基于DTW的编码域说话人识别研究
时间:11-28
来源:互联网
点击:
3 实验结果与性能分析及结论
为测试上述识别性能,对其进行了固定文本的说话人识别试验。试验中,采用电话信道863语料库30个说话人共300个录音文件,文件格式为16 bit线性PCM。为了模拟VoIP中语音压缩帧,使用G.729声码器对原始语音文件进行压缩。使用每个说话人的一个文件训练成为模板。测试语音长度为10 s~60 s以5 s为间隔的共11个测试时间标准。这样,模板库中有30个模板,测试语音有270个,使用微机配置是:CPU Pentium 2.0 GHz,内存512 MB。
在实验中,M和N取64,通过各模版间的匹配,确定了判决门限为0.3时,识别效果最佳。
为了对比DTW算法的识别性能,采用在传统说话人识别中广泛使用的GMM模型作为对比实验,其中GMM模型使用与DTW算法相同的编码流特征。
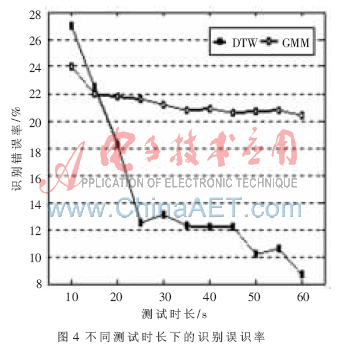
图4给出基于DTW识别方法与GMM模型(混元数64)识别G.729编码方案863语料库的文本相关说话人的误识率对比图。横坐标代表的测试语音的时长,纵坐标代表识别误识率。由实验结果可知在文本相关的说话人识别中,基于DTW算法的识别率在绝大多数情况下高于GMM模型,且随着测试语音的增长,优势更明显。
为比较特征提取的时间性能和总的时间性能,实验条件如下:
(1)选择的50个说话人的语音只进行特征提取,测试语音长度总和在25 min左右;
(2)对测试语音分别进行解码识别和编码流的识别,模板数为10个;
(3)微机配置为:CPU Pentium 2.0 GHz,内存512 MB。
表1为特征提取时间比较结果,表2为说话人识别时间比较结果。

由实验结果可以看出,在编码比特流中进行特征提取时间和识别的(上接第121页)
时间都远小于解码重建后的语音特征提取时间和识别时间,满足实时说话人识别的需要。
在文本相关的说话人识别中,对比使用同样G.729压缩码流特征的GMM模型, DTW方法的识别率和处理效率均高于GMM模型,能够实时应用于VoIP网络监管中。
为测试上述识别性能,对其进行了固定文本的说话人识别试验。试验中,采用电话信道863语料库30个说话人共300个录音文件,文件格式为16 bit线性PCM。为了模拟VoIP中语音压缩帧,使用G.729声码器对原始语音文件进行压缩。使用每个说话人的一个文件训练成为模板。测试语音长度为10 s~60 s以5 s为间隔的共11个测试时间标准。这样,模板库中有30个模板,测试语音有270个,使用微机配置是:CPU Pentium 2.0 GHz,内存512 MB。
在实验中,M和N取64,通过各模版间的匹配,确定了判决门限为0.3时,识别效果最佳。
为了对比DTW算法的识别性能,采用在传统说话人识别中广泛使用的GMM模型作为对比实验,其中GMM模型使用与DTW算法相同的编码流特征。
图4给出基于DTW识别方法与GMM模型(混元数64)识别G.729编码方案863语料库的文本相关说话人的误识率对比图。横坐标代表的测试语音的时长,纵坐标代表识别误识率。由实验结果可知在文本相关的说话人识别中,基于DTW算法的识别率在绝大多数情况下高于GMM模型,且随着测试语音的增长,优势更明显。
为比较特征提取的时间性能和总的时间性能,实验条件如下:
(1)选择的50个说话人的语音只进行特征提取,测试语音长度总和在25 min左右;
(2)对测试语音分别进行解码识别和编码流的识别,模板数为10个;
(3)微机配置为:CPU Pentium 2.0 GHz,内存512 MB。
表1为特征提取时间比较结果,表2为说话人识别时间比较结果。
由实验结果可以看出,在编码比特流中进行特征提取时间和识别的(上接第121页)
时间都远小于解码重建后的语音特征提取时间和识别时间,满足实时说话人识别的需要。
在文本相关的说话人识别中,对比使用同样G.729压缩码流特征的GMM模型, DTW方法的识别率和处理效率均高于GMM模型,能够实时应用于VoIP网络监管中。
- 便携式BD播放机系统的设计(05-24)
- 基于单片机AT89C51SND1C的MP3方案设计(07-24)
- 应用处理器连接汽车和消费电子两大领域(02-26)
- 基于MSP430单片机的低功耗主动式RFID标签设计(06-12)
- 基于Blackfin的图像处理,及其性能与CMOS传感器中ISP的比较(08-25)
- TI高管详解收购Luminary Micro的MCU业务态势(07-23)