SHARC处理器的起源和演进
时间:08-25
来源:
点击:

第四代SHARC系列--ADSP-2146x
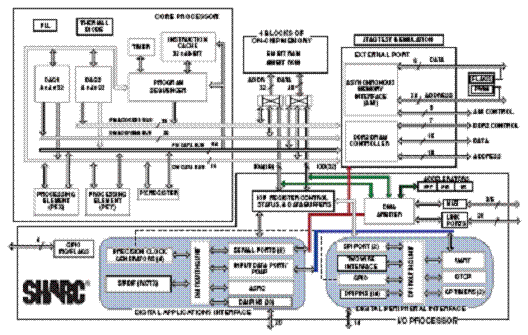
第三代SHARC处理器在优化性价比方面取得了成功,推动浮点处理器进入了对成本敏感的消费类应用,而这类应用曾被人们认为是不可能使用昂贵的浮点处理器的。
ADI公司现在面临着一个有意思的挑战:如何进一步改进具备优异性价比的浮点处理器?
在定义第四代处理器时,产品开发团队注重的是核心价值,正是它们使得SHARC一直处于浮点DSP技术的前沿:
? 市场领先性能
? 架构平衡
? 性能可扩展性
? 智能集成
下面将详细介绍上述每个关键的方面
ADSP-2146x性能增强
在ADSP-2136x系列内核改进的基础上,ADI的SHARC开发团队制定了更高的性能目标,并采用台积电(TSMC)的65nm硅工艺继续优化性能和成本平衡。通过仔细的工程设计和规划,ADI在2008年11月正式发布了ADSP-2146x系列处理器,其内核性能可达450MHz,与最接近的竞争产品相比几乎高出30%。然而,ADI设计团队并不满足于仅仅增强性能,开始寻求创新的方式来大幅度提高运算性能,同时对功耗和成本的影响降至最小。
许多工程师利用浮点处理器提供的宽动态范围实现各种算法,如图案检测、数据压缩/解压缩、加密/解密和自适应滤波。在其中的许多运算密集型算法中,快速傅里叶变换(FFT)、有限冲击响应(FIR)滤波器和无限冲激响应(IIR)滤波器等一些基本的信号处理单元得到了广泛使用,并作为大多数数字信号处理应用的基础。专注于这些内核信号处理构建模块的ADI公司开始将这些功能集成进2146x DMA架构中,以便进一步增强SHARC内核的450MHz性能。
在简单的编程模型基础上,DSP工程师可以将这些"加速器"的每个看作是一个简单的外设。每个加速器配置有自己的本地存储器用于数据和系数存储,从而不会增加内核处理器的开销。另外,还有一组加速器专用寄存器用于设置加速器,包括主存储器中的系数起始地址、计数器等信息。当设置完成后,程序就开始按顺序运行,用户只需简单地等待表示处理结束的中断。
FIR加速器包含一个1K字的本地存储器用于存储系数,另外1K字的存储器用于存储延时线数据。FIR运算单元包括4个并行的MAC(乘法累加)单元,每个单元的工作频率是内核时钟频率的一半。运算单元都能够利用80位精确累加器执行32位浮点或32位定点处理。理论上,除了内核提供的2.7G Flops性能外,这个引擎还能提供1.8Gflops的处理能力。因此与第三代产品相比,第四代产品大体上将可用浮点性能增加了一倍。
FIR加速器可以用于单次迭代模式,这意味着完整的滤波器实现可以适配进本地存储器(滤波器长度<=1024),或者也可以设置FIR加速器以支持多次迭代模式。在多次迭代模式,支持的最大FIR滤波器长度是4096个抽头。为了提高灵活性,用户可用的窗口尺寸变化范围可从1到1024个样本,而针对多速率滤波器(插值/抽取)和多通道滤波器(最多32个信道)的附加模式组成了完整的功能规范。
这种FIR加速器和额外的IIR/FFT加速器为各种信号处理应用提供了创新的低性价比提升方式,再次突出了ADI做出的以最小成本开销实现领先性能的承诺。
ADSP-2146x架构平衡考虑
由于ADSP-2146x系列处理器可以提供2.7GFlops的内核运算性能,存储器密集系统的设计师面临的主要挑战是管理来去各种存储器和外设子系统的数据传送。如果在设计阶段没有考虑这些要求,内核可能由于较慢的大容量存储器而被迫等待新的数据进行处理,或由于多个系统资源存取相同存储区域而导致内核死机。为了尽量减小这些潜在的瓶颈,ADSP-2146x系列内置了最多达67个直接存储器存取(DMA)通道用于外设和内存之间的数据传送。同时集成了工作频率达内核时钟频率一半的16位DDR2接口,使得用于存储密集型应用时的性能最大。这种内核与外部存储器之间的1:1时钟比例极大地促进了数据的快速传送,并且开销很小,还能支持其它功能,比如从外部存储器中直接执行代码。
内部SRAM资源增加到了5Mb,这是所有SHARC处理器中最大的存储器容量。连接内核的带宽仍是7.2GBps,因此保证了内部运算任务的高速执行。这种存储器在架构上被划分为4个不连续模块(模块0-模块3),允许从多个系统资源同时进行零开销访问。
为了进一步优化存储器的使用,ADI开发出了名为VISA(可变指令集架构)的内核增强特性。到第三代处理器为止的所有SHARC用的都是48位的固定指令长度。对于经常使用的指令来说,这会导致非最优的PM代码存储器使用。这些指令经过优化,去除了操作码中的冗余位,产生了新的16位和32位宽指令。程序序列发生器经过更新以识别这些新的优化指令,从而使PM代码效率提高近20%。为了实现后向兼容,VISA模式是源代码编译器的一个选项,这意味着希望保持二进制代码兼容性的用户可以继续使用原来的48位方法学。
所有上述架构增强特性都使系统开发人员能以最佳的、用户友好的方式充分利用ADSP-2146x的高性能资源。
- 基于Blackfin处理器的继电保护完整解决方案解析(02-01)
- 风电要并网,智能电网是关键(08-05)
- 定点处理器VS浮点处理器:如何优化您的选择? (03-24)
- 利用SHARC处理器成就顶级音频系统品质(10-30)
- 让新型SHARC处理器满足“一高二低”的浮点设计需求(04-14)
- ADI公司的SHARC处理器让电吉他效果器无所不能(01-17)