说话人语音特征子空间分离及识别应用
时间:11-30
来源:互联网
点击:
4 实验分析
需要通过实验分析的问题包括:
(1)基于特征子空间识别方法的有效性?
(2)子空间维数与识别性能的关系?并确定一个最佳子空间维数。
(3)不同子空间距离测度下识别性能的比较分析
(4)不同特征参数,例如LPCC、MFCC情况下识别性能分析?
(5)不同长度测试语音输入时,说话人识别性能的变化趋势?
(6)在相同训练语音数据、实验环境和条件下,子空间方法和VQ、GMM等其他方法的识别性能比较分析。
4.1 实验数据与条件
语音数据选择SD2002一D2数据库,该数据库中包含了在普通实验室环境下通过计算机声音系统采集得到的40个说话人的280条语音片段,其中,男声26人,女声14人,每人分别有7段语音,每段语音包括停顿间隙长度为12秒。语音采样率为11025Hz,16位量化,单声道输入。实验中,每说话人的前4段语音用于模型训练,后3段用于测试。
在模型训练和识别测试中,预处理部分首先消除输入语音信号的背景噪声,保留纯语音数据,并进行权重系数为0.97的高频提升。短时分析采用27ms哈明窗,帧移步长18ms。特征参数LPCC和MFCC为16阶,其中,LPCC由16阶LPC线性预测系数推导得到,MFCC是基于Mel频率尺度的倒谱系数,通过计算Mel频率域均匀分布的19个三角滤波器组的DFT输出,并经DCT变换得到,实验中选取第l~16个系数作为特征参数。实验中,特征子空间采用说话人的前4段语音信号进行训练,其纯语音成分的长度平均为32秒。测试实验采用每说话人的后3段语音。
4.2 不同距离测度和特征参数下子空间维数与识别性能关系分析
根据PCA原理,特征子空间可以选择较大散度本征值对应的本征向量为基底,这样可以提高子空间之间的非相关性。但是,选择的基向量不能过少,否则可能引起子空间不能充分表示语音特征的分布结构。因此,需要在实验分析子空间维数与识别性能关系的基础上确定一个最佳子空间维数。
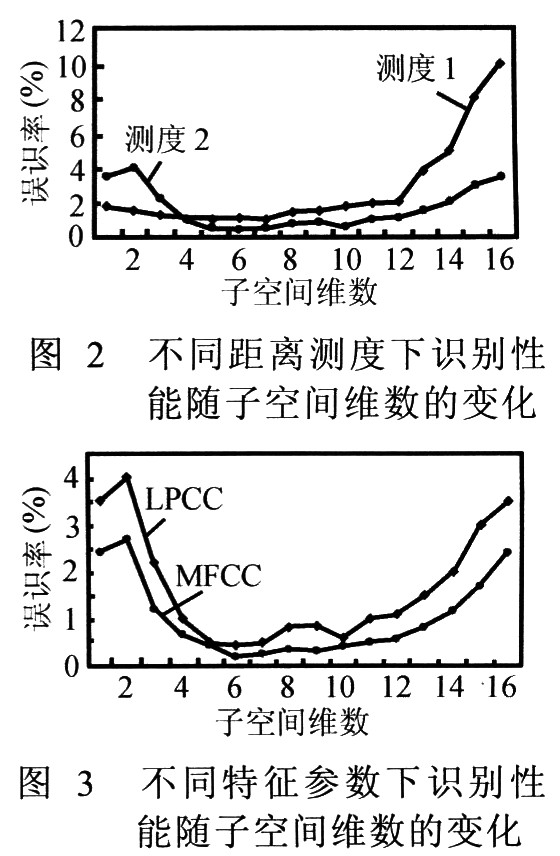
将散度本征值按大小顺序排列,并选取前面几个较大本征值所对应的本征向量作为子空间的基向量进行分析。图2显示了采用LPCC特征参数以及两种不同子空间距离测度情况下系统误识率随子空间维数变化的情况,其中测试语音长度为3秒。可以看到,第二种子空间距离测度总体上比第一种距离测度更优越,但两种测度下都显示当子空间维数为6时系统的误识率最低。图3显示了采用第二种子空间距离测度时,两种特征参数LPCC和MFCC所对应的识别性能随维数变化的情况,其测试语音长度也是3秒。可以看到,MFCC参数相对而言比LPCC要优越些,但差距并不大。另外,从图3同样可以看到当子空间维数为6时系统具有最佳识别性能。
根据以上实验结果可以得出这样得结论:基于子空间分离的说话人识别方法是有效的,但其识别性能随子空间维数是变化的,当维数为6时识别性能达到最佳,误识率仅为0.189%。因此,在以下的实验分析中子空间维数均采用6。
4.3 不同特征参数下识别性能与测试语音长度关系分析
