一种改进的Wallace树型乘法器的设计
时间:10-26
来源:互联网
点击:
改进的Wallace树型乘法器结构及性能比较
对于32位乘法来说,符号数相乘时,基4 Booth编码形成16个编码项,并由此产生16个部分积;无符号数相乘时,编码项与部分积各多出一个。此外,在目前CPU指令集的设计中,乘加/减(C±A×B)指令已被广泛采用。所以,在一次乘法运算中,加法阵列中需要相加的部分积最多达到18个。而部分积个数对阵列结构的设计有着重大的影响,进而也就影响了布局布线的复杂度以及阵列的延迟级数。这一点在上文对图1中各个阵列结构的分析中,可以得到很好的证明。
为了解决图1中各结构在对部分积求和过程中存在的树型结构对称性不好、规整性差、布局布线复杂度高,以及关键路径延时不必要增加等问题,本文基于传统的Wallace树型结构,对其做出了改进,提出如图5所示的树型阵列结构。
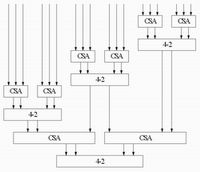
图5 CSA与4-2压缩器相结合的树型阵列结构
此结构中,采用CSA和4-2压缩器共同作为基本加法单元,对18个部分积进行压缩。其具体过程为:先采用CSA对18个部分积做第一次压缩,产生12个中间结果,再采用4-2压缩器进行第二次压缩,然后再分别采用CSA和4-2压缩器对第二个中间结果和随后产生的4个中间结果做压缩,得到最终的两个伪和,送入进位传播加法器得到最终结果。该结构通过在第一次和第三次压缩中采用CSA,使得最初的18个部分积和用4-2压缩器进行第二次压缩产生的6个中间结果能够同时得到处理,使各条路径在时延上达到平衡,相比于只采用4-2压缩器作为基本加法单元的阵列,这就节省了不必要的等待时间。与此同时,用两级CSA取代两级4-2压缩器,也使得关键路径的延时有了明显的缩短,对高速集成电路设计有着很高的实用价值。
此外,由图5可以看出,此结构具有较好的对称性和规整性,宏模块数量少,有利于布局布线。同时,对于目前指令集设计中常用的乘法指令,该结构对硬件的利用率也是相当高的。概括地说,该结构保持了传统Wallace树型结构求和速度快的优点,又较好地改进了原来那种由单一加法单元构成的阵列的不足。
为了比较该结构与图1所示各结构阵列的面积,本文在90nm工艺下采用全定制设计方法,利用Cadence的版图工具Virtuoso对各种情况进行了比较。另外,采用经过4-2压缩器级数度量关键路径的时延,不考虑互连延时,再通过AT2标准做了进一步的比较,结果如表2所示。(其中由表1数据可得,1级CSA延时≈0.7级4-2压缩器延时。
表2 各种结构的比较
阵列结构 面积A(μm2) 延时T(4-2级数) AT2 用Wallace树归一化
IA阵列 0.03628 2.3168 3.3
Wallace树 0.0437 4 0.6992 1
一阶OS树 0.0402 40.6432 0.92
参考文献 0.04144 0.66240.95
结构
本文提出 0.0418 3.40.4832 0.69
结构
结语
采用CSA与4-2压缩器相结合的电路,在对部分积的求和过程中对硬件达到了最为高效的利用。同时,这种结构既发挥了CSA版图面积小的优点,又体现了4-2压缩器压缩比高、速度快的长处,因此,与其他结构相比,本文提出的改进结构在面积和速度上都达到了相对理想的效果。虽然其在布局布线上有一定的复杂度,但与传统的Wallace树相比,已取得了颇为可观的改进。目前,该结构乘法器的版图设计工作已基本完成,并被用于正在进行的64位高性能嵌入式CPU设计的项目中,预计于2007年3月进行流片。
