队列ADT,实现与使用接口
实现中,巧妙地避免了使用if语句判断rear和front的差值是否为负值,差值无论正负,都加上了MAXQSIZE(队列的容量大小)。此时,若差值为负值,则可以得到正确的结果,但若差值为正值,则结果会恰好多出MAXQSIZE,因此最后需要将结果对MAXQSIZE取余,以丢弃可能多出的MAXQSIZE,确保了结果的正确性。
2、链队列
在链队列中,各个数据的存储空间可以不连续,基于链表的队列(假定数据域为int类型)示意图详见图3.36。
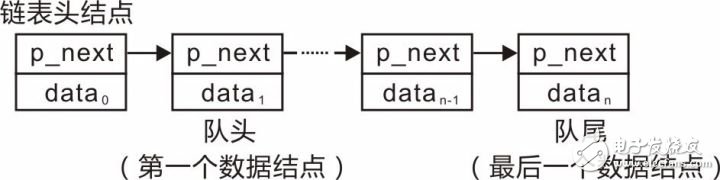
图3.36 链队列示意图
需要注意的是,链表头结点代表的是链表头,为了方便添加结点操作而定义的,不携带有效的应用数据。其后的结点才是有效结点,因此队头是第一个有效的数据结点,队尾是最后一个有效的数据结点。
入队列即将新元素添加至链表尾部,出队列就是移除第一个数据结点。这些操作在链表程序中都已经有相应的接口。因此基于之前的链表程序,实现链队列非常容易。在队列结构体中,仅需包含链表头结点,无需front、rear等成员。定义队列结构体类型为:

若队列中各个结点的数据类型为int类型,则对应的链表结点类型为:

如程序清单3.72所示为一种链队列的实现范例。
程序清单3.72 链队列的实现(queue_list.c)

对于大多数操作而言,链表都已经提供了相应的接口,因此入队列、出队列、判断满或空都非常容易。稍微复杂点的是得到队列中的元素个数,其需要遍历整个链表,每遍历到一个结点时,都将计数器count的值加1(count的地址通过遍历函数的p_arg参数传递),遍历结束后,计数器的值即为队列中的元素个数。
在入队列函数的实现中,每次都需要将新的结点添加至链表尾部,而对于单向链表,直接将结点添加至链表尾部的效率是非常低的,每次都需要从头开始遍历,直到找到最后一个结点,才能执行实际的添加操作。如何解决这个问题呢?最简单的办法是使用双向链表,但双向链表需要占用更多内存,同时,在队列的实现中,并不需要双向链表那么灵活,不需要随意的寻找上一个结点,显然,这里使用双向链表有点"小题大做"了。把握到一个核心的问题,就是需要将新结点添加至链表尾部,如果使用一个指针p_rear来指向尾结点,那么,添加结点至链表尾部时,可以直接将结点添加至p_rear指向的结点后面,无需再从头开始遍历链表,即"slist_add (p_head, p_rear, p_node);"。
添加结束后,新的p_node结点为新的尾结点,因此需要更新p_rear的值,使其指向新的尾结点,即"p_rear = p_node;"。p_rear可以作为队列结构体的一个成员,以便使用。读者可以按照这种方式,自行尝试修改入队列函数,提升入队列的效率。
对于使用者来讲,无需关心队列的具体实现方式。只要正确把握接口的使用方法(前置条件和后置条件),就可以编写使用队列的应用程序。将整数入队列,再出队列的范例程序详见程序清单 2.35。
程序清单3.73 使用队列接口的范例程序

- 电源软启动的实用设计技巧(07-16)
- 周立功:动态分布内存——malloc()函数与calloc()函数(07-22)
- 周立功“程序设计与数据结构”:深度解剖动态分布内存的free()函数与realloc()函数(07-25)
- 周立功教你学程序设计技术:做好软件模块的分层设计,回调函数要这样写(07-30)
- 周立功教你学C语言编程:教你数组是如何保存指针的(07-31)
- 算法的泛化问题,这些坑你可能都经历过!|周立功教你学软件设计(08-01)