基于Xilinx Spartan-6 FPGA加速纹理映射的实现
高速缓存的时候,读取被禁用,而且可将两个端口(每个原始双端MSRAM各一个)用于将数据送给存储器。
图6是纹理元素高速缓存的简化方框图。在每个时钟周期中,纹理元素高速缓存均以流水线的方式处理来自每个通道的存储器地址。如果这些存储器地址命中高速缓存,并且"命中"信号始终保持高电平,那么流水线就会一直运行。
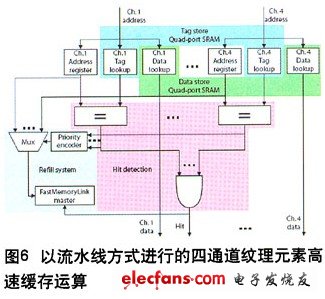
如果发生失的,"命中"信号会转为低电平(流水线停顿),随即由优先级编码器和多路复用器(mux)选择失的的地址之一(可以是1个,也可以是多个)。存储器总线主系统发出一个存储器交易事务以从系统存储器中检索数据,然后替换高速缓存线路的内容,并对标签进行重写。该地址现在变成命中高速缓存状态。如果没有其他地址未命中高速缓存,纹理元素高速缓存就已经成功地处理该4通道交易事务,而且"命中"信号会再次转为高电平,以进行到下一个周期的处理。否则,该流程将重复进行,直到所有的地址都命中高速缓存为止。
可以看到,在现代FPGA中,只要将用于存储的Block RAM的数量翻倍,同时辅以合理数量的控制逻辑,就能够实现理想的4端口高速缓存系统。
紧随纹理元素高速缓存之后,双线性滤波器将4个获取到的纹理元素的结果混合在一起。在此,我们的设计再次充分发挥了Spartan 6中DSP48A1Slice的性能,能够迅速计算出加权和。最后,可使用写入缓冲器将结果存储到基于SDRAM的系统存储器中。
一旦与我们的软核片上系统相集成后,我们的纹理映射单元就会仅使用低成本Spartan 6 FPGA的一小部分资源,却能提供每秒7000万像素的峰值填充速率以及每秒3700万像素的平均填充速率。与纯软件相比,即便是与使用运行在高性能(及高能耗)ASIC CPU的软件相比,性能也是一大飞跃,能够充分满足我们应用的要求。
高度灵活的单芯片
采用高性能可重配置 FPGA,可在高度灵活的单芯片中将过去只有ASIC才能处理的繁重图形处理功能与非常特定的I/O接口结合在一起。
Milkymist系统能够充分利用Spartan 6 FPGA的众多特性:I/O延迟组、DDR寄存器、大型真双端口Block RAM、DSP Slice、灵活的DCM CLKGEN组件,能够从NOR闪存进行配置以及多重引导功能。我们的完整设计仅使用了FPGA资源的大约一半,为将来的改良和特性预留了充裕的空间。这对成本像XC6SLX45这样低的芯片来说是非常了不起的。
对于未来的功能改进而言,整个FPGA设计是属于开源的,而且其许可和开发模式与Linux内核一样。设计人员能够使用免费的ISE WebPACK设计软件(同时提供Linux版和Windows版)重新构建完整的比特流。
最后需要指出的是,该器件的总功耗不足5W,从而不仅充分凸现了以单芯片FPGA为核心的解决方案的又一优势所在,同时还进一步推翻了所有FPGA系统都是高功耗系统的错误认识。
Spartan-6 Xilinx ASIC FPGA 相关文章:
- 骨灰级音响发烧友如何打造随身DAC兼耳扩?(02-09)
- 6 FPGA LX9 MicroBoard成为学习FPGA的另一低成本方法(02-10)
- Xilinx Kintex UltraScale 一半尺寸的 PCI Express 平台 (HTG-K816)(06-15)
- Xilinx全新参考设计提供业界首个单芯片400G解决方案(02-12)
- Xilinx用于工业自动化的机器视觉解决方案(11-30)
- Xilinx多协议机器视觉摄像机参考设计(12-01)