ARM发布最新Compute Library
在关于 17.6 发行版的介绍中(Arm计算库第二个公开版本正式发布,这些厂商一直在用其进行开发!),Arm计划在 CPU 中支持用于机器学习的新架构功能,而第一步就是在 Armv8.2 CPU 中支持 FP16。目前,库中增加了面向 Armv8.2 FP16 的新函数:
-
激活层
-
算术加法、减法和乘法
-
批量归一化(Batch Normalization)
-
卷积层(基于 GEMM)
-
卷积层(Direct卷积)
-
局部连接
-
归一化
-
池化层
-
Softmax 层
虽然我们没有对这些函数做一些激进的优化(这些函数采用 NEON intrinsic而非手工优化的汇编语言编写),但与使用 FP32 且必须在不同格式之间转换相比,性能有了大幅提升。下表比较了一些工作负载,从中可以看出,借助 v8.2 CPU 指令,可以减少计算所需的周期数。
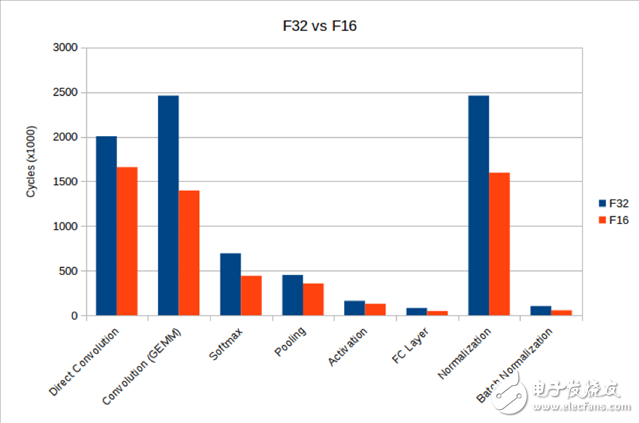
如今,许多移动合作伙伴正在利用 Mali GPU 来加快机器学习工作负载的速度。根据这些合作伙伴的反馈,我们在这个领域做了针对性的优化。
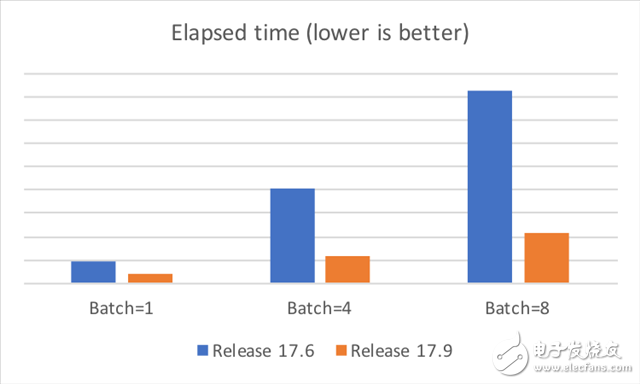
新的Direct卷积 3x3 和 5x5 函数针对 Bifrost 架构进行了优化,性能与上一发行版 (17.06) 中的例程相比有了显著提升。在部分测试平台上使用这些新例程时,我们发现性能普遍提高约 2.5 倍。此外,在 AlexNet 的多批量工作负载中,GEMM 中引入的新优化帮助我们获得了 3.5 倍的性能提升。性能因平台和实现方法而异,但总体而言,我们预计这些优化能够在 Bifrost GPU 上显著提升性能。
下图显示了在华为 Mate 9 智能手机上的一些测试结果,测试中禁用了 DVFS,取 10 次运行中最短的执行时间作为结果。由此可见,新例程在性能上优于旧版本。
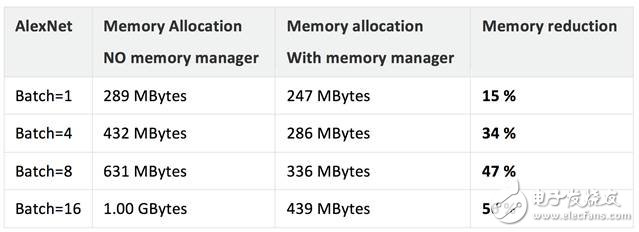
复杂工作负载(大型网络)会需要大量内存,对于嵌入式平台和移动平台而言,这正是影响性能的症结所在。我们听取了合作伙伴的反馈,决定在库的运行时组件中添加一个"内存管理器"功能。内存管理器通过循环利用临时缓冲区降低通用算法/模型的内存要求。
内存管理器包含一个生命周期管理器(用于跟踪注册对象的生命周期)和一个池管理器(用于管理内存池)。当开发人员配置函数时,运行时组件会跟踪内存要求。例如,一些张量可能仅仅是暂时的,所以只分配所需的内存。内存管理器的配置应从单一线程循序执行,以便提高内存利用率。
下表显示了在使用内存管理器时在我们测试平台上测量到的内存节省情况。结果因平台、工作负载和配置而异。总体而言,我们认为内存管理器能够帮助开发人员节省内存。

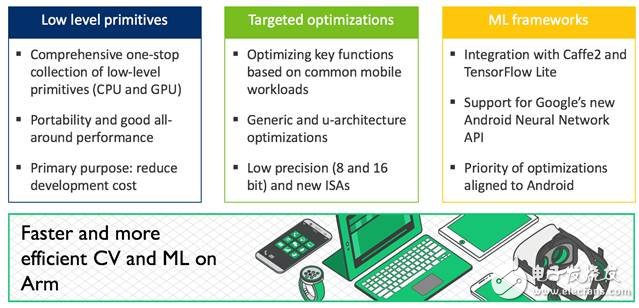
接下来,我们计划继续根据合作伙伴和开发人员的需求,进行具体的优化。此外,我们还将重视与机器学习框架的集成,并与 Google Android NN 等新的 API 保持同步。

我们的目标不是涵盖所有数据类型和函数,而是根据开发人员和合作伙伴的反馈,精选出最需要实施的函数。所以,我们期待着听到您的声音!
arm 相关文章:
- 基于ARM+FPGA的大屏幕显示器控制系统设计(06-30)
- 基于ARM和μC/OS-II的车载定位终端的设计(06-24)
- 解读物联网时代下的ARM mbed 操作系统(05-03)
- 用ARM和FPGA搭建神经网络处理器通信方案(07-19)
- ARM新一代Cortex-A73架构解析 千元机也能有高端SoC(05-06)
- 阿里巴巴将大量采用ARM处理器 Intel怎么办?(11-14)