苹果终于把Siri开放给开发者 这是所有细节
果不其然,苹果在昨晚WWDC 2016上发布了新的SiriKit,即把Siri开放给开发者。作为自2012年就发布的Siri,除了偶尔说几个段子、打个电话或者发个短信,似乎也没啥太多常用的功能。iOS平台的一个显著优势其拥有丰富的第三方应用生态和众多优质开发者,将Siri开放给iOS生态希望能够让Siri支持更丰富的功能。
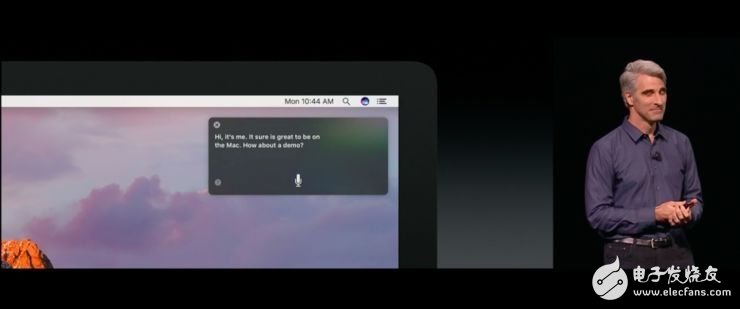
| Siri 变身 SiriKit 之后,带来什么?
面向开发者的Siri的API都集成在今天早上刚刚发布的SiriKit中。(有趣的是,现任泰国王后也叫Sirikit,就是中国人民的老朋友诗琳通公主的母上)。
SiriKit采用了跟Google和出门问问类似的策略,即用户通过正常的流程唤醒Siri,Siri做完语音识别和语义分析之后,将结构化语音分析结果打包成一个某个领域(Domain)的意图(Intent),然后交给支持这个意图(Intent)的第三方应用(比如微信),第三方应用被启动,从传入的Intent中获取相应的信息,完成操作。
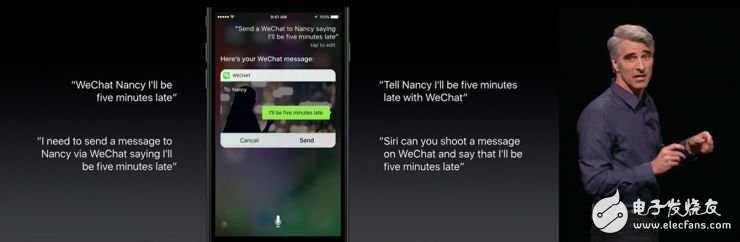
例如,上图演示中提到了的例句 "I need to send a message to Nancy via WeChat saying I‘ll be five minutes late",当用户唤醒Siri说出这句话的时候,Siri会把上面这句话转换成结构化语义意图:
领域 (Domain):Messaging
意图 (Intent):Send a message (INSendMessageIntent)
意图参数 (Intent Parameter)
收件人(recipients):Nancy
消息内容(content):I’ll be five minutes late
然后这个意图会被转交给微信,微信会从该意图中抽取出收件人和消息内容,匹配用户联系人并发送消息。
按照苹果官方的iOS文档,现在SiriKit共支持7个领域的共计22种意图:
语音通话 VoIP Calling:打电话、发起视频电话、查通话记录
信息 Messaging:发信息、搜索信息
照片搜索 Photo Search:搜索照片、播放照片幻灯片
个人之间的付款 Payments:向某人付款、向某人收款
健身 Workouts:开始健身、暂停健身、恢复健身、结束健身、取消健身
打车 Ride Booking:查看附近可用的车辆、订车、查看订单
车载 CarPlay:切换音频输入源、空调、除霜、座椅加热、FM调台
对于以上的22种意图,苹果都会帮开发者处理好所有的语音识别和语义理解,开发者只需要申明支持某些意图,然后坐等用户唤醒就好了。
比如说,"Hey Siri, 用支付宝付20元给小张作为午饭钱",支付宝就会自动被唤醒,找到用户"小张"并转账20元。
"Hey Siri,用滴滴给我叫一辆车去中关村",则启动滴滴打车,并自动设定目的地为中关村。
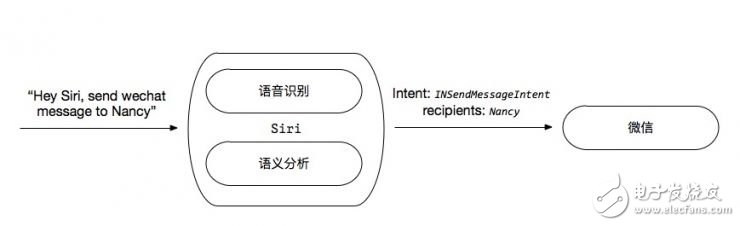
(图为作者自制)
作为开发者而言,如果你的App功能正好跟以上7大领域22意图重合,那么是一个很好的机会去声明支持其中某一些意图,这样就可以让用户用语音的方式来启动你的应用,大大增加使用的便利性和用户粘性。
| 苹果为什么现在才开放Siri的语音搜索API?
1、开放给开发者需谨慎
SiriKit开放了Siri的语音搜索API,机制跟Google Android Voice 类似,后者都已经上线两年并早已支持十几种领域,远超SiriKit现在发布的7个领域。而国内的出门问问,因有Ticwear智能手表操作系统作为入口,早在去年年初就开发了类似的语义API,滴滴、支付宝、阿里小智智能家居等第三方厂商早已通过这种形式落地其手表操作系统。
在语音搜索API上,一般公司的做法都是极其谨慎的。不同于以科大讯飞为代表的"应用内"语音、语义API,苹果、Google、出门问问这些API属于"入口级"语音搜索API,即语音搜索是系统发起的而非在应用内发起,系统识别语音意图并分发给第三方应用。
一般这类"入口级"语音搜索API,会非常谨慎地先做好领域分类(Domain Classification),然后根据分出来的领域导流给不同的应用。所以,领域和领域内意图,一般要由系统事先定义好、并且优化好语音、语义识别模型之后,才开放给第三方开发者使用。
2、现有语音识别API存在哪些技术瓶颈?
由于众所周知的技术难度,现有的语音识别API还存在以下技术瓶颈:
首先,语音识别方面,训练一个可靠的语音识别需要领域内的大量语言模型。
例如如果不将北京地名词典这样的领域知识输入进语音识别引擎,语音识别根本无法正确输出类似于"簋(gui)街"这样的不常见词语。
其次,由于是"入口级"语音搜索,还要处理好不同领域之间的歧义。
例如"发微信给小苹果让她帮我打电话订一辆出租车",这句话对人类来说是再简单不过了,但是对于现有的语义识别系统来说都是极具挑战性的:这到底是要发短信呢?还是打电话?还是叫车?怎
- 解密英伟达Tesla P100、GP100、DRIVE PX2平台(04-26)
- 人工智能处理器三强Intel/NVIDIA/AMD谁称霸?(07-23)
- 2016年人工智能与深度学习领域的十大收购(07-26)
- 人工智能实现的流派 FPGA vs. ASIC看好谁?(08-27)
- IBM沃森能否在人工智能领域突破重围?(09-19)
- 英特尔与高通将在汽车芯片市场再次对决(上)(10-03)