G.723.1语音编码算法的DSP实现
时间:05-25
来源:互联网
点击:
随着通信、计算机网络等技术的飞速发展,日益增加的客户需求量和现有的通信信道容量之间的矛盾愈发突出。如何在有限的信道资源下,通过压缩信源以提高传输效率已成为当前急需解决的问题之一。为此诞生了许多语音压缩处理方法,G.723.1语音编码算法便是ITU-T(国际电信联盟电信标准化部门)制定的H.324协议簇首推的标准算法,主要用于低比特率多媒体业务的话音或其他音频信号分量的压缩。它是一种双速率语音编码标准,其中6.3 kb/s的速率提供了良好的话音质量,而5.3kb/s的速率在提供较好通话质量的同时,也为系统设计者提供了更适合的灵活性[1]。
1 算法原理
G.723.1语音编码算法按帧(Frame)对语音数据进行压缩和解压缩,每帧240个采样点,压缩传递的参数包括线性预测系数、自适应码本的延时和增益、激励脉冲位置、符号及格点比特等。
首先进行高通滤波,去掉直流分量;接着把一帧信号分成4个子帧,每个子帧60个采样点,分别进行10阶线性预测分析(LPC),得到各子帧的LPC参数,把最后一个子帧的LPC参数转化成线谱对(LSP)参数进行矢量量化编码,送到解码器。利用未量化的LPC参数构造短时感知加权滤波器,信号滤波后得到感觉加权的语音信号。每2个子帧(120样点)搜索一个开环基音值,并以此为依据为每一个子帧构造一个谐波噪声成形滤波器,对感知加权的语音信号进行滤波。每一子帧的LPC综合滤波器、感觉加权滤波器和谐波噪声成形滤波器联起来,构成一个联合滤波器,利用它的冲激响应和开环基音周期,对每一子帧进行闭环基音搜索,对开环搜索的结果进行修正。同时通过一个五阶基音预测器对信号进行预测,得到相应子帧的残差信号。最后进行固定码本搜索,也就是对每一子帧的残差信号进行矢量量化,对应两种不同的编码速率采用两种不同的方法:编码速率为6.3kb/s时,采用多脉冲最大似然量化(MP-MLQ)的方法,具有较高的重建语音质量;编码速率为5.3kb/d时,采用代数码本激励线性预测(ACELP)方法。
算法的解码也是按帧进行,主要对符合ITU-TG.723.1的码流进行解码,得到相应的参数,根据语音产生的机理,合成语音信号。读入一帧码流后,分别进行LSP参数、基音周期和激励脉冲信号解码,对LSP参数插值,然后转化成各子帧的线性预测系数,构成LPC综合滤波器。通过基音周期和激励脉冲得到每一子帧的残差信号,经过基音后滤波,输入到LPC综合滤波器,产生合成语音信号。经过共振峰后滤波和增益控制,形成高质量的重建语音信号。
2 算法实现
2.1 硬件设计
在选择DSP芯片时,考虑了语音压缩编码算法的复杂度以及运算量,并对DPS芯片本身的运算能力、存储空间大小、性能价格比、开发软件的完整性等多方面进行综合比较,最终选用TIC54xx系列的定点运算处理器TMS320C5416,开发平台是TMS320C5416 DSK。
TMS320C5416的单指令周期为6.25ms,每秒执行的指令数为160M,使用了6级指令流水线结构,这些都很适合G.723.1语音编码算法的实现。采用一个40 bitALU、128K×16 bit片内RAM(包括64 kB的片内DARAM和64 KB的片内SARAM)、3个独立的16bit数据内存总线、1个程序内存总线、3个McBSP、6信道DMA控制器、1个8/16 bit并行增强主机端口接口及2个16 bit计时器[2,3]。
在DSK的基础上,可以搭建出语音开发硬件系统平台,如图1所示。
输入语音信号由麦克风输入,经过立体声音频多媒体数字信号编码芯片PCM3002 A/D转换后成为数字信号,接着送入DSP内进行编码压缩处理。处理后的数据经过解压得到重建的语音信号,最后送入PCM3002 D/A转换为模拟信号,通过耳机或扬声器得以收听到。
2.2 算法实现流程
根据G.723.1算法,设计实现流程如图2所示。
从流程图中可以看到,首先关闭中断、初始化DSP芯片和开发平台;然后进行程序运行前的硬件配置,主要是配置外设,打开DMA和McBSP。配置结束后打开中断屏蔽控制寄存器,等待中断的到来。McBSP接收中断发生时,DMA接收PCM3002发来的数据并存入缓冲区,并判断是否满一帧240个数据。如果不满帧,就直接等待下一次McBSP接收中断;如果满一帧,通过DMA通道3将240个语音数据复制到缓冲区BUFF1,同时置位新帧标志位new_data,然后对数据进行编解码处理。整个编解码结束后,将得到的一帧240个合成语音数据复制到缓冲区BUFF2中,等待新帧标志位重新置1后进行下一帧的编解码处理。McBSP发送中断时,DMA把发送缓冲区的一个数据发送给PCM3002后,判断是否满一帧。如果不满帧,就直接等到下一次McBSP发送中断;如果满一帧,即PCM3002接收到了240个数据,则把BUFF2中新一帧240个合成语音数据复制到发送缓冲区,等待下一次McBSP发送中断。
