谷歌TPU也危机了?Graphcore推出的IPU是个什么鬼
者计算部分在一定时刻可能成为瓶颈,而另一个则不能充分使用它的功率预算。
换一种思路,我们假定计算和通信串行执行,并不重叠,都充分使用最大的能量运行。那么,无论实际工作量如何平衡,该程序都有可能在最短的时间内完成。因此,这也是一种效率更高的方式。
4. 多核通信方式
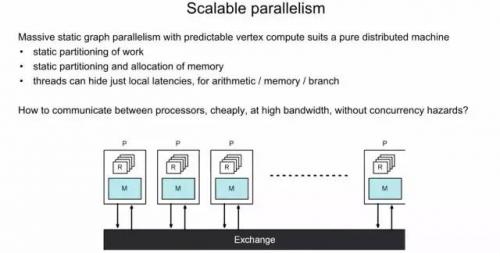
前面简单介绍了IPU采用了同构多核的方式,分布式的本地存储(没有共享存储)。另外,也介绍了它的"运算和通信的串行执行"的特色。那么在这种架构下,如何实现多个内核间的通信和同步呢?Bulk Synchronous Parallel的同步计算模型。
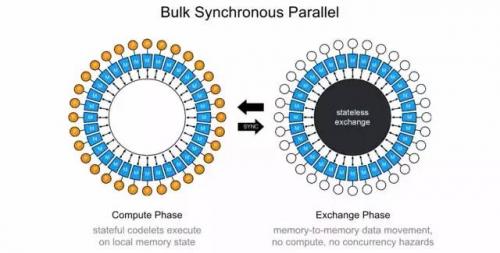
这又是一个上世纪80年代提出的技术。它的基本操作可以分为三个:1) 本地计算阶段, 每个处理器只对存储本地内存中的数据进行本地计算。2) 全局通信阶段, 对任何非本地数据进行操作,包括核间数据的交换。3) 栅栏同步阶段, 等待所有通信行为的结束。可以看出,这实际上和上一节介绍的 "运算和通信的串行执行"是一致的,也和IPU的多核local memory架构很一致。
5. 工具
Graphcore提供的工具叫Porlar,题图的图像就是这个工具生成的。
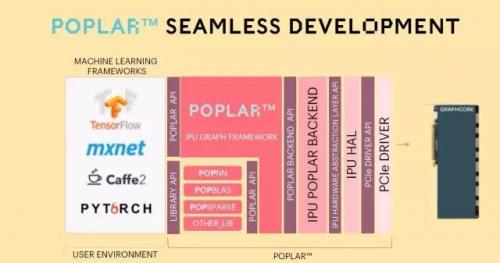
对于工具也不想多说了,一般大家承诺都不错,都是参照CUDA的配置,但实际效果。。。也只能试用了再评判。不过Graphcore目前只有50名员工,工具能否成熟还是有疑问的。
总结:
总的来说,从目前公布的信息来看,Graphcore的IPU在架构设计上还是有很多想法的, 非常值得讨论。不过,感觉上IPU这种同构多核架构在Cloud端应用应该更合适一些。虽然他们认为IPU的架构有很好的伸缩性,放到Edge 和Embedded应用也没问题,但我个人感觉是,这种架构顶多支持到自动驾驶,对于功耗成本要求更严苛的需求,还是更专用的架构(异构架构)更合适一些。
- 嵌入式存储器的设计方法和策略(05-12)
- DSP中的存储器共享与快速访问技术设计(06-28)
- 基于DBL结构的嵌入式64kb SRAM的低功耗设计(10-15)
- 基于NiosII的SOPC多处理器系统设计方法(02-10)
- 提高存储器子系统效率的三种方法(04-07)
- 铁电存贮器FRAM技术原理(06-08)