浅谈如何通过整合电源管理提升电信业务处理性能
nux应用环境下的EAL和GLIBC
测试拓扑结构
为了测量ATCA处理器刀片在第三层处理和转发IP包的速度,我们使用图8中所示的环境进行测试。
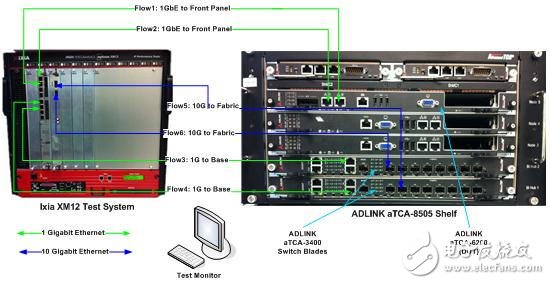
图8:IP转发测试环境
我们的测试使用了ATCA处理器刀片的2个10GbE外部接口和两个10GbE Fabric接口(总计40G),通过比较使用和未使用DPDK的结果,我们可以得出结论:在相同的硬件平台下,使用DPDK后的Linux仅用两个 CPU线程进行IP转发的性能,与原生 Linux(Native Linux)使用全部的CPU线程进行IP转发的性能相比,前者是后者的10倍。使用DPDK的平台,3层小数据包的转发线速可以达到》70%。 DPDK中优化过的软件堆栈可以实现10倍性能的提升。如果在一个基于IA架构的刀片的控制层和数据层配备DPDK,就可以减少一个40G的NPU刀片。通常一个40G的GPU刀片的功耗为180W,因此通过工作负载整合可以节省56%的能耗。
从图9可以看出,搭配DPDK后的处理器刀片的IPv4转发性能,可以让客户以更好的性价比成本,将包处理应用从基于硬件的网络处理器移植到基于x86的计算平台,同时使用同一个平台来部署不同的服务,如程序处理、控制处理和包处理服务。更多关于我们的测试过程和结果,请登录凌华科技网站www.adlinktech.com查询凌华科技的技术白皮书:采用Intel? DPDK技术的凌华科技aTCA-6200刀片式服务器完美实现包转发服务性能的提升。
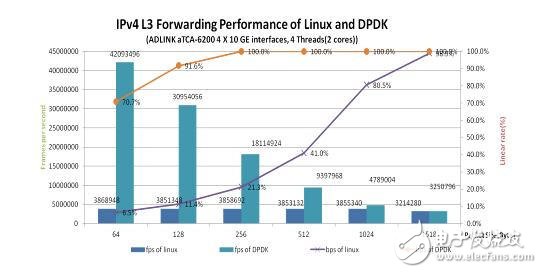
图9:采用4个10GbE的IP转发性能比较
结论
目前有很多途径可以优化多板卡/多处理器系统的电源使用及效率。我们已经看到了使用嵌入式电源管理、整合嵌入式电源管理的动态迁移以及优化吞吐量的工作负载整合等方法的可能性。由于每个系统的配置和对工作负载的需求都不尽相同,因此没有一个绝对的解决办法。对于每一个方案,都需要仔细选择适合的技术和策略,以满足预期的吞吐量和功耗。
在未来,随着每个系统的功耗密度(瓦/立方英寸)的持续增加,必然对散热和运营的花费造成一定的影响,因此电源管理对于电信运营商而言将仍旧是一个需要重视的问题。
- 基于自适应技术的CPU供电电路系统(10-27)
- 嵌入式CPU卡在医用便携式监护仪中的应用及设计(09-23)
- 四核Vs八核移动处理器 性能差异并不大(03-10)
- 可编程逻辑控制器(PLC)基本操作及功能简介(03-07)
- 评测:采用AMD APU平台的联想启天M5800——均衡+全能(02-17)
- 智能手机省电秘诀:看如何从设计源头来降低功耗(02-14)