从史前文明到女娲补天:Linux内存逆向映射(reverse mapping)技术的前世今生
,总结如下:
(1)等于NULL,表示该page frame不再内存中,而是被swap out到磁盘去了。
(2)如果不等于NULL,并且least signification bit等于1,表示该page frame是匿名映射页面,mapping指向了一个anon_vma的数据结构。
(3)如果不等于NULL,并且least signification bit等于0,表示该page frame是文件映射页面,mapping指向了一个该文件的address_space数据结构。
通过anon_vma数据结构,我们可以得到映射到该page的所有的VMA,至此,匿名映射和file mapped汇合,进一步解决的问题仅仅是如何从VMA到pte entry而已。上一节,我们描述了vma_address函数如何获取file mapped page的虚拟地址,其实anonymous page的逻辑是一样的,只不过vma->vm_pgoff和page->index的基础点不一样了,对于file mapped的场景,这个基础点是文件起始位置。对于匿名映射,起始点有两种情况,一种是share anonymous mapping,起点位置是0。另外一种是private anonymous mapping,起点位置是mapping的虚拟地址(除以page size)。但是不管如何,从VMA和struct page得到对应虚拟地址的算法概念是类似的。
六、卷土重来
full objrmap进入内核之后,看起来一切都很完美了,比起她的前任,Rik van Riel的rmap方案,objrmap各方面的指标都是全面碾压rmap。首次将逆向映射引入内核的大神Rik van Riel遭受了第二次的打击,不过他依然斗志昂扬并试图东山再起。
Objrmap虽然完美,不过晴朗的天空中飘着一朵乌云。大神Rik van Riel敏锐的看到了逆向映射的那朵"乌云",提出了自己的解决方案。本章主要描述新的anon_vma机制,代码来自4.4.6内核。
1、旧anon_vma机制有什么问题?
我们先一起来看看旧anon_vma机制下,系统是如何运作的。VMA_P是父进程的一个匿名映射的VMA,A和C都已经分配了page frame,而其他的page都还都没有分配物理页面。在fork之后,子进程copy了VMA_P,当然由于采用了COW技术,这时候父子进程的匿名页面会共享,同时在父子进程地址空间对应的pte entry中标注write protect的标记,如下图所示:
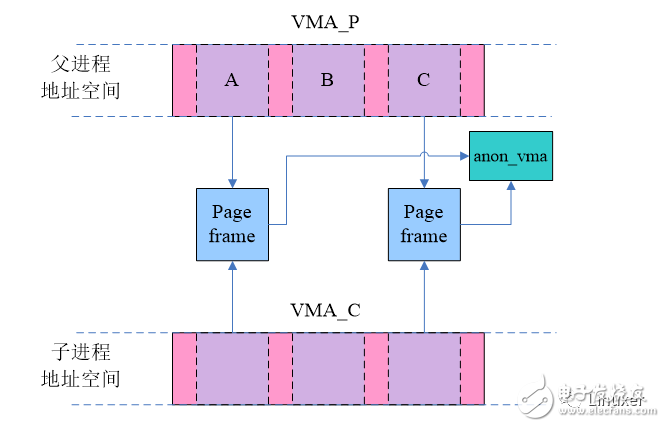
按理说不同进程的匿名页面(例如stack、heap)是私有的,不会共享,但是为了节省内存,在父进程fork子进程之后,父子进程对该页面执行写操作之前,父子进程的匿名页是共享的,所以这些page frame指向同一个anon_vma。当然,共享只是短暂的,一旦有write操作就会产生异常,并在异常处理中分配page frame,解除父子进程匿名页面的共享,具体如下图的page A所示:
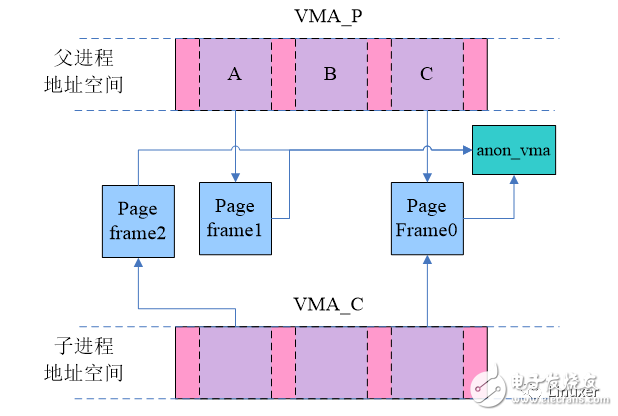
这时候由于写操作,父子进程原本共享的page frame已经不再共享,然而,这两个page却仍然指向同一个anon_vma,不仅如此,对于B这样的页面,一开始就没有在父子进程之间共享,当首次访问的时候(无论是父进程还是子进程),通过do_anonymous_page函数分配的page frame也是同样的指向一个anon_vma。也就是说,父子进程的VMA共享一个anon_vma。
在这种情况下,我们看看unmap page frame1会发生什么。毫无疑问,page frame1对应的struct page的mapping成员指向了上图中的anon_vma,遍历anon_vma会命VMA_P和VMA_C,这里面,VMA_C是无效的VMA,本来就不应该匹配到。如果anon_vma的链表没有那么长,那么整体性能也OK。然而,在有些网路服务器中,系统非常依赖fork,某个服务程序可能会fork巨大数量的子进程来处理服务请求,在这种情况下,系统性能严重下降。Rik van Riel给出了一个具体的示例:系统中有1000进程,都是通过fork生成的,每个进程的VMA有 1000个匿名页。根据目前的软件架构,anon_vma链表中会有1000个vma 的节点,而系统中有一百万个匿名页面属于同一个anon_vma。
这样的系统会导致什么样的问题呢?我们一起来看看try_to_unmap_anon函数,其代码框架如下:
static int try_to_unmap_anon(struct page *page)
{……
anon_vma = page_lock_anon_vma(page);
list_for_each_entry(vma, &anon_vma->head, anon_vma_node) {
ret = try_to_unmap_one(page, vma);
}
spin_unlock(&anon_vma->lock);
return ret;
}
当系统中的一个CPU在执行try_to_unmap_anon函数的时候,需要遍历VMA链表,这时会持有anon_vma->lock这个自旋锁。由于anon_vma存有了很多根本无关的VMA,通过,page table的检索过程,你就会发现这个VMA根本和准备unmap的page无关,因此只能scan下一个VMA,整个过程需要消耗大量的时间,延长了临界区(复杂度是O(N))。与此同时,其他CPU在试获取这把锁的时候,基本会被卡住,这时候整个系统的性能可想而知了。更加糟糕的是内核中并非只有unmap匿名页面的时候会上锁、遍历VMA链表,还有一些其他的场景也会这样(例如page_referenced函数)。想象一下,一百万个页面共享这一个anon_vma,对anon_vma-> 当系统中的一个
Linux 相关文章:
- 工控机在IC卡加油工程中的应用(05-13)
- 联网汽车为什么选择Linux开源平台?(07-10)
- 多网络和Linux代理的Android无线远程控制系统(02-02)
- 基于嵌入式Linux的家居监控系统设计(02-22)
- 基于嵌入式Linux系统的导航软件设计思路(03-17)
- 新型嵌入式机器视觉系统的设计研究(04-21)