认识多种处理芯片的特性和实战
式,所以用并行模式实现算法和功能的时候,通常困难比串行模式来得大。除此之外,还有如下特性不同:
FPGA硬件具有资源占用率的概念。FPGA编程最终要用逻辑电路实现,因此复杂的算法需要耗用更多的逻辑电路,如果使用的逻辑电路超过芯片的资源是无法实现的。这个特性和CPU完全不同,CPU的程序存储在外部存储中,执行时从外部存储载入内存执行。内存和外部存储的容量远远超过算法需要的存储量,基本不可能出现资源不够用的情况。
FPGA通常运行的时钟频率远小于CPU的时钟频率。对FPGA编程的过程,实际是将芯片内部逻辑电路连接起来实现算法和功能的过程。从FPGA的结构可以发现,FPGA是固定排列的门电路阵列,逻辑电路固定的排列方式决定了编程过程有大量的冗余电路没有利用,走线也不能够充分的精简。因此当前主流FPGA芯片编程通常运行时钟频率为200Mhz~300Mhz,而CPU的运行频率已超过Ghz的关口,现代主流的X86 CPU的时钟频率甚至超过3Ghz。
1.6 ASIC的架构
ASIC和FPGA类似,都是用门电路资源实现固定的算法,不同之处是FPGA是固定排列的门电路阵列,固定的排列方式决定了编程过程有大量的冗余电路没有充分利用,造成门电路资源的浪费,而ASIC是经过专门优化之后的门电路布局,相比较FPGA精简的多。根据厂商的提供的资料,实现同等功能FPGA所需的门电路数目可能比ASIC高10倍。
从使用方式来比较,FPGA可以重复编程,而ASIC一次编程后无法更改。由于FPGA可重复编程的灵活性,设计ASIC芯片多数时候会先用FPGA实现逻辑功能,然后基于FPGA的结果进行优化和整合,得到最终的ASIC芯片需要的电路设计。
在真正的实践中,并没有进行ASIC的设计和实际的制造,这是因为ASIC的设计和制造非常昂贵,和合作厂商沟通的结果大概需要百万美元的投入。ASIC芯片的昂贵决定了它不可能在小规模应用的场合出现,而必须是大规模(达到百万以上的量级)的应用场景才可以分摊ASIC的昂贵投入取得经济上的合理性。这种特性导致一个有趣的结果,一种计算算法初步启动时常常使用FPGA作为硬件载体,利用FPGA承载算法,随着规模扩张,就有商业性的ASIC芯片出现。一旦规模达到经济上的合理,ASIC芯片的成本就远小于FPGA的成本并取代FPGA的地位。
一个事实就是PCIE SSD的应用。早期的PCIE SSD都是使用FPGA作为内部算法的硬件载体,而2014年以来随着PCIE SSD应用的规模化,已经有ASIC芯片出现并在一些PCIE SSD的产品中应用。后续ASIC芯片很可能替代FPGA在PCIE SSD的应用。
1.7 计算实践和对比
为比较各种芯片的计算性能,以jpeg格式的图片进行解码和重新编码的计算为例子。下图展示了jpeg图像处理的算法过程。

jpeg图像的压缩过程:所有的图像数据首先要进行色彩空间的转换,从RGB色彩空间转换为YUV色彩空间。然后将图像分割为8像素X8像素的图像块,对每个图像块进行离散余弦变换(DCT),然后对变换后的数据量化得到量化值,最后对量化值进行墒编码,得到压缩后的图像数据。
而jpeg图像的解码过程则是编码过程的逆向过程,首先对压缩的图像数据进行墒解码,得到量化之后的数据,然后执行反量化获得量化之前、离散余弦变换之后的数据,最后进行反离散余弦变换,获得原始图像数据。
1.7.1 CPU的实践和性能
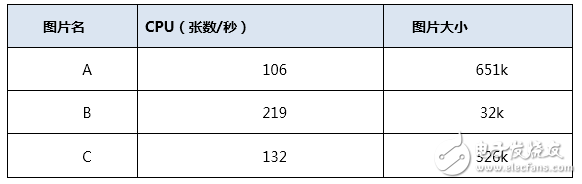
对比测试的项目以每秒钟jpeg图片解码然后重新编码的性能为准,对单张图片循环重复计算,单位为张数。CPU计算平台采用的处理器为至强E3-1270,CPU计算平台使用的转码软件是imagemagic-6.8.6,多进程并发循环执行。下表给出CPU的性能数据。
1.7.2 GPU的实践和性能
利用GPU进行图片解码和再编码时,首先遇到了顺序执行的问题。JPEG解码里面的墒解码器使用的是霍夫曼解码。霍夫曼解码在解码图像数据时候,依次处理一个个图像块,块之间没有分割标志,因此存在数据依赖关系,必须把前面图像块的数据解码完成,才能处理下一个图像块。这种必须顺序执行的计算部分GPU运行效率非常低,如果霍夫曼解码在GPU里面完成,整体效率甚至不如CPU。我们和Nvidia公司的软件团队讨论了这个问题,最后确定的方案是将霍夫曼解码部分由CPU完成。使用GPU的异构编程应当被看做是CPU的计算辅助单元,共同和CPU完成计算任务,由于架构和配套资源的特点,很难把GPU当作完整的解决方案。
第二个重要的问题是内存的分配和管理。以操作系统的角度来看,异构编程其实是对外部设备的编程,软件代码可以分成两部分,一部分在CPU上面执行,另一部分在GPU上执行。GPU的内存分配其实是对设备内存
- GPU性能不够跑VR?这项技术或许能解决难题(03-29)
- VR设计:如何实现GPU和显示器高度集成(05-11)
- 基于CUDA技术的视频显示系统的设计方案(06-08)
- 笔记本电脑中温度传感器的应用(06-14)
- 双GPU设计 打造最简单与最快速的加速方案(05-25)
- Intel第六代处理器 Skylake CPU、GPU、主板完全解析(09-06)