谷歌TPU也危机了?Graphcore推出的IPU是个什么鬼

和CPU (scalar workload),GPU (low-dimensional workload)相比,IPU是为了high-dimensional graph workload而设计的。下面我们就看他们的一些比较有参考价值的设计上的考虑。
3. 架构设计的考虑
首先,他们也给出了一些会限制MI处理器的性能的因素,比如:1) Rate of arithmetic 2) Bandwidth or latency of data access (parameters, activitions, samples) 3) Rate of address calculation (high-dimensional models) 4) Rate of generation of random numbers (stochastic models)。但最后给出了最重要的限制因素,power。
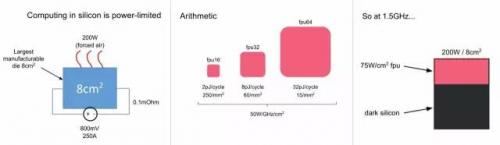
上图最左边说明一些功耗限制因素;中间对比了不同的浮点运算单元大体的面积和功耗;最后说明,如果给定功耗的面积的限制,芯片运行在1.5GHz,则芯片中只能有1/3的面积能够作为fpu(float point unit)运行。除非降低时钟频率,否则芯片中的很大一部分将无法工作(dark silicon)。
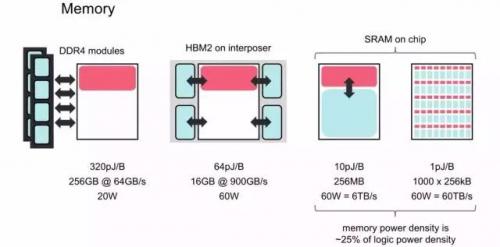
另外一个重要问题是存储。对于机器智能任务,GPU和CPU的性能受到其对外部存储器的带宽的限制。传统的外部DRAM系统(如DDR4或GDDR5)带宽太低,而且没有伸缩性。HBM在具有非常高的布线密度的硅衬底上使用垂直堆叠的DRAM die,其物理上非常接近处理器die。但它的生成困难,目前只用在最先进的芯片之中。此外,它把DRAM带入处理器的thermal envelope之中,因此处理器只能以较低速度运行。HBM2虽然能够提供更多的带宽(目标是1TByte/s),但仍然存在上述问题。最后一种类型的memory片上的存储SRAM,虽然相对性能好很多(访问速度快,功耗低,功耗密度相对逻辑电路也比较低),但是由于芯片面积主要用于逻辑运算,一般不会在芯片上使用太多SRAM。
但是,和常见的芯片架构不同,IPU采用了大量分布式片上memory的设计。这非常激进的方法,其目标是把所有的model都能够放在片上memory当中,如下图所示。具体来讲,IPU把大量的面积用于SRAM,所谓memory-centric chip,而适当减少运算单元fpu的面积,最终实现对power的充分利用。而GPU主要使用片外的memory,片上的面积中只有40%用于Machine Learning(fpu),而其它的50%的面积用于其它应用(Grahics,HPC)。由于GPU本身是面向多种应用的,这种设计也是很合理的。
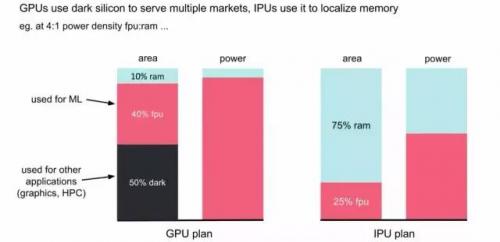
当然,即使在IPU上集成尽可能多的SRAM,容量也很难和GPU连接片外的DRAM相比。但是,对于很多模型来说,这个容量已经够用。而SRAM可以以100倍的带宽和1/100的延迟来访问,这种优势是非常明显的。技术模型的规模太大无法放到片上的memory中,还可以通过多个IPU互连来及解决问题。IPU采用的同构多核的方式,也让这种扩展比较简单。
另外,Graphcore看起来并不是非常担心内存容量的问题。他们的依据包括:
1. 目前对于减少机器智能的内存占用已经有不少好的方法,也有很大潜力。
2. IPU不需要用一些数学变换将卷积转换成矩阵乘法(貌似可以直接做卷积)。这些变换往往会增加存储的需求。另外,IPU不需要很大的Batch来提高并行的效率。
3. 可以通过重新计算来节省内存。例如,在GPU的DNN训练期间使用的大部分内存是存储正向传递中activitions,以便我们可以在反向传播期间使用它们。一个有效的替代方法是只保存定期快照(Sanpshot),然后在需要时从最近的快照重新计算这些activitions。这种方法可以减少一个数量级的存储,而计算只增加了25%。
我的看法:
之前和朋友讨论过在片上采用大量memory来保存所有模型参数的方法,不是很看好。Graphcore竟然采用了更激进的架构,甚至不直接外接DDR,还是比较出乎意料的。不过Graphcore给出的说明基本是可以支持他们这个架构选择的,也同时给了我们一个很不错的思路。希望后面能有更多细节和数据供我们分析。
4. Serialise computation and communication
Graphcore提出,"Silicon efficiency is the full use of available power"。因此,他们还提出一些更进一步优化效率的方法。其中比较有意思的是运算和通信的串行执行。这个提法听起来比较奇怪。我们一般都是希望运算和通信并行化,最好是能在Computation的过程中完成下一次communication,这也是很多架构优化的一个方向。但是,如果是在一个功耗受限的系统中,情况可能就不是这样了。
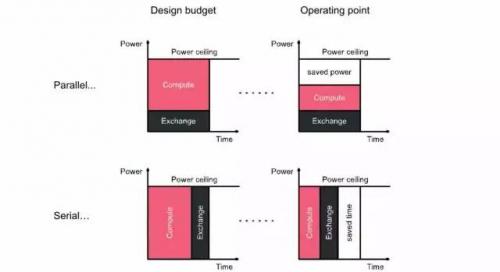
上图的上半部分是传统的方法。我们希望处理器间通信与计算重叠,因此可以根据预期的工作负载来分配这两者之间的功率预算。但是,在实际运行的时候,应用程序具有不同的平衡,结果往往是程序在一定时间内完成,但是消耗了较少的能力。这是因为通信或
- 嵌入式存储器的设计方法和策略(05-12)
- DSP中的存储器共享与快速访问技术设计(06-28)
- 基于DBL结构的嵌入式64kb SRAM的低功耗设计(10-15)
- 基于NiosII的SOPC多处理器系统设计方法(02-10)
- 提高存储器子系统效率的三种方法(04-07)
- 铁电存贮器FRAM技术原理(06-08)