实际应用中,测试语音的长度不是固定的。因此,衡量一个说话人识别系统的识别性能必须针对不同的测试语音长度进行分析。
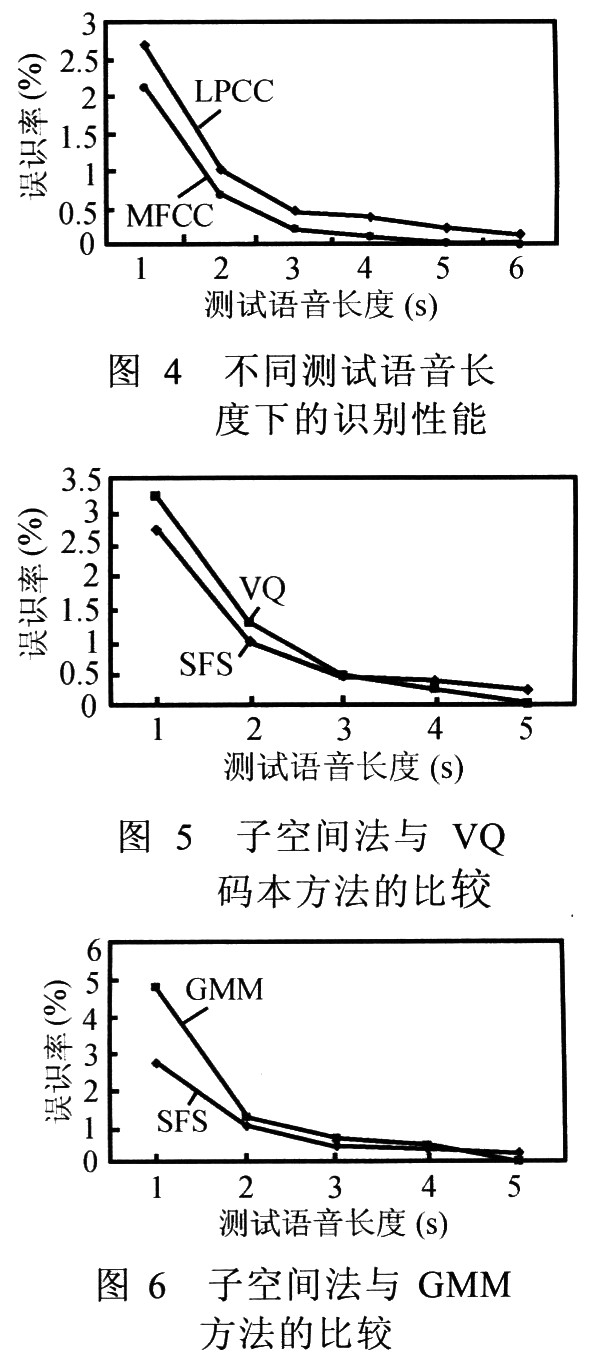
图4显示了当采用两种特征参数LPCC和MFCC时,不同测试语音长度下系统的识别性能情况。其中,子空间距离的计算采用第二种测度,即d2(Vt,SF)。
从图4可以看到,所有测试语音长度下系统都能够得到较好的识别性能,误识率均在3%以下,当测试长度达到5秒时,MFCC对应的误识率趋于零,但LPCC对应的误识率下降趋势慢一些。另外可以看到,采用MFCC作为特征参数时的识别性能比LPCC时优越,但差距并不大。
4.4 子空间方法与其他方法的比较分析
说话人识别的根本性问题是模型和特征参数,即用怎样的方法去描述说话人的语音特征以及采用什么样的参数表示说话人语音特征的问题。但到目前为止,还没有提出专门用于说话人识别的语音特征参数和模型,常用的文本无关说话人模型有GMM和VQ。
图5和图6分别显示了子空间方法与VQ和GMM方法的比较。其中,VQ码本的码字数为128,GMM的混合分量数为16。可以看到,子空间方法在测试语音长度小于3秒时其识别性能优于其他方法,而在大于等于3秒时则相反。这个结果说明,GMM和VQ等完全基于统计聚类的方法由于运用了说话人语音的统计特性,所以对于较长的测试语音有较可靠的识别性能,但当测试语音较短时,由于无法提供可靠的统计特性进行匹配,误识率就很快下降。而子空间方法是根据说话人语音特征的分布散度得到的一种空间结构性模型,由于不是完全依靠语音特征的统计特性,所以在较短的测试语音时也能够得到较好的识别性能。
5 结论
依据PCA原理,从说话人语音特征观察空间根据其分布散度特性分离出特征子空间作为说话人的一种结构性语音模型是有效的。当采用MFCC参数,测试语音长度为5秒时系统误识率趋于零。特别是在小于3秒的短时测试语音情况下,其识别性能优于其他方法。另外,子空间方法在识别时的计算量明显小于其他方法。
说话人识别和语音识别中存在同样的核心问题,即没有解决说话人个性特征和语义特征的提取和描述,这个问题极难。目前主要采用的特征参数LPCC、MFCC等反映了语音信号的频谱特征,既包含语义特征信息,又包含个性特征信息,在具体应用中只是根据不同的识别任务进行语义特征或个性特征的归一化处理,主要的归一化处理通过语音模型训练进行。显然,这样的传统方法为了使语音模型很好地表示说话人的语音特征必须通过大量的语音样本进行训练,测试时需要的语音数据也比较多。但是,实际应用中系统往往没有足够的数据用于这类统计模型的训练和识别,因此,在考虑如何提高说话人识别系统鲁棒性的同时,需要研究少量语音数据前提下的训练和识别问题。基于子空间分离的说话人识别方法在短测试语音长度下有一定优势,但在较长测试语音情况下识别性能提高不快。因此,今后将考虑通过子空间映射,在子空间建立说话人统计模型的方法来提高总体识别性能,特别是较长测试语音长度下的识别性能。
需要通过实验分析的问题包括:
