从Multicore到Many-Core:体系结构和经验
您可能已经习惯了芯片系统(SoC)的multicore处理器这一概念,而现实却总是在不断变化。8月份举行的Hot Chips大会研讨中,已经清楚的表明multicore正在向many-core发展:在SoC核心位置,密切相关的处理器内核的数量在不断增长,从2个或者4个增加到8个、16个,甚至是很多,很多。
这种增长仅是摩尔定律发展的另一阶段,系统开发人员还是能清楚的了解这一切吗?从multicore发展到many-core是类型的变化,还是仅仅是规模的变化?这种转变能解决系统开发人员面临的问题吗?
为找到这些问题的答案,我们与一些团队进行了交流,他们已经在many-coreSoC开发上积累了一些设计经验。我们向他们提出了一个简单的问题:您的体验与使用multicore有什么不同吗?对于这一简单的问题,我们得到了各种各样的回答。
Many-core的发展
Hot Chips的论文列出了SoC体系结构向many-core领域发展的三条主要路线。我们从Cavium的Kin-Yip Liu在小规模无线基站SoC设计论文中阐述的路线开始,这些设计包括微基站、微微基站和毫微微基站。
名为Octeon Fusion CNF71xx的设计如 图1 所示,包括两个处理簇,含有四个一组的增强MIPS64内核,以及围绕一个共享L2高速缓存的各种硬件加速器,还有6个为一组的数字信号处理(DSP)内核,每个内核都有很多硬件加速器,这些内核分布在共享存储器交换架构周围。

图1.Cavium的Octeon Fusion体系结构结合了CPU簇以及相连接的硬件加速器和分立的DSP内核簇。
四个CPU还很难说明是many-core设计。但是有两个很好的理由让我们的讨论从这一芯片开始。首先,增加6个DSP内核使得芯片成为10核异构体系结构,表面上看已经进入many-core领域。其次,更多的是在理论上,Cavium使用内核的方式与传统的multicore并不相同。
Multicore SoC将线程映射至内核的方式一般是静态的。而随着内核数量的增加,这种映射更具流动性。CPU和DSP可以按数据流来划分,也可以构成虚拟流水线,每一个完成复杂任务的几级任务。或者,处理器可以观察任务序列,一旦空闲,就可以执行新任务。不断增强一个处理器的能力来完成所有数据的处理,而这一概念正在转向由很多处理器共同完成一项工作——从固定硬件到软件与加速器的组合。这种概念上的变化确定了multicore与many-core计算之间的边界。我们看到这种变化是从本地对称的Octeon Fusion体系结构开始的。Cavium很显然同意这一观点。他们在Hot Chips上的研讨表明,目前的芯片只是软件兼容系列的开始,这些系列能够从单核发展到48核。
作为对比,Fujitsu的Takumi Maruyama发表的论文介绍了公司的16核芯片SPARC64 X将成为服务器中心处理器。SPARC64 X与Octeon共享了一个重要的体系结构概念:16个SPARC内核簇围绕一个大规模内核——24 Mbyte,共享L2高速缓存。但这也有很大的不同。这就是专用硬件加速器。Fujitsu将其称之为"芯片软件"。Fujitsu没有在CPU之外开发松耦合加速器,来处理棘手的运算问题(在这个例子中,十进制数学运算、加密和数据库函数等),而是开发了新的RISC类型指令来加速这些运算,在每一CPU的浮点单元流水线中增加了必要的执行硬件。因此,硬件加速并不能灵活的共享L2高速缓存,或者链接系统总线,而是成为CPU不可缺少的组成部分。实际上,这些加速器增加了指令,编译器可以将其优化到CPU指令流中。
Intel和many-core
最后,考虑Intel的Xeon Phi,或者还可以考虑Intel资深首席工程师George Chrysos所介绍的Knights Corner,如 图2 所示。在Chrysos有些含糊的描述中,该器件是采用了"50多个"x86处理器内核的协处理器,还含有四个GDDR存储器控制器,以及与主处理器Xeon CPU连接的PCI Express® (PCIe®)接口。每一个处理器都有自己的专用矢量处理单元,以及自己的512 Kbyte L2高速缓存。L2高速缓存、GDDR控制器以及PCIe控制器不是由传统的交换矩阵连接的,这样会导致规模非常大而在物理上无法实现,而是由双向环形总线连接。这一总线在每一方向上都有64字节数据通路,通过分布式标签方案来实现所有L2之间的一致性。遵从体系结构的发展规律,Xeon Phi在内部与早期的multicore设计非常相似,即,在PlayStation 3中首次使用的IBM Cell协处理器。
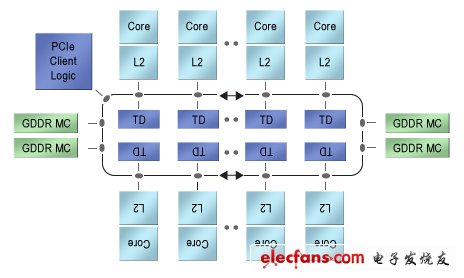
图2.Intel的Xeon Phi是50多个x86内核构成的异构阵列,这些内核通过两路跑道型互联结构连接起来。
Xeon Phi代表了从multicore向many-core的深入发展。这里,与Cell不同,没有专门的加速器或者专用存储器结构,只有
- 一种消防应急灯具专用控制芯片的设计(11-02)
- 基于FPGA的8段数码管动态显示IP核设计(02-03)
- 基于FPGA和IP Core的定制缓冲管理的实现(08-14)
- 基于Altera ASI IP核的ASI发送卡实现(02-25)
- FPGA的高速多通道数据采集控制器IP核设计(04-22)
- 基于EDA或FPGA的IP保护的实现(09-16)