算法与数据结构——哈希表
周立功教授数年之心血之作《程序设计与数据结构》以及《面向AMetal框架与接口的编程(上)》,书本内容公开后,在电子行业掀起一片学习热潮。经周立功教授授权,本公众号特对《程序设计与数据结构》一书内容进行连载,愿共勉之。
第三章为算法与数据结构,本文为3.5 哈希表。
>>>3.5.1 问题
假设需要设计一个信息管理系统,用于管理大约一万个学生的相关信息,可以通过学号查找到对应学生的信息,每条学生记录包含学号、姓名、性别、身高、体重等信息。即:

作为信息管理系统,首先要能够存储学生记录,这上万条记录如何存储呢?简单地,可以使用一段连续的内存存储学生记录,比如,使用一个大数组存储,每个数组元素都可以存储一条学生记录:
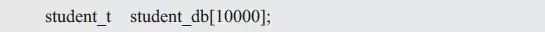
当使用数组存储学生信息时,如何通过学号查找相应的信息呢?如果学号编排是一种非常理想的情况,10000个学生的学号按照 0 ~ 9999顺序排列,则可以直接将学号作为数组的索引值查找相应的数组元素,其存储和查找的效率都非常高。但实际上学号往往不是如此简单编排的,一种常见的编排方法是"年级+专业代码+班级+班级内序号",比如,6字节学号为0x20, 0x16, 0x44, 0x70, 0x02, 0x39,即:201644700239,表示2016年入学,专业代码为4470(即计算机专业),2班的39号同学。
此时,通过学号查找学生信息的方法也很简单,直接从第一个学生记录开始,顺序遍历各个学生记录,将记录中的学号与期望查找的学生学号相比较,学号相同即查找到了相应学生的信息,详见程序清单3.61。
程序清单3.61 顺序查找范例程序

显然,如果采用顺序查找法,学生记录越多,则查找时需要比较的次数越多,效率也就越低。当学生记录的条数上万时,则可能需要比较上万次才能找到相应的学生信息。
如何以更高的效率实现查找呢?在理想情况下,若将学号作为数组索引存储数据,则查找的效率非常高。既然如此,如果扩大数组容量至学号的最大值加1(以包含学号0),则可以直接以学号作为数组的索引值。由于学号是由6字节组成的,因此数组必须能够容纳248条记录,需要占用多少存储空间呢?就算一条记录只占用一个字节,也需要262144 G存储空间,何况电脑硬盘没这么大!如果只使用其中的10000条记录,则剩下的(248-10000)空间就会造成极大的浪费,显然这种方式是不可取的。
在查找算法中,非常经典高效的算法是"二分法查找",按10000条记录算,最多也只需要比较14次(log210000)。但使用"二分法查找"的前提是信息必须有序排列,即要求学生记录必须按照学号的顺序存储,这就导致在添加或删除学生信息时,数据库存储的信息需要进行大量的移动操作。比如,数组中已经按照学号从小到大的顺序存储了9999条记录,现在写入第10000条记录,若该记录的学号最小,需要写入到所有记录的前面,这就需要将之前存储的9999条记录全部向后移动一次,以预留出首元素的空间,然后将新的学生记录写入首元素对应的空间中。由此可见,虽然使用这种方法可以提高查找效率,却牺牲了添加信息时的效率。
为了在添加信息时不进行大量的数据移动,能否换一种存储方式呢?比如,使用存储空间不连续的"单向链表"结构,将各个学生记录"链"起来,其示意图详见图3.23。
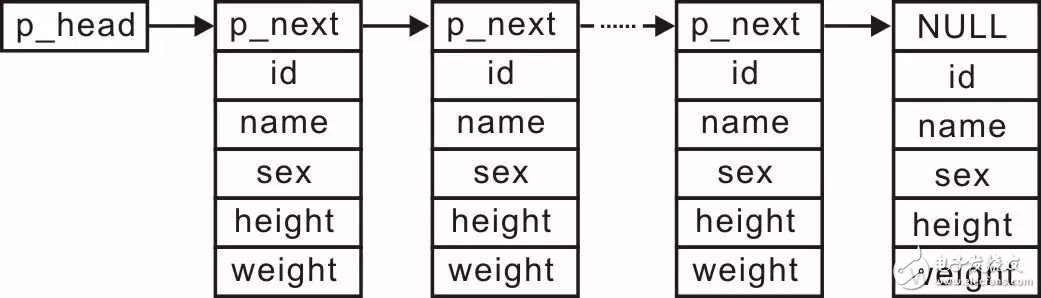
图3.23 使用单向链表管理学生记录
当使用链表管理学生记录时,实现有序排列只需每次插入新结点时,找到正确的插入位置,无需进行大量数据的移动。由于存储空间不连续,因此无法使用"二分法"查找学生信息,则实现有序排列也没有解决查找效率低下的问题,无论是否有序,查找时都需要从头开始顺序查找。
由此可见,使用"二分法查找"必须牺牲记录写入的效率以实现所有记录有序排列,使得写入记录的效率非常低。虽然基础的"顺序查找"对写入记录的效率完全不影响,但查找效率极为低下。因此,这两种情况都太极端了,要么选择极低的写入效率,要么选择极低的查找效率。何不将二者结合一下,以折中写入的效率和查找的效率呢?比如,将记录"二分"为两部分,使用两个数组来存储:
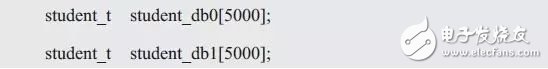
假设规定,学号小于某值(即201044700239)时,记录存储在student_db0中,反之,记录存储在student_db1中。如此一来,在写入记录时,只需要多一条判断语句,对性能并没太大影响。而在查找时,只要根据学号判断记录在哪一个数组中,即可按照顺序查找的方式查找。此时,查找需要比较的次数就从最大的10000次降低到了5000次。由此可见,通过一个简单的方法,将信息分别存储在两个数组中,就可以明
哈希表 相关文章:
- 周立功来讲解哈希表的实现(08-30)