对于32位乘法来说,符号数相乘时,基4 Booth编码形成16个编码项,并由此产生16个部分积;无符号数相乘时,编码项与部分积各多出一个。此外,在目前CPU指令集的设计中,乘加/减(C±A×B)指令已被广泛采用。所以,在一次乘法运算中,加法阵列中需要相加的部分积最多达到18个。而部分积个数对阵列结构的设计有着重大的影响,进而也就影响了布局布线的复杂度以及阵列的延迟级数。这一点在上文对图1中各个阵列结构的分析中,可以得到很好的证明。
为了解决图1中各结构在对部分积求和过程中存在的树型结构对称性不好、规整性差、布局布线复杂度高,以及关键路径延时不必要增加等问题,本文基于传统的Wallace树型结构,对其做出了改进,提出如图5所示的树型阵列结构。
图5 CSA与4-2压缩器相结合的树型阵列结构
此结构中,采用CSA和4-2压缩器共同作为基本加法单元,对18个部分积进行压缩。其具体过程为:先采用CSA对18个部分积做第一次压缩,产生12个中间结果,再采用4-2压缩器进行第二次压缩,然后再分别采用CSA和4-2压缩器对第二个中间结果和随后产生的4个中间结果做压缩,得到最终的两个伪和,送入进位传播加法器得到最终结果。该结构通过在第一次和第三次压缩中采用CSA,使得最初的18个部分积和用4-2压缩器进行第二次压缩产生的6个中间结果能够同时得到处理,使各条路径在时延上达到平衡,相比于只采用4-2压缩器作为基本加法单元的阵列,这就节省了不必要的等待时间。与此同时,用两级CSA取代两级4-2压缩器,也使得关键路径的延时有了明显的缩短,对高速集成电路设计有着很高的实用价值。
此外,由图5可以看出,此结构具有较好的对称性和规整性,宏模块数量少,有利于布局布线。同时,对于目前指令集设计中常用的乘法指令,该结构对硬件的利用率也是相当高的。概括地说,该结构保持了传统Wallace树型结构求和速度快的优点,又较好地改进了原来那种由单一加法单元构成的阵列的不足。
为了比较该结构与图1所示各结构阵列的面积,本文在90nm工艺下采用全定制设计方法,利用Cadence的版图工具Virtuoso对各种情况进行了比较。另外,采用经过4-2压缩器级数度量关键路径的时延,不考虑互连延时,再通过AT2标准做了进一步的比较,结果如表2所示。(其中由表1数据可得,1级CSA延时≈0.7级4-2压缩器延时。
表2 各种结构的比较
阵列结构 面积A(μm2) 延时T(4-2级数) AT2 用Wallace树归一化
IA阵列 0.03628 2.3168 3.3
Wallace树 0.0437 4 0.6992 1
一阶OS树 0.0402 40.6432 0.92
参考文献 0.04144 0.66240.95
结构
本文提出 0.0418 3.40.4832 0.69
结构
结语
采用CSA与4-2压缩器相结合的电路,在对部分积的求和过程中对硬件达到了最为高效的利用。同时,这种结构既发挥了CSA版图面积小的优点,又体现了4-2压缩器压缩比高、速度快的长处,因此,与其他结构相比,本文提出的改进结构在面积和速度上都达到了相对理想的效果。虽然其在布局布线上有一定的复杂度,但与传统的Wallace树相比,已取得了颇为可观的改进。目前,该结构乘法器的版图设计工作已基本完成,并被用于正在进行的64位高性能嵌入式CPU设计的项目中,预计于2007年3月进行流片。
电路 Mentor 仿真 集成电路 Cadence 嵌入式 相关文章:
- 整流电路(11-30)
- 单运放构成的单稳延时电路(11-29)
- 直流稳压电源电路(11-30)
- 基于ISP1581型接口电路的USB2.0接口设计(01-18)
- 单电源供电的IGBT驱动电路在铁路辅助电源系统中的应用(01-16)
- 为太阳能灯供电的低损耗电路的设计(01-22)