整的帧方块数据库保留在芯片(L2缓存)上。但随着领先的智能手机、平板电脑和电视的发展,UI技术也在不断进步,这使得IMR技术越来越受欢迎。
SoC 传感器 MCU 物联网 Android 嵌入式 Linux 平板电脑 仿真 解码器 相关文章:
- 高带宽嵌入式应用中SoC微控制器的新型总线设计 (02-02)
- SoC前段(ARM)嵌入式系统开发实作训练(上) (02-28)
- SoC前段(ARM)嵌入式系统开发实作训练(下)(02-28)
- 采用灵活的汽车FPGA 提高片上系统级集成和降低物料成本(04-28)
- 开放源码硬件简史(05-21)
- 可配置处理器技术优势详解(05-15)