采用TI多标准基站SoC全面提升性能
处理 -- 为在 L2 内实现进一步处理而进行的通道解调、解多路复用、错误校正与解码。

图2 - PUSCH 信号处理链
分析 TMS320TCI6488 中的 LTE 物理层处理 4
TCI6487/8 是 TI 最新系列的多内核 SoC,由三个 C64x+TM CPU 内核构成。采用这种 SoC 的运营商已有数百家,年出货量数百万片。通过分析 TCI6488 的 LTE 性能,可以深入了解如何构建新一代的高性能 SoC。图 3 所示为在 TCI6488 上采用 2x2 MIMO、150Mbps 下行吞吐速率及 75Mbps 上行吞吐速率时,20 MHz LTE 的周期占用数及分布。

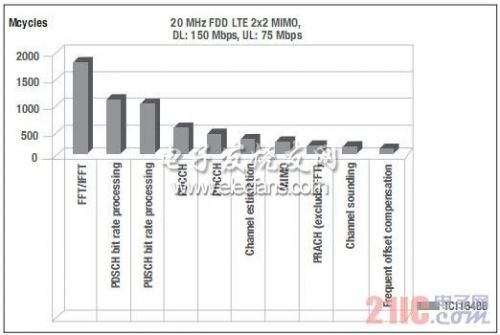
图 3 - TCI6488 上的 LTE 物理层处理
从图上可以明显看出,FFT/IFFT、PDSCH 比特率处理、PUSCH 比特率处理与 PUCCH 占用了总 DSP 周期中的大部分。
为进一步改进总体系统性能,满足新一代 LTE 系统的要求,必须设计出具备良好均衡性且可扩展的架构,以便最大限度地发挥 SoC 的多内核计算性能。这就要求最大限度地提高系统的互连吞吐量,并将存储器存取与数据传输时延降到最小。
通过对 LTE 要求的总处理周期进行分析,我们发现通过增强 DSP 内核的信号处理能力,不仅能够减少处理周期的总数量,而且还能增大系统容量、提升性能。最新推出的 C66x DSP 内核通过将 C64x+ 的乘/累加 (MAC) 能力锐升四倍可实现这一目标。此外,新内核还同时集成了定点与浮点功能,并可为矢量处理与矩阵处理提供新的指令。
如快速傅里叶变换 (FFT) 与快速傅里叶逆变换 (IFFT) 等特定函数需要在 LTE 信号链上的许多地方执行,并且用于在时域与频域之间进行数据转换。FFT 与离散傅立叶变换 (DFT) 已属成熟算法,因此它们有可能作为硬件加速的候选以用于释放 CPU 周期,这样 DSP 内核就可用于执行客户差异化功能。
5
LTE 的上行与下行比特率处理及其他无线技术包含众多标准算法,适用于调制、解调、交错、解交错、速率匹配、解速率匹配、加扰与去扰等运算。TI 新型比特率协处理器 (BCP) 是一种可为多种标准释放所有比特率处理功能的加速器,它可大幅度提升系统容量,从而简化软件编程、减少系统时延。
这些就是可以在 TCI6616 及 TCI6618 基站 SoC 中实现创新与性能飞跃提升的系统优化机会的示例。
TI KeyStone 架构
KeyStone 多内核 SoC 架构是业界同类架构中率先可提供基础局端以确保所有内核都能得到充分利用的架构。KeyStone 可实现对所有处理内核、外设、协处理器及 I/O 的非阻塞访问。可实现这类多内核能力的部分 KeyStone 创新技术包括:多内核导航器、TeraNet、多内核共享存储控制器 (MSMC) 及超链接。
TI 多内核导航器是一种基于分组的创新型管理器,能够在提取不同子系统间连接的同时,控制 8,192 个队列。它可为实现通信、数据传输及工作管理提供统一接口。通过采用"一次性完成,零复制"的设计理念,多内核导航器能够以更少的中断及更低的软件复杂度实现更高的系统性能。
举例来说,多内核导航器能够进行任务调度,且在无需外部管理的情况下即能指示下一个空闲 DSP 内核读取并处理任务。这样通过提供下列功能,即可简化 SoC 软件架构,进而提升基站的性能:
动态资源/负载共享
减轻与子系统间通信相关的 CPU 开销/延迟
基于硬件的任务优先级排序
动态负载平衡
针对所有 IP 模块(软件、I/O 及加速器)的通用通信方法
多内核导航器能够在无 CPU 干预的情况下控制数据流,可从移动数据中释放 CPU 周期并将片上通信速率提升至每秒 2,000 万条消息。此外,其还能够使用更为简单的软件架构以缩短开发周期并提高资源利用率。
TeraNet 能够提供层级交换结构,可在 SoC 内为数据传输提供超过 2 Tbit 的总带宽。这样几乎可确保不会出现内核与协处理器没有数据可处理的情况,从而使他们在任何需要的位置和时间都可以发挥其最大的处理功效。由于交换结构采用了层级架构而非扁平纵横式结构,因此总体功耗能在空闲状态下实现大幅度下降且能以最低时延实现高性能,从而充分满足新一代基站的这种关键要求。
多内核共享存储控制器 (MSMC) 是一种可增强性能的独特架构。MSMC 可以让内核在不占用任何 TeraNet 带宽的情况下直接访问共享存储器。MSMC 可以协调内核及其他 IP 模块对共享存储器的访问,以避免发生存储器争用的情况发生。DDR3 外部存储器接口 (EMIF) 可直接连接至 MSMC,从而降低因发生外部存储器存取而导致的时延,并为基站应用提供所需的高速访问与支持。
6
超链接具有 50Gbps 的总吞吐能力,是一种互连机制,能够以极少的协议实现与其它 KeyStone、FPGA 及 ASIC 器件的高速通信与连接。其可为主器件上的配套器件提供透明的存储器映射
- TI TRF2443宽带无线IF收发方案(07-07)
- Hittite HMC792LP4E DC-6 GHz数字衰减方案(07-26)
- Hittite HMC713LP3E 50MHz-8GHz 功率检测方案(07-26)
- 高精度宽带锁相环HMC830LP6GE(10-06)
- Multisim 10在差动放大电路分析中的应用(02-15)
- 5G--下一波人物互联的新浪潮(07-07)