基于H.323高性能MCU的设计与实现
时间:11-28
来源:互联网
点击:
2.2 MP部分总体设计思想
基于软交换的MP,通过帧缓冲映射算法查找终端对应的缓冲区,然后把接收到的音、视频流存放到该缓冲区里面,通过MC的控制,把音、视频数据流转发到终端。由于MCU需要处理大量的实时RTP包,效率成为了最主要的问题。因此如何从缓冲区里面快速搜索相应的数据包是MP能否快速处理数据的关键。考虑到MP要处理不同的终端,不同的终端对应不同的缓冲区,所以采用哈希函数映射法,它将任意长度的二进制值映射为固定长度的较小二进制值,并把这个哈希表存放到相应的内存区,以便多次的查找,这样通过这个较小的二进制值就可以以非常快的速度找到比较大的数值。因此把视频缓冲区的首地址存放到一个哈希表里面,并通过这个哈希表把终端的Token映射于这个缓冲区,这样通过终端的惟一TOken便可以迅速找到其对应的缓冲区。
实现MP部分帧缓冲映射算法的具体设计步骤是:首先MCU把登陆的在线终端Token(终端的惟一标识)与会议ID默认为roomlol,通过哈希函数,映射到一个缓冲区,通过终端的Token和会议ID,就可以直接找到本终端的缓冲区,当MP收到终端的RTP包后,通过RTP包的边界分析,把多个RTP合成一个数据帧,然后把数据帧放到相应的终端缓冲区里面。帧缓冲映射的查找如图6所示。假设当终端A要求转发终端B的音、视频数据流时,MP通过哈希函数找到相应终端B的缓冲区域,然后把该缓冲区的数据读出到数据帧里面,最后通过RTP包进行发送到终端A,而终端A在接收到MCU发送的终端B的音视频数据压缩包后,再对其进行音视频进行解码。

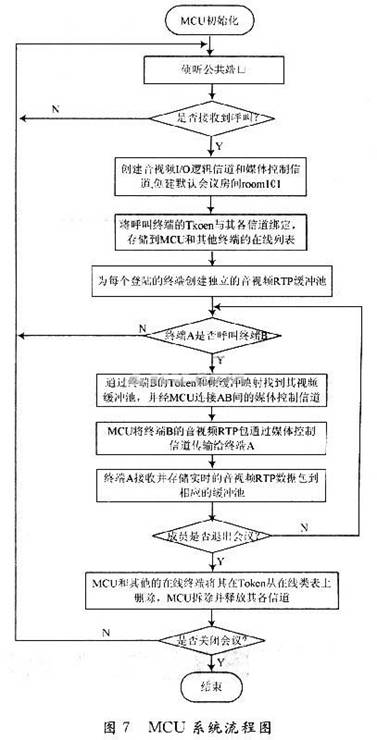
2.3 MCU系统实现
根据以上的设计思想,得出如图7所示的MCU系统流程图。
2.4 测试结果与结论
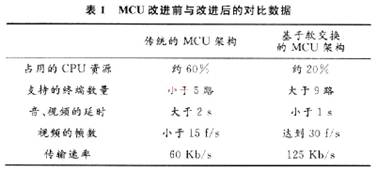
通过重新设计MCU的MC和MP后,MCU的性能有了较大的提高。从性能方面进行测试,由于传统的MCU在MC上进行编解码,只能容纳4路音、视频终端,而通过修改的MCU,MC没有进行编解码,只对音、视频进行存储转发,因此在9路音、视频的情况下,系统的CPU只占有5%。从效率、质量方面进行比较,由于传统的MCU进行了4路编解码,返回到终端的数据包延迟比较大,而修改过的MCU没有进行到编解码,因此数据包的延时很小。传统的MCU在MC里面进行图像的混合,图像的分辨率变为原来的1/4,因此图像质量有较大的下降,而基于软交换的MCU保持了原来图像的分辨率,因此图像质量较好。从视频的帧数来比较,传统的MCU架构不能达到15 f/s,而基于软交换的MCU能达到30 f/s。由于基于软交换的MCU的视频传输的是原来图像的分辨率,因此传输率比传统的MCU要高,但可以通过在终端采用传输率较低的编码器来降低传输率。表1为MCU改进前与改进后的对比。
终端的6分界面如图8所示。
3 结语
从以上的测试证明,基于软交换的MCU架构,使MCU的性能有了很大的提高。本文同时也说明了只要系统程序设计合理,基于软件的MCU是切实可行的。随着硬件水平的不断提高,纯软件的MCU将以其低成本、简易操作而普及到低端用户。