(1)基于特征子空间识别方法的有效性?
(2)子空间维数与识别性能的关系?并确定一个最佳子空间维数。
(3)不同子空间距离测度下识别性能的比较分析
(4)不同特征参数,例如LPCC、MFCC情况下识别性能分析?
(5)不同长度测试语音输入时,说话人识别性能的变化趋势?
(6)在相同训练语音数据、实验环境和条件下,子空间方法和VQ、GMM等其他方法的识别性能比较分析。
4.1 实验数据与条件
语音数据选择SD2002一D2数据库,该数据库中包含了在普通实验室环境下通过计算机声音系统采集得到的40个说话人的280条语音片段,其中,男声26人,女声14人,每人分别有7段语音,每段语音包括停顿间隙长度为12秒。语音采样率为11025Hz,16位量化,单声道输入。实验中,每说话人的前4段语音用于模型训练,后3段用于测试。
在模型训练和识别测试中,预处理部分首先消除输入语音信号的背景噪声,保留纯语音数据,并进行权重系数为0.97的高频提升。短时分析采用27ms哈明窗,帧移步长18ms。特征参数LPCC和MFCC为16阶,其中,LPCC由16阶LPC线性预测系数推导得到,MFCC是基于Mel频率尺度的倒谱系数,通过计算Mel频率域均匀分布的19个三角滤波器组的DFT输出,并经DCT变换得到,实验中选取第l~16个系数作为特征参数。实验中,特征子空间采用说话人的前4段语音信号进行训练,其纯语音成分的长度平均为32秒。测试实验采用每说话人的后3段语音。
4.2 不同距离测度和特征参数下子空间维数与识别性能关系分析
根据PCA原理,特征子空间可以选择较大散度本征值对应的本征向量为基底,这样可以提高子空间之间的非相关性。但是,选择的基向量不能过少,否则可能引起子空间不能充分表示语音特征的分布结构。因此,需要在实验分析子空间维数与识别性能关系的基础上确定一个最佳子空间维数。
将散度本征值按大小顺序排列,并选取前面几个较大本征值所对应的本征向量作为子空间的基向量进行分析。图2显示了采用LPCC特征参数以及两种不同子空间距离测度情况下系统误识率随子空间维数变化的情况,其中测试语音长度为3秒。可以看到,第二种子空间距离测度总体上比第一种距离测度更优越,但两种测度下都显示当子空间维数为6时系统的误识率最低。图3显示了采用第二种子空间距离测度时,两种特征参数LPCC和MFCC所对应的识别性能随维数变化的情况,其测试语音长度也是3秒。可以看到,MFCC参数相对而言比LPCC要优越些,但差距并不大。另外,从图3同样可以看到当子空间维数为6时系统具有最佳识别性能。
根据以上实验结果可以得出这样得结论:基于子空间分离的说话人识别方法是有效的,但其识别性能随子空间维数是变化的,当维数为6时识别性能达到最佳,误识率仅为0.189%。因此,在以下的实验分析中子空间维数均采用6。
4.3 不同特征参数下识别性能与测试语音长度关系分析
实际应用中,测试语音的长度不是固定的。因此,衡量一个说话人识别系统的识别性能必须针对不同的测试语音长度进行分析。
图4显示了当采用两种特征参数LPCC和MFCC时,不同测试语音长度下系统的识别性能情况。其中,子空间距离的计算采用第二种测度,即d2(Vt,SF)。
