基于TMS320VC5507的语音识别系统实现
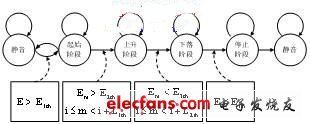
技术的四阶段语音实时检测方法,将每帧语音能量与阈值相比较,同时依次存入长度为 的循环缓冲区并记录当前位置。算法流程如图3所示,其中 、 、 、 、 为事先设定的阈值,它们是通过大量测试得到的。当检测到连续 帧语音能量高于阈值时,将循环缓冲区从当前位置断开,倒退 帧作为语音起始点。
(a) 端点检测基本流程
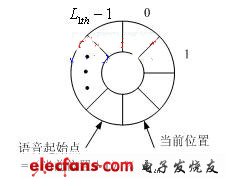
(b) 循环缓冲区设计
图3 基于循环缓冲区的端点检测流程
3.4 特定人识别系统的特征提取与DTW模板匹配
实验表明,采用12维MFCC系数作为特征参数,既可以节省内存空间,又不会对识别率造成很大影响。每帧语音特征参数在内存数据空间中连续存放。采取动态时间规整(DTW)算法,其本质是一种宽度优先的模板匹配过程,即将待识别词条的特征矢量序列与每个模板进行比较,找到一条总失真度最小的路径作为识别结果[6]。DTW算法简单,计算量小,占用内存小,可以解决语速不均匀的问题,适用于特定人小词汇量的孤立词识别系统。
3.5 非特定人识别系统的多级Viterbi搜索与硬件资源消耗分析
非特定人识别基线系统难于在片上实现的瓶颈在于识别时间过长。事实上,如果声学模型构造合理,绝大多数错误结果的似然度往往与正确结果相差较远。因此,本系统采用的基于Viterbi解码的两阶段搜索策略,可以很大程度上缓解识别时间过长的问题。
第一阶段为快速匹配阶段。利用较为简单的208个状态的单音子声学模型,给出匹配程度最高的前Nbest个候选词条,送入第二阶段。第一阶段所占用的主要内存空间有:词条的所有特征,在使用27维特征,最大有效语音长度为128帧情况下,需要6.8 KB;输出分数矩阵,其大小由最大有效语音长度和模型数量决定,是内存开销最主要的部分,在这里需要占用约62 KB的内存;所有词条的对数似然度,200词的情况下为0.8 KB。
第二阶段为精确匹配阶段,采用较复杂的358状态双音子模型,根据第一阶段候选词条构建新的识别网络,进行搜索识别。为了节约内存占用量,设定第一阶段候选词条数量的上限为8,这样,第二阶段可能出现的有效状态数量不会超过208个,从而可以使占用内存最大的输出概率矩阵复用第一阶段输出概率矩阵所占用的那段内存,提高内存使用效率[7]。
4 实验结果
录音环境为办公环境,8 kHz采样,16 bit量化,每个词条最大持续时间为2 s,端点检测的循环缓冲区长度 =7 W。特定人识别系统的测试语音为本实验室自录的100个孤立词人名词表,识别结果如表1所示。非特定人识别系统的训练集为863男生连续语音数据,测试语音为200词的人名词表。第一阶段多候选识别结果如图4所示。可见,虽然一候选的识别率不足94%,但随着候选词条数的增加,正确识别结果几乎都包含在第一阶段前几选的识别结果中。本文选用的八候选策略的识别率可以达到99.5%。系统最终识别结果如表2所示,识别率仅从基线系统的98.5%下降到97.5%,而识别时间仅为基线系统的30%。

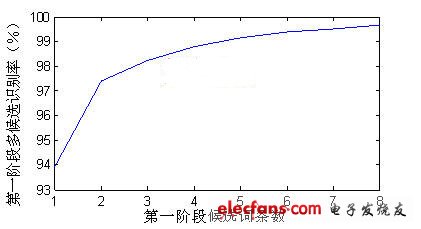
图4 非特定人系统第一阶段多候选识别率
5 结论
本文提出了一种基于定点DSP的特定人与非特定人语音识别片上系统的实现方法。通过降低特征维数,改进语音预处理与识别算法等手段,在保证识别性能的前提下,实现了硬件资源的高效率利用。在运算速度为288 MIPS,工作时钟为144 MHz的条件下,特定人与非特定人识别系统识别率分别为98%与97.5%,识别时间分别为0.13倍实时和0.34倍实时。
本文的创新点在于:采用基于循环缓冲技术的四阶段实时端点检测算法,以及基于双缓冲区的语音传输方式,在核心识别算法的处理中,选择合适的特征维数,合理优化识别算法流程,在保证识别性能不受影响的前提下,有效改善了硬件资源占用率与系统实时性能。
语音识别 TMS320VC5507 相关文章:
- 基于DSP和机器人的声控系统设计与实现(02-21)
- CEVA携Sensory力推先进的语音识别解决方案(02-12)
- NEC开发出在噪声环境下进行语音操作智能机的技术(04-10)
- 基于语音的终端映射技术如何实现智能交互?(04-30)
- 解析语音识别技术在手机中的应用(06-16)
- Nuance语音识别技术及解决方案(11-16)