从语言学到深度学习NLP,一文概述自然语言处理
们补充了北京理工大学的一篇论文。该论文回顾了 NLP 之中的深度学习重要模型与方法,比如卷积神经网络、循环神经网络、递归神经网络;同时还讨论了记忆增强策略、注意力机制以及无监督模型、强化学习模型、深度生成模型在语言相关任务上的应用;最后还讨论了深度学习的各种框架,以期从深度学习的角度全面概述 NLP 发展近况。
如今,深度学习架构、算法在计算机视觉、模式识别领域已经取得惊人的进展。在这种趋势之下,近期基于深度学习新方法的 NLP 研究有了极大增长。

图4:2012 年-2017 年,在 ACL、EMNLP、EACL、NAACL 会议上呈现的深度学习论文数量增长趋势。
十几年来,解决 NLP 问题的机器学习方法都是基于浅层模型,例如 SVM 和 logistic 回归,其训练是在非常高维、稀疏的特征上进行的。在过去几年,基于密集向量表征的神经网络在多种 NLP 任务上都产生了优秀成果。这一趋势由词嵌入与深度学习方法的成功所兴起。深度学习使得多层级的自动特征表征的学习成为了可能。传统的基于机器学习方法的 NLP 系统极度依赖手写特征,既耗费时间,又总是不完整。
在 2011 年,Collobert 等人的论文证明简单的深度学习框架能够在多种 NLP 任务上超越最顶尖的方法,比如在实体命名识别(NER)任务、语义角色标注 (SRL)任务、词性标注(POS tagging)任务上。从此,各种基于深度学习的复杂算法被提出,来解决 NLP 难题。
这篇论文回顾了与深度学习相关的重要模型与方法,比如卷积神经网络、循环神经网络、递归神经网络。此外,论文中还讨论了记忆增强策略、注意机制以及无监督模型、强化学习模型、深度生成模型在语言相关任务上的应用。
在 2016 年,Goldberg 也以教程方式介绍过 NLP 领域的深度学习,主要对分布式语义(word2vec、CNN)进行了技术概述,但没有讨论深度学习的各种架构。这篇论文能提供更综合的思考。

摘要:深度学习方法利用多个处理层来学习数据的层级表征,在许多领域获得了顶级结果。近期,在自然语言处理领域出现了大量的模型设计和方法。在此论文中,我们回顾了应用于 NLP 任务中,与深度学习相关的重要模型、方法,同时概览了这种进展。我们也总结、对比了各种模型,对 NLP 中深度学习的过去、现在与未来提供了详细理解。

图 2:一个 D 维向量的分布式向量表达,其中 D < V,V 是词汇的大小。

图 3:Bengio 等人 2003 年提出的神经语言模型,C(i) 是第 i 个词嵌入。

图 4:CBOW(continuous bag-of-words)的模型

表 1:框架提供嵌入工具和方法

图 5:Collobert 等人使用的 CNN 框架,来做词级别的类别预测

图 6:在文本上的 CNN 建模 (Zhang and Wallace, 2015)
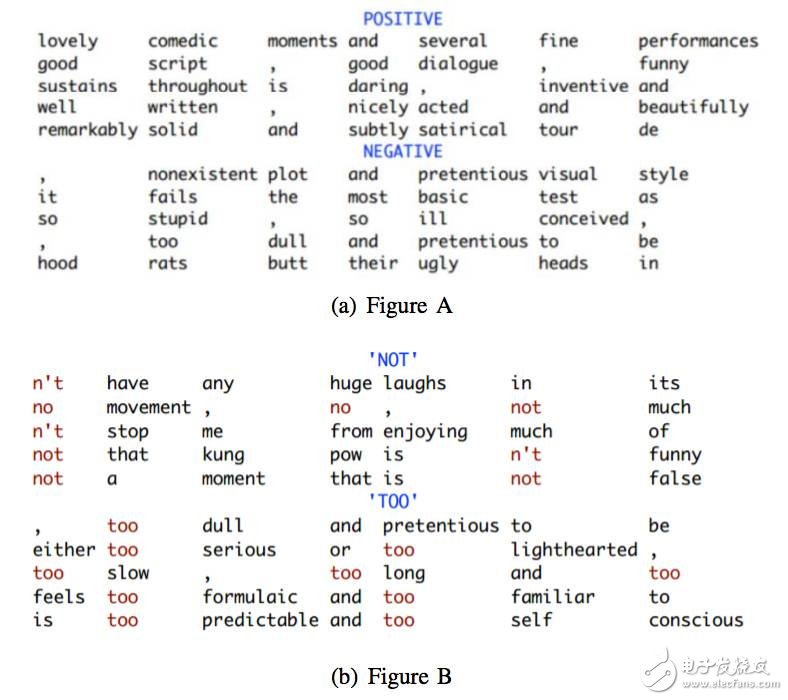
图 7:4 个 7-gram 核的 Top7 -grams,每个核对一种特定类型的 7-gram 敏感 (Kim, 2014)

