都想吞下人工智能这个蛋糕,CPU/GPU/FPGA有何高招?
看,围绕现有处理器的主流改进方式有两个:
图形处理器通用化:将图形处理器GPU用作矢量处理器。在这种架构中,GPU擅长浮点运算的特点将得到充分利用,使其成为可以进行并行处理的通用计算芯片GPGPU。英伟达公司从2006年下半年已经开始陆续推出相关的硬件产品以及软件开发工具,目前是人工智能硬件市场的主导。
多核处理器异构化:将GPU或FPGA等其他处理器内核集成到CPU上。在这种架构中,CPU内核所不擅长的浮点运算以及信号处理等工作,将由集成在同一块芯片上的其它可编程内核执行,而GPU与FPGA都以擅长浮点运算著称。AMD与Intel公司分别致力于基于GPU与FPGA的异构处理器,希望借此切入人工智能市场。
三、现有市场--通用芯片GPU
在深度学习的领域里,最重要的是数据和运算。谁的数据更多,谁的运算更快,谁就会占据优势。因此,在处理器的选择上,可以用于通用基础计算且运算速率更快的GPU迅速成为人工智能计算的主流芯片。可以说,在过去的几年,尤其是2015年以来,人工智能大爆发就是由于英伟达公司的GPU得到广泛应用,使得并行计算变得更快、更便宜、更有效。
1.GPU是什么?
图形处理器GPU最初是用在个人电脑、工作站、游戏机和一些移动设备上运行绘图运算工作的微处理器,可以快速地处理图像上的每一个像素点。后来科学家发现,其海量数据并行运算的能力与深度学习需求不谋而合,因此,被最先引入深度学习。2011年吴恩达教授率先将其应用于谷歌大脑中便取得惊人效果,结果表明,12颗英伟达的GPU可以提供相当于2000颗CPU的深度学习性能,之后纽约大学、多伦多大学以及瑞士人工智能实验室的研究人员纷纷在GPU上加速其深度神经网络。
2.GPU和CPU的设计区别
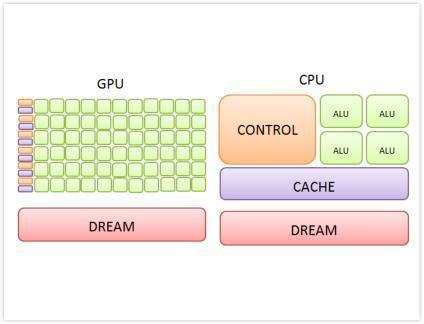
那么GPU的快速运算能力是如何获得的?这就要追溯到芯片最初的设计目标了。中央处理器CPU需要很强的处理不同类型数据的计算能力以及处理分支与跳转的逻辑判断能力,这些都使得CPU的内部结构异常复杂;而图形处理器GPU最初面对的是类型高度统一的、相互无依赖的大规模数据和不需要被打断的纯净的计算环境,所以GPU只需要进行高速运算而不需要逻辑判断。目标运算环境的区别决定了GPU与CPU不同的设计架构:
CPU基于低延时的设计
大量缓存空间Cache,方便快速提取数据。CPU将大量访问过的数据存放在Cache中,当需要再次访问这些数据时,就不用从数据量巨大的内存中提取了,而是直接从缓存中提取。
强大的算术运算单元ALU,可以在很短的时钟周期内完成算数计算。当今的CPU可以达到64bit双精度,执行双精度浮点源计算加法和乘法只需要1~3个时钟周期,时钟周期频率达到1.532~3gigahertz。
复杂的逻辑控制单元,当程序含有多个分支时,它通过提供分支预测来降低延时。
包括对比电路单元与转发电路单元在内的诸多优化电路,当一些指令依赖前面的指令结果时,它决定这些指令在pipeline中的位置并且尽可能快的转发一个指令的结果给后续指令。
GPU基于大吞吐量的设计
压缩缓存空间Cache,从而最大化激发内存吞吐量,可以处理超长的流水线。缓存的目的不是保存之后需要访问的数据,而是担任数据转发的角色,为线程提高服务。如果有很多线程需要访问同一个数据,缓存会合并这些访问,再去DRAM中访问数据,获取的数据将通过缓存转发给对应的线程。这种方法虽然减小了缓存,但由于需要访问内存,因而自然会带来延时效应。
高效的算数运算单元和简化的逻辑控制单元,把串行访问拆分成多个简单的并行访问,并同时运算。例如,在CPU上约有20%的晶体管是用作计算的,而GPU上有80%的晶体管用作计算。
3.GPU和CPU的性能差异
CPU与GPU在各自领域都可以高效地完成任务,但当同样应用于通用基础计算领域时,设计架构的差异直接导致了两种芯片性能的差异。
CPU拥有专为顺序逻辑处理而优化的几个核心组成的串行架构,这决定了其更擅长逻辑控制、串行运算与通用类型数据运算;而GPU拥有一个由数以千计的更小、更高效的核心组成的大规模并行计算架构,大部分晶体管主要用于构建控制电路和Cache,而控制电路也相对简单,且对Cache的需求小,只有小部分晶体管来完成实际的运算工作。所以大部分晶体管可以组成各类专用电路、多条流水线,使得GPU的计算速度有了突破性的飞跃,拥有了更强大的处理浮点运算的能力。这决定了其更擅长处理多重任务,尤其是没有技术含量的重复性工作。
当前最顶级的CPU只有4核或者6核,模拟出8个或者12个处理线程来
- 基于S3C2410和UDAl34l的嵌入式音频系统设计(02-11)
- 苹果Airplay技术打造无线互联智能家庭(05-13)
- Intel Atom再进化:Clover Trail+技术详解(01-27)
- 基于单片机的微控制器在系统编程(08-31)
- 半导体产业或掀整并潮(09-02)
- 一种基于FPGA的接口电路设计(11-18)