设计一个信息管理系统,你需要知道这些
即将分组数为250看作一个大小为250的表格,每个表项可以存储40个学生记录的数组,通过db_id_to_idx()函数找到关键字学号ID对应在该表中的位置。其中,大小为250的表格就是"哈希表",详见图3.24。db_id_to_idx()函数就是"哈希函数",哈希函数的结果(分组索引)称之为"哈希值"。

图3.24 哈希
哈希表的核心工作在于哈希函数的选择,将查找的关键字送给哈希函数产生一个哈希值,哈希函数的选择直接决定了记录的分布,必须尽可能地确保所有记录均匀地分布在各个组中。在上面的示例中,每个分组中都定义了大小相同的数组作为记录存储的空间。如果按照分组规则,能够确保恰好均匀地分布在各个分组中,这是最佳的。
而实际上学生记录是会变动的,可能增加或删除,则很难保证按照现在定义的分组规则,保证100%的完全平均。如果每个分组都使用大小相同的数组作为记录存储的空间,则可能会导致部分数组未存满,部分数组却存不下的情况,就会导致部分学生记录无处可存,造成严重的数据管理问题。
由于数组都是提前定义好大小的,动态性能差,而链表的动态性能更好,可以根据需要增加、删除结点,改变链表长度,因此可以使用链表管理学生记录,就算分布不均匀,也只存在链表长度的差异,不会出现数据存储不了的问题,其示意图详见图3.25。
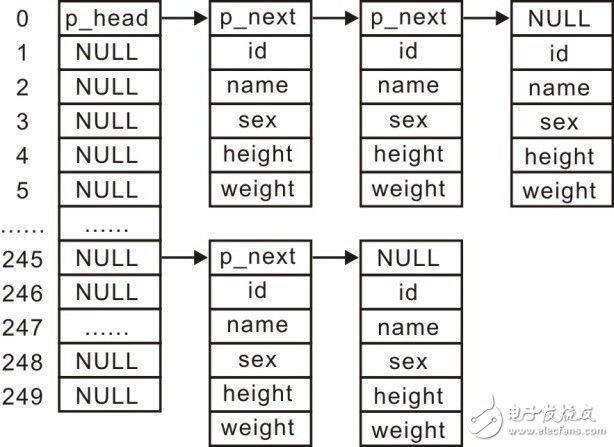
图3.25 链式哈希表
当使用链表管理学生记录时,哈希表每个表项的实际内容就是该组链表的表头。链表头结点的类型slist_head_t(slist.h)的定义如下:
typedef struct _slist_node{
struct _slist_node *p_next; // 向下一个结点的指针
}slist_node_t;
typedef slist_node_t slist_head_t;基于此,在哈希表的每个表项中存储一个slist_head_t类型的链表头结点即可,哈希表的定义如下:
typedef slist_head_t student_group_t;
student_group_t student_db[250];
根据对链式哈希表结构的分析,编写一个基于链式哈希表的信息管理系统,作为示例仅提供增加、删除、查找三种功能。当然,在使用这些功能前,还必须定义一个哈希表对象的类型,以便使用该类型定义具体的哈希表实例,进而使用各个功能接口对该实例进行操作。
>>>> 1.1.2 哈希表的类型
哈希表类型struct _hash_db定义如下:
typedef struct _hash_db hash_db_t;
在结构体中,需要包含哪些哈希表的相关信息呢?链式哈希表的核心是一个slist_head_t类型的数组,其大小与分组数目相关。为了通用,分组数目应由用户根据实际情况确定。slist_head_t类型的数组信息由一个指向数组首地址的slist_head_t*类型的指针和一个指定数组大小的size构成,哈希表结构体类型的定义如下:
struct _hash_db{
slist_head_t *p_head; // 指向数组首地址
unsigned int size; // 数组成员数
};在实际的应用中,信息可以是任意数据类型(void *),其次还需要知道该void *指针指向的记录的长度,比如,学生记录的长度是sizeof(student_t),因此更新哈希表结构体类型的定义如下:
struct _hash_db{
slist_head_t *p_head; // 指向数组首地址
unsigned int size; // 数组成员数
- 电源软启动的实用设计技巧(07-16)
- 周立功:动态分布内存——malloc()函数与calloc()函数(07-22)
- 周立功“程序设计与数据结构”:深度解剖动态分布内存的free()函数与realloc()函数(07-25)
- 周立功教你学程序设计技术:做好软件模块的分层设计,回调函数要这样写(07-30)
- 周立功教你学C语言编程:教你数组是如何保存指针的(07-31)
- 算法的泛化问题,这些坑你可能都经历过!|周立功教你学软件设计(08-01)