从图4可以看到,所有测试语音长度下系统都能够得到较好的识别性能,误识率均在3%以下,当测试长度达到5秒时,MFCC对应的误识率趋于零,但LPCC对应的误识率下降趋势慢一些。另外可以看到,采用MFCC作为特征参数时的识别性能比LPCC时优越,但差距并不大。
4.4 子空间方法与其他方法的比较分析
说话人识别的根本性问题是模型和特征参数,即用怎样的方法去描述说话人的语音特征以及采用什么样的参数表示说话人语音特征的问题。但到目前为止,还没有提出专门用于说话人识别的语音特征参数和模型,常用的文本无关说话人模型有GMM和VQ。
图5和图6分别显示了子空间方法与VQ和GMM方法的比较。其中,VQ码本的码字数为128,GMM的混合分量数为16。可以看到,子空间方法在测试语音长度小于3秒时其识别性能优于其他方法,而在大于等于3秒时则相反。这个结果说明,GMM和VQ等完全基于统计聚类的方法由于运用了说话人语音的统计特性,所以对于较长的测试语音有较可靠的识别性能,但当测试语音较短时,由于无法提供可靠的统计特性进行匹配,误识率就很快下降。而子空间方法是根据说话人语音特征的分布散度得到的一种空间结构性模型,由于不是完全依靠语音特征的统计特性,所以在较短的测试语音时也能够得到较好的识别性能。
5 结论
依据PCA原理,从说话人语音特征观察空间根据其分布散度特性分离出特征子空间作为说话人的一种结构性语音模型是有效的。当采用MFCC参数,测试语音长度为5秒时系统误识率趋于零。特别是在小于3秒的短时测试语音情况下,其识别性能优于其他方法。另外,子空间方法在识别时的计算量明显小于其他方法。
说话人识别和语音识别中存在同样的核心问题,即没有解决说话人个性特征和语义特征的提取和描述,这个问题极难。目前主要采用的特征参数LPCC、MFCC等反映了语音信号的频谱特征,既包含语义特征信息,又包含个性特征信息,在具体应用中只是根据不同的识别任务进行语义特征或个性特征的归一化处理,主要的归一化处理通过语音模型训练进行。显然,这样的传统方法为了使语音模型很好地表示说话人的语音特征必须通过大量的语音样本进行训练,测试时需要的语音数据也比较多。但是,实际应用中系统往往没有足够的数据用于这类统计模型的训练和识别,因此,在考虑如何提高说话人识别系统鲁棒性的同时,需要研究少量语音数据前提下的训练和识别问题。基于子空间分离的说话人识别方法在短测试语音长度下有一定优势,但在较长测试语音情况下识别性能提高不快。因此,今后将考虑通过子空间映射,在子空间建立说话人统计模型的方法来提高总体识别性能,特别是较长测试语音长度下的识别性能。
- 利用蓝牙技术和远程信息控制单元实现汽车诊断(11-13)
- 六大特点助CMOS图像传感器席卷医疗电子应用(11-13)
- 汽车网络的分类及发展趋向(11-13)
- 多核嵌入式处理技术推动汽车技术发展(11-18)
- CAN总线的客车轻便换档系统设计与实现(02-13)
- 高性能嵌入式ARM MPU在医疗电子系统中的设计应用(05-12)