基于软交换的MP,通过帧缓冲映射算法查找终端对应的缓冲区,然后把接收到的音、视频流存放到该缓冲区里面,通过MC的控制,把音、视频数据流转发到终端。由于MCU需要处理大量的实时RTP包,效率成为了最主要的问题。因此如何从缓冲区里面快速搜索相应的数据包是MP能否快速处理数据的关键。考虑到MP要处理不同的终端,不同的终端对应不同的缓冲区,所以采用哈希函数映射法,它将任意长度的二进制值映射为固定长度的较小二进制值,并把这个哈希表存放到相应的内存区,以便多次的查找,这样通过这个较小的二进制值就可以以非常快的速度找到比较大的数值。因此把视频缓冲区的首地址存放到一个哈希表里面,并通过这个哈希表把终端的Token映射于这个缓冲区,这样通过终端的惟一TOken便可以迅速找到其对应的缓冲区。
实现MP部分帧缓冲映射算法的具体设计步骤是:首先MCU把登陆的在线终端Token(终端的惟一标识)与会议ID默认为roomlol,通过哈希函数,映射到一个缓冲区,通过终端的Token和会议ID,就可以直接找到本终端的缓冲区,当MP收到终端的RTP包后,通过RTP包的边界分析,把多个RTP合成一个数据帧,然后把数据帧放到相应的终端缓冲区里面。帧缓冲映射的查找如图6所示。假设当终端A要求转发终端B的音、视频数据流时,MP通过哈希函数找到相应终端B的缓冲区域,然后把该缓冲区的数据读出到数据帧里面,最后通过RTP包进行发送到终端A,而终端A在接收到MCU发送的终端B的音视频数据压缩包后,再对其进行音视频进行解码。
2.3 MCU系统实现
根据以上的设计思想,得出如图7所示的MCU系统流程图。
2.4 测试结果与结论
通过重新设计MCU的MC和MP后,MCU的性能有了较大的提高。从性能方面进行测试,由于传统的MCU在MC上进行编解码,只能容纳4路音、视频终端,而通过修改的MCU,MC没有进行编解码,只对音、视频进行存储转发,因此在9路音、视频的情况下,系统的CPU只占有5%。从效率、质量方面进行比较,由于传统的MCU进行了4路编解码,返回到终端的数据包延迟比较大,而修改过的MCU没有进行到编解码,因此数据包的延时很小。传统的MCU在MC里面进行图像的混合,图像的分辨率变为原来的1/4,因此图像质量有较大的下降,而基于软交换的MCU保持了原来图像的分辨率,因此图像质量较好。从视频的帧数来比较,传统的MCU架构不能达到15 f/s,而基于软交换的MCU能达到30 f/s。由于基于软交换的MCU的视频传输的是原来图像的分辨率,因此传输率比传统的MCU要高,但可以通过在终端采用传输率较低的编码器来降低传输率。表1为MCU改进前与改进后的对比。
终端的6分界面如图8所示。
3 结语
从以上的测试证明,基于软交换的MCU架构,使MCU的性能有了很大的提高。本文同时也说明了只要系统程序设计合理,基于软件的MCU是切实可行的。随着硬件水平的不断提高,纯软件的MCU将以其低成本、简易操作而普及到低端用户。
- 音响系统的USB接口开发分析及主流芯片比较 (02-01)
- 让DSP成为创新的不竭源泉(03-08)
- 基于双星定位的4G监控报警系统设计(06-29)
- 可重定目标的嵌入式集成开发平台设计(08-03)
- 基于U盘和单片机的FPGA配置(08-25)
- 基于FPGA的液晶显示控制器设计(02-17)