一种基于DSP的汉字语音识别系统设计
统结构也比较灵活、一致。
根据描述的语音单位的大小,HMM可分为:基于整词模型的HMM(Word based HMM)。其优点为可以很好地描述词内音素协同发音的特点,建模过程也较为简单。因此很多小词汇量语音识别系统均采用整词模型HMM.但在大词汇量语音识别中由于所需建立的模型太多而无法使用。
基于子词模型的HMM(Sub Word based HMM)。该类HMM描述的语音单位比词小,如英语语音识别中的基本音素,汉语语音识别中的半音节等。其优点为模型总数少,所以在大词汇量语音识别中得到了广泛的应用。其缺点在于其描述词内协同发音的能力劣于整词模型,但由于子词模型已经得到了非常充分的研究,所以近年来在很多小词表应用识别系统中也用了子词模型。本技术方案采用基于半音节(即声、韵母)的语音建模方法,其识别模型拓扑结构如图3 所示,其中静音HMM采用1个状态,每一声母模型采用2个状态,每一韵母模型采用4个状态。
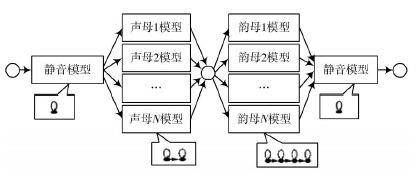
图3 识别模型拓扑结构
根据输出概率分布的不同,HMM(隐含马尔科夫模型)可分为:
离散HMM(Discrete HMM,DHMM)。其输出概率是基于一套码本的离散概率分布,其优点在于由于实现了存储量和计算量都较小,所需的训练语音也较少,但其矢量量化的过程会造成性能的损失。
连续HMM(Continuous Density HMM,CDHMM)。其输出概率是连续概率密度函数(一般是高斯混合密度函数)。其所需的训练语音较多,模型参数存储量和计算量都较大,在训练语音足够时,其性能优于DHMM.
半连续HMM(Semi Continuous HMM,SCHMM)。SCHMM是DHMM和CDHMM的折衷,与DHMM相似,其输出为一套码本,但每个码字均为一个连续概率密度分布函数,这一点与CDHMM相近。其性能和所需的训练语音等均介于DHMM和CDHMM之间。
考虑到汉语数码语音所需的模型较少,很容易获得足够多的训练语音,因此本技术方案采用了CDHMM为语音模型。
状态输出概率分布为混合高斯密度函数。其各分量计算如下:
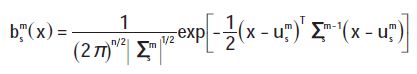
总的概率输出即为各分量的加权和:
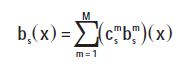
式中:s表示当前状态;M为混合分量数;u,Σ ,c分别为各混合分量的均值矢量、协方差矩阵和混合分量系数。
该算法利用Viterbi译码的过程进行帧同步的搜索,易于实时实现,也容易纳入语法信息。考虑到系统的实时实现性,本技术方案采用Viterbi译码作为系统的搜索算法。
5 试验结果
在汉语全音节与词组混合的语音识别任务中,得到的初步实验结果为:PC微机浮点算法条件下正确覆盖率不低于98%,定点算法的正确覆盖率不低于97%。DSP嵌入系统定点条件下正确覆盖率不低于96%。系统的响应时间满足实时识别的要求。通过测试组严格的检查及抽样测试,证明上述结果真实可靠,该输入法基本达到实用化要求。
6 结语
语音汉字输入技术的研发是具有重大经济和社会意义的课题,该项目采用孤立语音的全音节和词组的混合识别模式,使用连续概率分布非特定人的声学模型,并辅以多候选的人机交互方式,较好地实现了在移动(便携式)电子设备上资源有限的条件下方便快捷的汉字语音输入。
- 基于DSP和机器人的声控系统设计与实现(02-21)
- CEVA携Sensory力推先进的语音识别解决方案(02-12)
- NEC开发出在噪声环境下进行语音操作智能机的技术(04-10)
- 基于语音的终端映射技术如何实现智能交互?(04-30)
- 解析语音识别技术在手机中的应用(06-16)
- Nuance语音识别技术及解决方案(11-16)