深度学习开源框架,AI从业者的选择之路
,必须采用符号求导的方法才能解决目标函数过于复杂的问题。另外一些非深度学习问题,例如:二次型优化等问题,也都可以用这些深度学习工具来求解了。
更为优秀的是,Theano 符号求导结果可以直接通过 C程序编译,成为底层语言,高效运行。
这里我们给一个 Theano 的例子:
》》》 import numpy
》》》 import theano
》》》 import theano.tensor as T
》》》 from theano import pp
》》》 x = T.dscalar(‘x’)
》》》 y = x ** 2
》》》 gy = T.grad(y, x)
》》》 f = theano.function([x], gy)
》》》 f(4)
8
上面我们通过符号求导的方法,很容易的求出 y 关于 x 的导数在 4 这个点的数值。
标准 4:对数据量、硬件的要求和支持
对于多 GPU 支持和多服务器支持,我们上面提到的所有平台都声称自己能够完成任务。同时也有大量文献说某个平台的效果更为优秀。我们这里把具体平台的选择留给在座各位,提供下面这些信息:
首先想想你想要干什么。现在深度学习应用中,需要运用到多服务器训练模型的场景往往只有图像处理一个,如果是自然语言处理,其工作往往可以在一台配置优秀的服务器上面完成。如果数据量大,往往可以通过 hadoop 等工具进行数据预处理,将其缩小到单机可以处理的范围内。
本人是比较传统的人,从小就开始自己折腾各种科学计算软件的编译。现在主流的文献看到的结果是,单机使用 GPU 能比 CPU 效率提高数十倍左右。
但是其实有些问题,在 Linux 环境下,编译 Numpy 的时候将线性函数包换为 Intel MLK 往往也可以得到类似的提高。
当然现在很多评测,往往在不同硬件环境、网络配置情况下,都会得到不一样的结果。
就算在亚马逊云平台上面进行测试,也可能因为网络环境、配置等原因,造成完全不同的结果。所以对于各种测评,基于我的经验,给的建议是:take it with a grain of salt,自己要留个心眼。前面我们提到的主要工具平台,现在都对多 GPU、多节点模型训练有不同程度的支持,而且现在也都在快速的发展中,我们建议听众自己按照需求进行鉴别。
标准 5:深度学习平台的成熟程度
对于成熟程度的评判往往会比较主观,结论大多具有争议。我在这里也只列出数据,具体如何选择,大家自己判断。
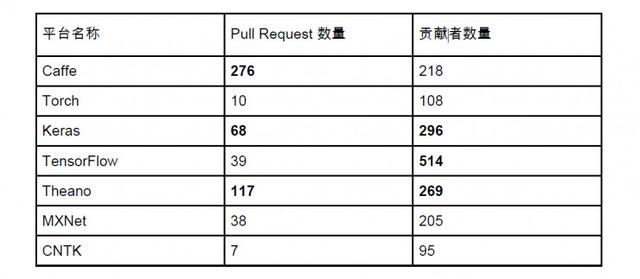
这里我们通过 Github 上面几个比较受欢迎的数量来判断平台的活跃程度。这些数据获取于今天下午(2016-11-25)。我们用黑体标出了每个因子排名前三的平台:
第一个因子是贡献者数量,贡献者这里定义非常宽泛,在 Github issues 里面提过问题的都被算作是 Contributor,但是还是能作为一个平台受欢迎程度的度量。我们可以看到 Keras, Theano, TensorFlow 三个以 Python 为原生平台的深度学习平台是贡献者最多的平台。
第二个因子是 Pull Request 的数量,Pull Request 衡量的是一个平台的开发活跃程度。我们可以看到 Caffe 的 Pull Request 最高,这可能得益于它在图像领域得天独厚的优势,另外 Keras 和 Theano 也再次登榜。
另外,这些平台在应用场景上有侧重:
自然语言处理,当然要首推 CNTK,微软MSR(A) 多年对自然语言处理的贡献非常巨大,CNTK 的不少开发者也是分布式计算牛人,其中所运用的方法非常独到。
当然,对于非常广义的应用、学习,Keras/TensorFlow/Theano 生态可能是您最好的选择。
对于计算机图像处理,Caffe 可能是你的不二选择。
关于深度学习平台的未来:
微软在对 CNTK 很有决心,Python API 加的好,大家可以多多关注。
有观点认为深度学习模型是战略资产,应该用国产软件,防止垄断。我认为这样的问题不用担心,首先 TensorFlow 等软件是开源的,可以通过代码审查的方法进行质量把关。另外训练的模型可以保存成为 HDF5 格式,跨平台分享,所以成为谷歌垄断的概率非常小。
很有可能在未来的某一天,大家训练出来一些非常厉害的卷积层(convolution layer),基本上能非常优秀地解决所有计算机图像相关问题,这个时候我们只需要调用这些卷积层即可,不需要大规模卷积层训练。另外这些卷积层可能会硬件化,成为我们手机芯片的一个小模块,这样我们的照片拍好的时候,就已经完成了卷积操作。
- 大联大友尚集团推出基于Fairchild器件的LED照明电源解决方案(11-19)
- AI/机器学习/深度学习三者的区别是什么?(09-10)
- 阿里AI LABS与庆科信息联合推出儿童语音智能解决方案(04-05)
- 盘点人工智能技术的应用领域(05-01)
- foxmail如何设置有自定义背景的邮件模版(04-11)
- 电脑组建RAID 0的要诀(03-01)