基于GPU的数字图像并行处理研究
GPU上的片段程序进行图像处理的,而GPU片段着色器的直接渲染输出是一个帧缓冲区,它对应着计算机屏幕上的一个窗口,传统上用来容纳要显示到屏幕的像素,但是在GPU流式计算中可以用来保存计算结果。虽然CPU可以通过3D API直接读写这个帧缓冲区,将渲染处理的结果从帧缓存中复制到系统内存进行保存,但是帧缓存的大小受窗口大小限制,而且由于AGP总线的带宽限制(2.1GB/s),从显存到系统内存的数据回读操作效率低下。对于大幅影像的处理应用是显然不适合的,特别是在中间计算结果的保存反馈时,采用帧缓存方式将成为制约GPU性能发挥的最主要瓶颈。
针对以上问题,笔者利用离线渲染缓存Pbuffer作为输出缓存。Pbuffer是OpenGL1.3版本的WGL_ARB_pbuffer扩展提供的输出缓存,它通过在显存中开辟一个不可见的数据缓冲区,取代帧缓存来保存片段处理器的输出结果。如果这个结果只是中间计算数据,还可以采用渲染到纹理的技术,把Pbuffer中的数据绑定到一个纹理,供下一遍绘制的片段程序取用,减少数据在显存和系统内存之间的传输,实现整个数据流在GPU芯片内部的流转,显著提高数据的反馈速度。特别是在需要GPU反复执行的情况下,可以构造两个Pbuffer,交替的作为输入或输出纹理使用,产生所谓的"Ping-Pong"方法,有效避免中间计算结果的回读操作。
图像卷积运算的GPU并行化试验
卷积运算是一种常见的数字图像处理局部运算,通过选择不同的卷积核,可以实现不同的图像处理效果。图像卷积运算定义为: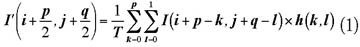
式中,为卷积运算以后的图像;为待处理的图像;为卷积核;T为常数,当卷积核中所有系数之和不为零时,T等于所有系数之和,否则等于1。
试验平台与数据
硬件平台为: Intel Core 2 2.0GHz CPU,1GB系统内存,NVIDIA公司的GeForce G0 7400 GPU, 512MB显存。
软件平台:Windows XP操作系统,CPU程序开发环境为Microsoft Visual C++2005,三维绘制接口为OpenGL及其扩展库WGL_ARB_pbuffer,GPU程序开发语言为Cg。
所采用的试验数据有两组,如图2所示:
第一组为:截取的新加坡部分地区QucikBird卫星影像,大小为(像素);
第二组为:截取的黄河小浪底部分地区Spot4卫星影像,大小为(像素)。
(a)试验数据一
(b)试验数据二
图2 卷积运算试验数据
试验步骤与数据记录
为了进行多组数据的对比试验,首先对原始图像数据进行预处理,通过裁减获得大小分别为2048×2048、1024×1024、521×512、256×256、128×128的试验数据。
以经过预处理的10幅不同大小的图像进行卷积运算对比试验,分别运行卷积平滑和卷积锐化的CPU和GPU程序,并记录处理时间。试验所用的平滑卷积核h1为式(2),锐化卷积核h2为式(3):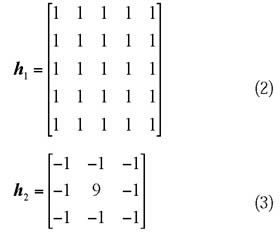
试验结果与分析
图3所示为图像数据二512×512的平滑和锐化试验的处理结果,图4为GPU加速效率对比图。
(a)卷积平滑后图像
(b)卷积锐化后图像
图3 数据二的图像平滑、锐化效果对比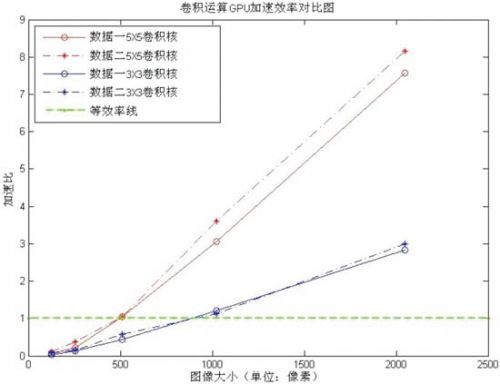
图4 卷积运算GPU加速效率对比图
从图4可以看出:随着图像的增大,特别是卷积核的变大,GPU的加速效果更加明显,例如:对2048×2048大小的图像进行5×5的卷积运算,最高加速比达到了8倍多。但是,在图像数据较小时,由于OpenGL的初始化和纹理数据的加载耗费了大量的时间,使得GPU并行处理的优势消失,甚至还没有CPU处理的速度快。
结语
本文对GPU的并行性和数字图像处理算法的并行层次进行了简要的介绍,提出了像素级图像处理的GPU并行化实现方法,并对其基本流程和关键技术:数据的加载,计算结果的反馈与保存等问题进行了详细论述,最后通过图像的平滑和锐化的卷积运算证明了GPU在数字图像并行化处理方面的强大优势。
- NVDIA CUDA--GPU计算的革命(06-08)
- GPU-前途无限光明(06-08)
- 众核多计算模式系统的构建(01-16)
- 移动处理器发展新方向,整合更多的GPU将成为主流?(12-01)
- APU与GPU共进 AMD抢攻嵌入式应用(02-13)
- Imagination:我们的移动GPU技术一骑绝尘(04-13)