兼顾处理器效能与功耗 大小核设计架构突起
,改由另一个处理器执行工作,这个处理器的操作点也会随着负载变化不同而来回变动(图2)。当效能需求不再,可换回之前的处理器(或丛集)。
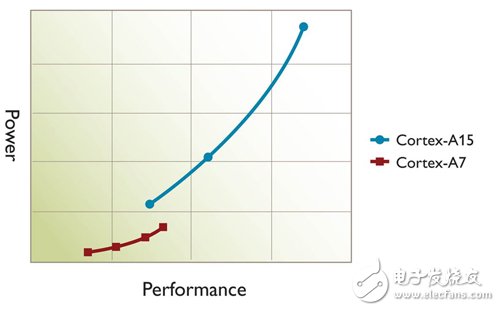
图2 big.LITTLE切换模式DVFS曲线图
显而易见,一致性是达到加速切换所需时间的关键所在,因为它能让已经储存在离埠处理器(Outbound Processor)的状态,在入埠处理器(Inbound Processor)上窥探与回覆,而不必透过主记忆体的存取。
此外,由于离埠处理器的L2有快取一致性的功能,当任务切换时,可以透过窥探资料值的方式,改善入埠处理器的快取暖机时间,此时L2快取记忆体仍然可以维持供电状态;不过,因为离埠处理器的L2快取无法提供新资料的快取配置,最后还是必须清除并关闭电源以节省耗电(图3)。
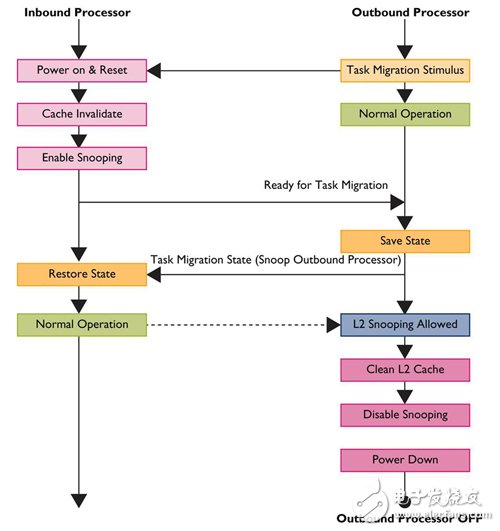
图3 big.LITTLE运算任务切换流程图
由于LITTLE处理器丛集中,每个处理器都将对应一个big丛集的处理器,因此CPU乃成对配置(Cortex-A15及Cortex-A7处理器上都有CPU0, Cortex-A15及Cortex-A7处理器上都有CPU1,以此类推),不论何时每个配对中只有一个处理器可运转;而系统则会主动侦测各处理器负载,在高负载时将内容执行移到大核心(图4)。当负载从离埠核心移到入埠核心,便会关闭其中一个核心,这种模式让big与LITTLE核心组合能随时运转。
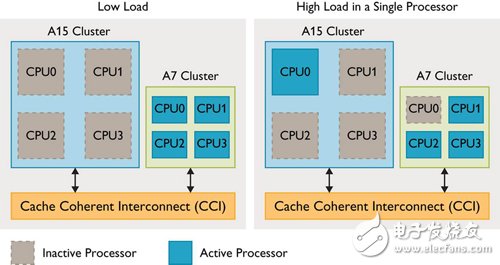
图4 big.LITTLE切换模式DVFS曲线图
big.LITTLE MP支援非对称丛集运作
至于big.LITTLE MP模式则进一步将软体堆叠分配到两个丛集中各个处理器,如此一来,所有CPU皆可同时运作,将系统效能提升到最高点。
由于big.LITTLE系统可经由CCI-400达到快取记忆体的一致性,因此有另一种模式能让Cortex-A15及Cortex-A7处理器同时运作并同步执行程式码,称为big.LITTLE MP,基本上可看作一种异质性多工处理模型。这是big.LITTLE系统最先进且最具弹性的模式,能跨越两个丛集调整单一执行环境。
在这种使用模式下,若执行绪有上述处理效能方面的需求,便可开启Cortex-A15处理器核心并同时透过Cortex-A7处理器核心执行任务。如果没有这方面需求,则只须开启Cortex-A7处理器,在实际应用上,不同丛集的处理器核心不一定一致,而big.LITTLE MP比较容易支援非对称的丛集。
调降低频运算多余功耗 big.LITTLE崭露头角
