Mali GPU编程特性及二维浮点矩阵运算并行优化详解
nCL C语言编写,Mali GPU会根据内核对象创建主机端请求数量的线程实例,每个线程的运算工作都由图4中一个对应的PE进行处理,线程的工作逻辑决定了线程标识号和数据的关联关系。多个线程被组织为工作组的形式,每一个工作组固定分配到一个CU上进行处理,同一个工作组中的线程会在对应的CU上由Mali GPU的任务管理单元进行快速的切换和调度,保证一个CU上的PE最大限度保持忙碌。
2.2 Mali GPU多核环境下的存储器空间映像方法
如图4所示,Mali GPU和Cortex A15 CPU所共用的RAM在逻辑上被OpenCL框架切割成了四种不同的类型,Mali-T600系列的GPU使用统一存储器模型,四种类型的存储器都映射到片外RAM上,Cortex-A15 CPU和Mali-T604 GPU共享物理RAM,相对桌面GPU平台而言,在Mali平台上将数据从全局存储器拷贝到局部或者私有存储器并不能使访存性能得到提升,但相对地也不用像桌面GPU一样进行从主存到显存的数据拷贝。Mali GPU有三种访问RAM的方式,由传入clCreateBuffer函数中的不同参数决定,其示意图如下:
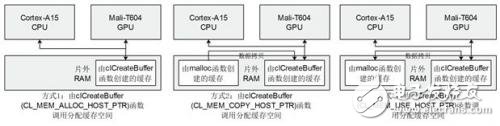
图5 OpenCL框架下Mali GPU对存储器的不同访问方式
Cortex-A15 CPU和Mali-T604 GPU使用不同的虚拟地址空间,在主机端由malloc函数分配的缓存,Mali GPU无法访问。Mali GPU可以访问clCreateBuffer函数分配出的缓存,CPU借助OpenCL中的map映射操作也可实现对这类缓存的读写,图5中的方式2需要主机端的缓存进行数据拷贝来初始化,方式3和方式2类似,但只在OpenCL的内核函数首次使用该缓存时才进行数据拷贝,在CPU端进行map操作时 GPU还会将数据拷贝回主机端的缓存,对于Mali GPU而言,多余的数据拷贝操作会降低访存效率。图5中的方式1是ARM官方建议的访存方式,CPU和GPU共享一块物理缓存,高速实现数据交互。
2.3 Mali GPU的向量处理特性
Mali-T604 GPU内部有128位宽度的向量寄存器,使用OpenCL C中的内建向量类型可以让数据自动以SIMD的形式在Mali GPU的ALU中进行并行计算,Mali GPU中将数据以16个字节对齐可以使得数据的长度和高速缓存适配,加快数据存取速度,Mali-T600系列GPU中加载一个128位的向量和加载一个单字节数据花费的时间是一样的。将数据以128位进行对齐,能够最大限度发挥Mali-T604 GPU的访存和运算效率。
3.基于Mali-T604 GPU的快速浮点矩阵乘法并行化实现
矩阵乘法运算在路径方案求解、线性方程组求解、图像处理等领域一直有着广泛应用,普通的迭代式串行算法的时间复杂度为O(n3),对于大型的矩阵乘法,特别是浮点类型的矩阵乘法,计算量非常惊人,传统的算法基于CPU进行设计,CPU并不能提供大型的并行度和强大的浮点计算能力,对于大型浮点类型矩阵乘法的处理力不从心。
AB两个矩阵的乘法的结果矩阵中的每个数据均依赖于A中的一行和B中的一列的点积结果,每个计算结果没有依赖和相关,显然是高度可数据并行的计算问题,很适合使用GPU做并行处理,使用GPU上的多个线程可以并行进行矩阵A和B中不同行和列的点积。
实际进行实验时,以N*N的两个浮点矩阵A和B进行乘法,得出N*N的浮点结果矩阵matrixResult,利用Mali GPU进行并行化的时候,总共分配N*N个线程,以二维方式进行排布,标识号为(i,j)的线程提取出矩阵matrixA的第i行和矩阵matrixB的第j列,利用OpenCL中长度为128位的float4向量类型快速实现两个一维向量的点积,再将该点积结果存储到matrixResult[i] [j]位置。主机端分配线程的代码段如下:

笔者将clEnqueueNDRangeKernel函数中工作组大小参数设置为NULL,由Mali GPU硬件自动确定最佳的工作组大小。由于内核中每次会连续读取4个浮点数值凑成float4类型的数据,所以对于矩阵的宽度不是4的倍数的情况需要进行特殊处理,可在主机端首先将输入矩阵A修改为N行N/4+4列,将矩阵B修改为N/4+4行N列,多出的矩阵部分均以0补齐,这样既不影响计算结果,也不会影响线程的分配方案,实现并行方案的内核函数如下所示:

本文采用Arndale Board开发板作为测试平台,软件平台采用Linaro机构为Arndale Board定制的基于Ubuntu的嵌入式Linux操作系统,其内核版本为3.10.37,实验时使用arm-linux-gnueabihf工具链对程序进行编译。不同规模的二维浮点矩阵乘法运算在ARM Cortex-A15 CPU上的串行方案和Mali-T604 GPU上的并行方案的测试结果如面的表1所示,为不失一般性,测试时输入矩阵内容为随机值,每种不同矩阵大小的测试项进行10次测试,将测试值的平均值作为测试结果。
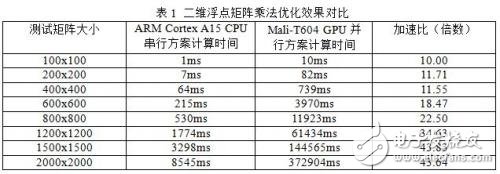
上表仅列出了输入量较大时的测试结果,笔者实际测试
- 高性能汽车和FPGA:共同点比您想象得多(09-09)
- 揭开Altera公司支持OpenCL的设计工具的神秘面纱(11-19)
- 什么是OpenCL?面向FPGA的OpenCL有何优点?(03-12)
- 基于OpenCL标准的FPGA设计(04-26)
- 抢攻数据中心 赛灵思发布OpenCL开发工具(02-10)
- 工控机在IC卡加油工程中的应用(05-13)