图 8:DCNN 子图。有了动态池化,一顶层只需要小宽度的过滤层能够关联输入语句中离得很远的短语 (Kalchbrenner et al., 2014)。

图 9:简单的 RNN 网络
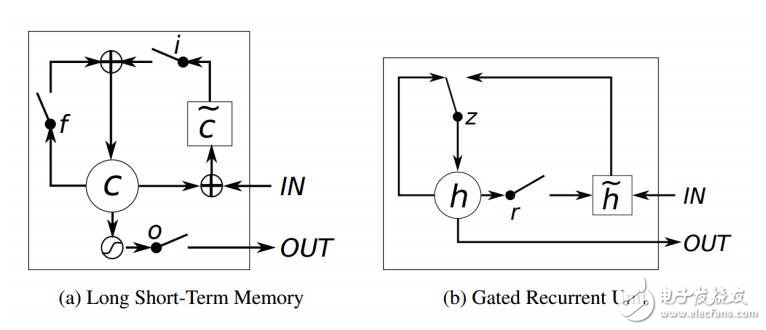
图 10:LSTM 和 GRU 的示图 (Chung et al., 2014)
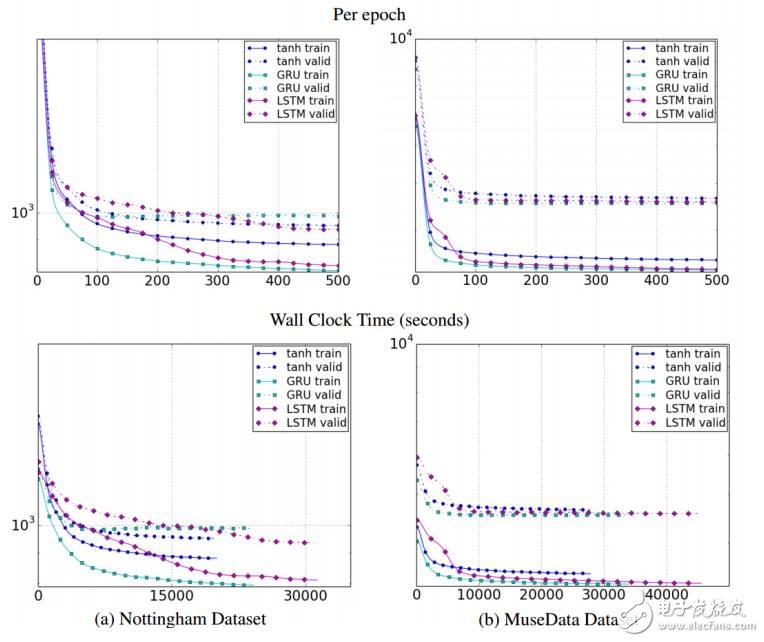
图 11:不同单元类型关于迭代数量(上幅图)和时钟时间(下幅图)的训练、验证集学习曲线。其中 y 轴为对数尺度描述的模型负对数似然度。

图 12:LSTM 解码器结合 CNN 图像嵌入器生成图像描述 (Vinyals et al., 2015a)

图 13:神经图像 QA (Malinowski et al., 2015)

图 14:词校准矩阵 (Bahdanau et al., 2014)
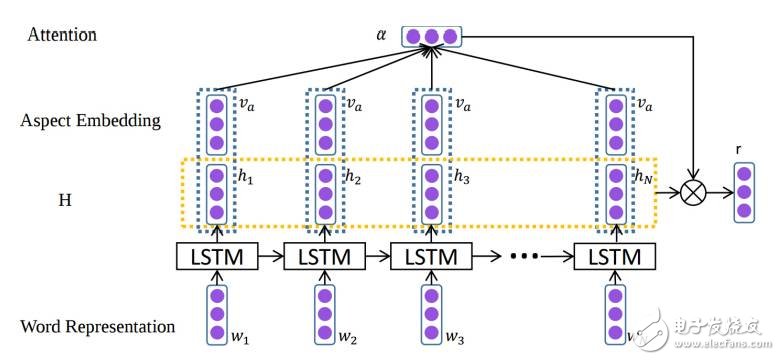
图 15:使用注意力进行区域分级 (Wang et al., 2016)

图 16:特定区域语句上的注意模块专注点 (Wang et al., 2016)

图 17:应用于含有「but」语句的递归神经网络 (Socher et al., 2013)
- 解密英伟达Tesla P100、GP100、DRIVE PX2平台(04-26)
- 人工智能处理器三强Intel/NVIDIA/AMD谁称霸?(07-23)
- 2016年人工智能与深度学习领域的十大收购(07-26)
- 人工智能实现的流派 FPGA vs. ASIC看好谁?(08-27)
- IBM沃森能否在人工智能领域突破重围?(09-19)
- 英特尔与高通将在汽车芯片市场再次对决(上)(10-03)