可配置处理器技术优势详解
时间:05-15
来源:Tensilica公司中国区经理
点击:
微处理器技术发展历史
在介绍可配置处理器开发原理之前,我们先回顾一下处理器发展的历史。大约在20世纪70年代出现了第一代处理器,这个时期的处理器设计只是简单地追求性能,从4位处理器到早期的16位和32位微处理器。这种性能的提升奠定了20世纪80年代个人计算机PC和工作站的基础。个人计算机和工作站的增长使得微处理器设计进入了20世纪80年代的第2代微处理器研制时期。精简指令集RISC|0">RISC设计时代发生在20世纪90年代。在这个时期,即使像X86这样坚定的复杂指令集CISC处理器也假装成精简指令集RISC体系结构。在最初的这3代处理器的成长和发展过程中,微处理器设计专家将处理器设计成固定的、单个的和可重用的模块。但是在20世纪90年代随着专用集成电路ASIC|0">ASIC和片上系统SOC制造技术的发展为微处理器设计进入第4代(即后RISC、可配置处理器)打下了坚实的基础。
 |
首先,频率并不代表性能。低功耗的针对特殊应用的而设计的处理器架构比频率高得多的通用处理器性能可能更好。所以频率代表性能的结论只能局限于同样的架构的基础上。同时过高的频率意味着更高的功耗。
其次,应用的发展对处理器的需求越来越多样化。我们可以看到单颗通用处理器的极限已经到来,通用处理器需要处理的应用越来越复杂,需要多内核的支持。最大半导体公司Intel的多核的产品策略足以证明这一点。另外,后PC时代是消费电子产品的时代,通用的CPU和DSP都无法满足多种应用的要求。针对特殊应用设计的SOC要求能够灵活设计针对应用的最优化处理器:性能好、功耗低、面积小、大I/O带宽……
综上所述,应用的需求的发展促进了可配置处理器技术的产生和发展。
可配置处理器及其开发原理
以Tensilica Inc|573|1">Tensilica的Xtensa可配置处理器架构为例,探讨可配置处理器的开发原理。
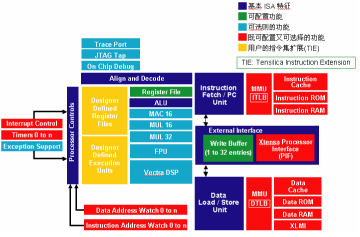
Xtensa可配置处理器架构是可配置可扩展的微处理器技术,可以用于片上系统SOC设计。现在的SOC需要更高系统性能、更高输入/输出带宽和更高功耗利用率, Xtensa架构均实现提供相应的解决方案。系统设计师可根据各自的应用需求,首先配置和选择架构元素,比如:内部cache大小,总线位宽,FPU单元, DSP引擎,中断数量… 进而针对应用扩展添加全新的指令、寄存器和I/O端口来设计具有专用功能的处理器内核。这种方法甚至能提供与手工RTL设计的硬逻辑有可比性的性能、尺寸和功耗等特性。通过图1可以看到Xtensa处理器的架构。
Xtensa处理器产生器可通过增加新的功能来自动产生用户所需要的硬件,产生硬件是经过验证的RTL代码格式。自动产生的处理器RTL代码可以和现在的SOC设计流程无缝结合,用于逻辑综合。处理器产生器还可建立与产生的处理器相匹配的系统软件。
可以说Tensilica可配置处理器技术的核心,是在于可伸缩可扩展的Xtensa处理器架构和功能强大的自动化生成工具-处理器生成器。
Xtensa架构打破输入/输出瓶颈
为了提高I/O带宽,可配置处理器必须克服总线瓶颈。 总线瓶颈问题是自Intel在1971年引入第一个商用微处理器4004以来就存在的问题。每个处理器都和系统总线上的其余设计部件进行通信。总线上的流量由加载/存储部件控制。由于总线的固有特性,在任何时候,只允许一小部分数据在总线上和处理器进行通信。另外,加载/存储单元和处理器内部执行部件以及处理器局部存储器通过类似有限的总线进行通信。这种单一的、一次只能一个方向的处理器总线特性严重限制了微处理器的系统吞吐量。
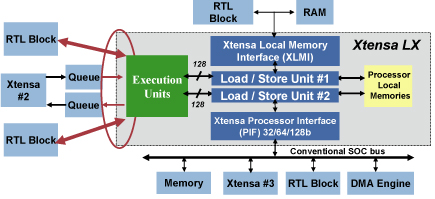
为了克服处理器总线所固有的局限性,Tensilica在Xtensa处理器中增加了另一个特性来永远消除总线瓶颈问题。这种新的特性称为TIE (Tensilica指令扩展)端口和队列技术。采样TIE端口和队列技术,设计者可以定义多达1024个端口直接与 Xtensa处理器执行部件相连接,如图2所示。每个端口宽度可以达到1024位。这种技术的结果是可以使系统以350,000 Gbits/秒的速度与Xtensa处理器进行信息交换。这可以充分满足所有处理器的输入/输出带宽需求和采用RTL技术设计的系统需求。
 |
Xtensa架构提高计算性能