1 算法原理
G.723.1语音编码算法按帧(Frame)对语音数据进行压缩和解压缩,每帧240个采样点,压缩传递的参数包括线性预测系数、自适应码本的延时和增益、激励脉冲位置、符号及格点比特等。
首先进行高通滤波,去掉直流分量;接着把一帧信号分成4个子帧,每个子帧60个采样点,分别进行10阶线性预测分析(LPC),得到各子帧的LPC参数,把最后一个子帧的LPC参数转化成线谱对(LSP)参数进行矢量量化编码,送到解码器。利用未量化的LPC参数构造短时感知加权滤波器,信号滤波后得到感觉加权的语音信号。每2个子帧(120样点)搜索一个开环基音值,并以此为依据为每一个子帧构造一个谐波噪声成形滤波器,对感知加权的语音信号进行滤波。每一子帧的LPC综合滤波器、感觉加权滤波器和谐波噪声成形滤波器联起来,构成一个联合滤波器,利用它的冲激响应和开环基音周期,对每一子帧进行闭环基音搜索,对开环搜索的结果进行修正。同时通过一个五阶基音预测器对信号进行预测,得到相应子帧的残差信号。最后进行固定码本搜索,也就是对每一子帧的残差信号进行矢量量化,对应两种不同的编码速率采用两种不同的方法:编码速率为6.3kb/s时,采用多脉冲最大似然量化(MP-MLQ)的方法,具有较高的重建语音质量;编码速率为5.3kb/d时,采用代数码本激励线性预测(ACELP)方法。
算法的解码也是按帧进行,主要对符合ITU-TG.723.1的码流进行解码,得到相应的参数,根据语音产生的机理,合成语音信号。读入一帧码流后,分别进行LSP参数、基音周期和激励脉冲信号解码,对LSP参数插值,然后转化成各子帧的线性预测系数,构成LPC综合滤波器。通过基音周期和激励脉冲得到每一子帧的残差信号,经过基音后滤波,输入到LPC综合滤波器,产生合成语音信号。经过共振峰后滤波和增益控制,形成高质量的重建语音信号。
2 算法实现
2.1 硬件设计
在选择DSP芯片时,考虑了语音压缩编码算法的复杂度以及运算量,并对DPS芯片本身的运算能力、存储空间大小、性能价格比、开发软件的完整性等多方面进行综合比较,最终选用TIC54xx系列的定点运算处理器TMS320C5416,开发平台是TMS320C5416 DSK。
TMS320C5416的单指令周期为6.25ms,每秒执行的指令数为160M,使用了6级指令流水线结构,这些都很适合G.723.1语音编码算法的实现。采用一个40 bitALU、128K×16 bit片内RAM(包括64 kB的片内DARAM和64 KB的片内SARAM)、3个独立的16bit数据内存总线、1个程序内存总线、3个McBSP、6信道DMA控制器、1个8/16 bit并行增强主机端口接口及2个16 bit计时器[2,3]。
在DSK的基础上,可以搭建出语音开发硬件系统平台,如图1所示。
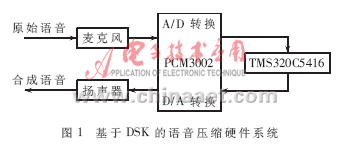
输入语音信号由麦克风输入,经过立体声音频多媒体数字信号编码芯片PCM3002 A/D转换后成为数字信号,接着送入DSP内进行编码压缩处理。处理后的数据经过解压得到重建的语音信号,最后送入PCM3002 D/A转换为模拟信号,通过耳机或扬声器得以收听到。
2.2 算法实现流程
根据G.723.1算法,设计实现流程如图2所示。
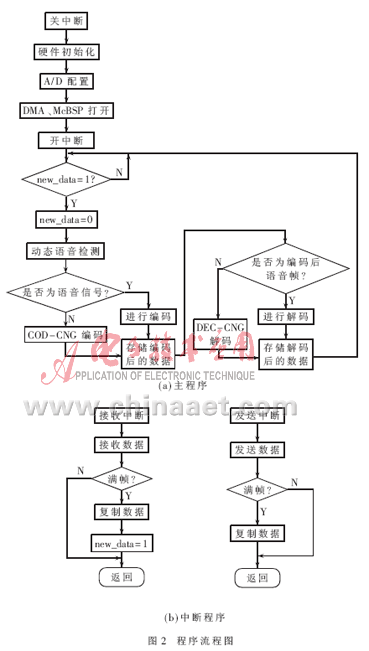
从流程图中可以看到,首先关闭中断、初始化DSP芯片和开发平台;然后进行程序运行前的硬件配置,主要是配置外设,打开DMA和McBSP。配置结束后打开中断屏蔽控制寄存器,等待中断的到来。McBSP接收中断发生时,DMA接收PCM3002发来的数据并存入缓冲区,并判断是否满一帧240个数据。如果不满帧,就直接等待下一次McBSP接收中断;如果满一帧,通过DMA通道3将240个语音数据复制到缓冲区BUFF1,同时置位新帧标志位new_data,然后对数据进行编解码处理。整个编解码结束后,将得到的一帧240个合成语音数据复制到缓冲区BUFF2中,等待新帧标志位重新置1后进行下一帧的编解码处理。McBSP发送中断时,DMA把发送缓冲区的一个数据发送给PCM3002后,判断是否满一帧。如果不满帧,就直接等到下一次McBSP发送中断;如果满一帧,即PCM3002接收到了240个数据,则把BUFF2中新一帧240个合成语音数据复制到发送缓冲区,等待下一次McBSP发送中断。
- H.264在动中通应急图像传输中的应用(10-27)
- 基于FPGA的并行可变长解码器的实现技术 (10-01)
- CDMA2000 1x增强型技术:将语音容量增至4倍(09-23)
- GPS软件接收机信号实时接收与传输技术(02-22)
- 利用FPGA实现HDB3编解码功能(03-16)
- 无线Mesh网视频监控系统的研究与开发(03-24)