big.LITTLE技术之所以受到IC设计业者瞩目,原因就是一般行动工作量对效能的需求各有不同,必须找到最合适的核心处理。图5显示的是目前搭载Cortex-A9的行动装置中,两个核心在DVFS、闲置与完全关机状态下所花费时间的百分比,(a)处代表最高频率操作点;(b)处则代表最低频率操作点,介于两者之间则属中级频率。
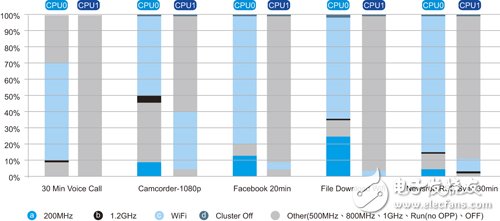
图5 big.LITTLE切换模式DVFS曲线图
除DVFS状态,作业系统电源管理也会使中央处理器闲置,图中(c)处代表闲置时间,当CPU闲置的时间够长,系统电源控制软体将完全关闭其中一个核心以节省耗电,图中(d)处便代表这部分。
从图5可清楚看出应用程式处理器在好几种普通工作量下,都有相当多时间处于低频率状态,在big.LITTLE系统里,系统单晶片(SoC)可利用耗能较低的Cortex-A7核心,执行最高操作频率以外的所有工作。以相同方式分析更为密集的工作量,Cortex-A7处理器对应出低于1GHz频率的机会仍然很大。
事实上,自2011年起,使用者层级软体已能在big.LITTLE排程上运转,不过,那只是在处理器核心与互联的软体模型环境上发展。为完整评估big.LITTLE系统效能、功耗及调校是否合宜,还须打造一个能让使用者软体全速运转的测试晶片。
ARM测试晶片早在2012年初夏即由晶圆代工厂完成,并在短短几周内开始搭配参考设计板运转,支援完整版的Linux系统及Android 4.0作业系统。这个测试晶片包含一个双核心Cortex-A15丛集、一个三核心Cortex-A7丛集,以及CCI-400快取一致汇流排架构。会影响部分使用者评效基准的绘图处理器并不包括在内,但平台仍可支援Linux、Android作业系统与效能测试软体。
测试晶片的Cortex-A15最高频率达1.2GHz,Cortex-A7则为1GHz。效能评析结果显示,虽然测试晶片上的记忆体系统效能不如big.LITTLE SoC量产后的预测水准,但Cortex-A15与Cortex-A7中央处理器的效能仍落在预期范围内。
用来测试big.LITTLE效能的任务量,主要基于Android 4.0系统,透过网页进行网路浏览器效能循环,背景则有音效播放。在此实例中均以相当密集的工作量搭配对性能需求不高的背景活动,网路浏览器每2秒便进行网页循环,每页卷动达500画素,因此对系统效能需求相对较高。
这组结论属于较早期的测试结果,用来测试初版big.
- 瞄准Big Data异质网路商机 晶片厂猛攻OTN乙太网方案(11-03)
- 基于ARM+FPGA的大屏幕显示器控制系统设计(06-30)
- 基于ARM和μC/OS-II的车载定位终端的设计(06-24)
- 解读物联网时代下的ARM mbed 操作系统(05-03)
- 用ARM和FPGA搭建神经网络处理器通信方案(07-19)
- ARM新一代Cortex-A73架构解析 千元机也能有高端SoC(05-06)