语音识别技术分析:语音变成文字其实没有那么神秘
时间:07-08
来源:极客公园
点击:
单词级网络展开成音素网络,再展开成状态网络。语音识别过程其实就是在状态网络中搜索一条最佳路径,语音对应这条路径的概率最大,这称之为「解码」。路径搜索的算法是一种动态规划剪枝的算法,称之为 Viterbi 算法,用于寻找全局最优路径。
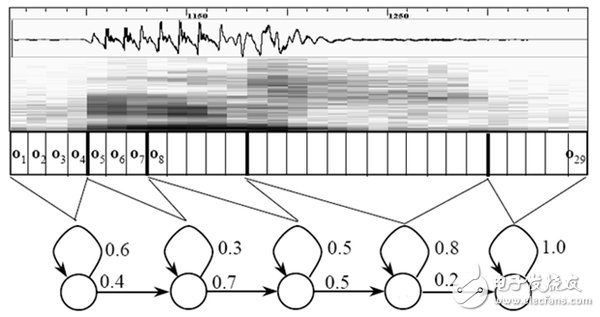
这里所说的累积概率,由三部分构成,分别是:
观察概率:每帧和每个状态对应的概率
转移概率:每个状态转移到自身或转移到下个状态的概率
语言概率:根据语言统计规律得到的概率
其中,前两种概率从声学模型中获取,最后一种概率从语言模型中获取。语言模型是使用大量的文本训练出来的,可以利用某门语言本身的统计规律来帮助提升识别正确率。语言模型很重要,如果不使用语言模型,当状态网络较大时,识别出的结果基本是一团乱麻。
这样基本上语音识别过程就完成了。
以上介绍的是传统的基于 HMM 的语音识别。事实上,HMM 的内涵绝不是上面所说的「无非是个状态网络」那么简单。以上的文字只是想让大家容易理解,并不追求严谨。
语音识别 相关文章:
- 基于DSP和机器人的声控系统设计与实现(02-21)
- CEVA携Sensory力推先进的语音识别解决方案(02-12)
- NEC开发出在噪声环境下进行语音操作智能机的技术(04-10)
- 基于语音的终端映射技术如何实现智能交互?(04-30)
- 解析语音识别技术在手机中的应用(06-16)
- Nuance语音识别技术及解决方案(11-16)