随着传统微处理器总线瓶颈的解决,处理器工程师们将注意力集中到提高Xtensa 处理器的性能上,以便使得计算性能的提高可以和通过设置TIE端口和队列来提高输入/输出带宽相匹配。
自从1999年开始引入第一个可配置Xtensa处理器以来,片上系统SOC设计师已经具备能力来自己定义新指令,定义的新指令基于多操作(例如加法运算跟随一个移位或者一个位选择操作)技术,多操作指令可以作为一条新的指令。将多个操作合并在一起成为一条新的机器指令,该技术称为操作数融合。操作数融合技术可以有效提高微处理器的计算性能。另外,片上系统SOC设计者可以在Xtensa处理器版本中添加SIMD(单指令、多数据)指令。 单指令流多数据流SIMD指令可以同时对多个数据元素执行相同的操作,该技术也可以显著提高微处理器的计算性能。
然而,操作数融合和单指令流多数据流SIMD指令仍然只是微处理器的特征,每次只能发射一条指令。为更有效提高系统性能,设计人员决定在Xtensa处理器核中增加每个时钟周期发射多条指令的能力。
从历史的观点来看,处理器设计人员可以通过两种方法来实现微处理器具备每个时钟周期可以发射多条指令的能力。其一为超标量设计技术,该技术通过复制处理器整个执行部件来保证指令译码和发射部件在每个时钟周期可以发射多条指令。采用这种方法,处理器硬件必须在应用程序代码中找到软件固有的指令级并行性。 该技术的缺点是超标量处理器用于完全复制处理器执行部件的硬件开销大,而且程序代码中缺少指令级并行性。尽管4路超标量处理器设计时可以在每个时钟周期发射4个操作, 但是实际上从通用程序代码中抽取的平均指令级并行性通常低于两个操作。
第二种方法是采样称为超长指令字VLIW的技术来保证处理器每个时钟周期发射多个操作。该方法采用一个非常长的指令字来对多个操作进行编码,有时每个指令字可以达到几百位,多个操作可以同时发射到VLIW处理器的多个执行部件。VLIW处理器的编译器负责找出应用程序代码中的指令级并行性, VLIW处理器编译器通常具有比较高的能力来识别程序中的并行性,因为编译器扫描指令的窗口范围比超标量处理器要大,而超标量处理器是采用指令译码和发射部件来对指令代码的并行性进行调度。VLIW技术从处理器硬件开销的角度来说是非常有效的,然而VLIW处理器会造成指令代码的剧烈膨胀(故需要更大的存储器),因为每条VLIW指令字都非常长,而且VLIW编译器经常不能找到足够的目标程序代码中的指令级并行性来保证处理器中的每个执行部件都保持忙碌状态。因此,VLIW处理器由于带有与代码相关的特性以及会耗尽片上的指令存储器,故对深度嵌入式应用的处理器而言也不是一个理想的选择。
因此,处理器设计人员开发了一种变种VLIW结构,称为可变长度指令扩展FLIX技术,用于Xtensa处理器。和VLIW指令一样,FLIX 指令可以将多个独立的指令操作进行编码,变成一个FLIX指令字,该指令字宽度为32位或者64位,如图3所示。和所有设计人员定义的TIE指令一样, FLIX指令均是可选择的,并且它们可以和Xtensa处理器现有的16和24位指令自由地混合在一起。因此,采用FLIX指令就避免了代码膨胀问题,同时应用程序代码执行速度更快,而不是使得程序代码变得很长。
由于提高了输入/输出带宽和计算性能,因此基于Xtensa 处理器的片上系统SOC设计通常可以以比基于固定指令集体系结构ISA的处理器更低的时钟频率进行运行,这些低频的时钟频率可以保证系统有更低的SOC系统功耗。然而,Xtensa处理器还可以通过扩展的内部时钟门控技术来保证系统有更低的系统功耗,时钟门控技术是由TIE指令进行自定义扩展的。
由于微处理器是由指令进行驱动的,因此可以通过对处理器指令执行流水线中的指令进行分析来确定在某些时间处理器的哪些部件处于运行状态。这种分析通常需要几十亿个系统仿真时钟周期,这样可以让Xtensa设计人员在处理器设计时通过增加细粒度时钟门控来关闭那些指令执行过程中没有执行到的处理器单元部件。进一步,如果处理器没有执行到的TIE操作,那么Xtensa就可以对TIE扩展定义的整个系统硬件关闭时钟。因此,Xtensa处理器可以拥有几百个不同的门控时钟域,这样可以真正使得微处理器的活动功耗降到最低。
- 高带宽嵌入式应用中SoC微控制器的新型总线设计 (02-02)
- SoC前段(ARM)嵌入式系统开发实作训练(上) (02-28)
- SoC前段(ARM)嵌入式系统开发实作训练(下)(02-28)
- 采用灵活的汽车FPGA 提高片上系统级集成和降低物料成本(04-28)
- 开放源码硬件简史(05-21)
- 基于ADSP-BF537的视频SOC验证方案设计(05-18)