第15章 汉字基础知识介绍
第15章 汉字基础知识介绍
本期教程跟大家介绍一下字体显示方面的一些知识,因为字体显示在实际项目中用到的地方还是很多的。特别是汉字的显示,在实际项目中用到的最多,也是经常容易出问题的。借本期教程给大家详细的讲解一下字体原理和显示方面的东西,主要点阵字体。
15 1 汉字点阵
15. 2 点阵原理
15. 3 字库的建立及其原理
15. 4 汉字点阵在汉字库中的地址计算公式
15.5 总结
15.1 汉字点阵
在嵌入式设备 LCD 上显示的汉字大多数都属于点阵汉字。常用的点阵字库来自UCDOS。大家可以去网上下载一个 UCDOS 的完全安装版本,里面可以找到很多点阵字库文件。下面几个字库文件是常用的:
HZK12 : 12 点阵汉字库(宽度 x 高度 = 12x12)
ASC12 : 12 点阵 ASCII 字库(宽度 x 高度 = 6x12)
HZK16 : 16 点阵汉字库(宽度 x 高度 = 16x16) 最常用的中文字库
ASC16 : 16 点阵 ASCII 字库(宽度 x 高度 = 8x16)最常用的 ASCII 字库
HZK24 : 24 点阵汉字库(宽度 x 高度 = 24x24) 票据打印机用得较多
UCDOS 的字库排列标准符合国标一、二级字库标准,即 GB2312,汉字个数为 6000多个。按照汉语拼音顺序排列,前面一部分是一级常用汉字大约 2000 多个,后面一部分是二级汉字大约 4000 多个。 大多数情况下,一二级字库就可以满足我们的需求。但是在某些特殊应用(比如显示每个人的姓名)中可能需要用到 GB18030 字库,该字库除了包括一、二级字库外还包含很多不常用的汉字,总汉字个数为 27538 个。
下面是 GB18030 字库点阵的截图。

这个放大的汉字就是二级字库中最后一个汉字,这个字后面的汉字就属于 GB18030特有的汉字了。估计大多数人一个都不认识。
我们来看看 GB18030 字库最后区域的汉字长得啥样子。

15.2 点阵原理
简单的理解,一个字的点阵是指这个汉字用多少个象素点来描述. 每个象素点显示为什么颜色。下面举一个:HZK16: 16 点阵汉字库(宽度 x 高度 = 16x16)给大家说明一下:
HZK16每个字型的点阵数据为 16×16(横行点数×纵列点数),共 256 个二进制位,32 个字节。 汉字 16 点阵字型数据的 32 个字节排列次序是以 0 字节开始到 31 字节结束,均用十六进制表示,其记录格式如下:
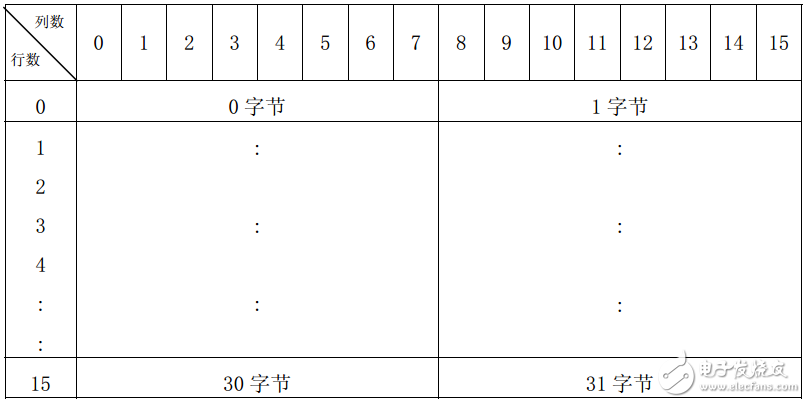
以一个点阵汉字“啊”为例给大家说明下:

0x00,0x00,0x0E,0xFC,0xEA,0x08,0xAA,0x08,
0xAA,0xE8,0xAA,0xA8,0xAC,0xA8,0xAA,0xA8,
0xAA,0xA8,0xAA,0xA8,0xEA,0xE8,0xAA,0xA8,
0x0C,0x08,0x08,0x08,0x08,0x28,0x08,0x10
大家明白了点阵字库的排列原理,编程实现汉字显示就比较容易了。这里汉字的显示有一个前景色和背景色的问题,整个256个点阵中的啊字所占的地方就是前景色,其余的都是背景的。
15.3 字库的建立及其原理说明:这部分知识来自UCGUI论坛的站长所写,这里稍稍做了修改使其语句通顺。
前面讲完了汉字点阵,现在讲解下点阵如何存放, 读者也应该了解。通常情况下, 一般的DOS下的程序都会提供一个汉字库, 这样在脱离汉字平台(如UCDOS)的支持下也可以进行汉字显示,但是这样会存一个问题, 就是如果每个DOS下的程序员都这么做的话, 就会造成一定的磁盘空间浪费. 所以有的DOS下的程序,针对自己所需要的汉字,就会定制自己的小型字库, 那么字库的制作到底应该如何进行呢? 下面我们将就这个问题进行一些基本的讨论:
众所周知,一个ASCII字符占一个字节,它的数值从0到255, 那么汉字字符将如何与ASCII字符区别开来呢?实际上,仔细观察ASCII字符表,从第161(即0xa1)个字符开始,后面的字符并不经常为E文所使用。充分利用这一特性,将161-255之间的数值空间作为汉字的标识码。既然255-161 = 94不能满足汉字容量的要求,就将每两个字符并在一块(即一个汉字占两个字节),显然,94*94 =8836基本上已经满足了常用汉字个数的要求。从以上的讨论可以知道, 用二个字节来表示一个汉字, 其原因就是上面说的, 这个就是我们常说的汉字机内码, 一个汉字的机内码是由值都大于0xa1的值组成的。
说完机内码, 有的朋友可能就会问题, 机内码与建立汉字字库有什么关系呢?
我们常见的标准的汉字字库HZX16(点阵16*16),HZK24(24*24)两种。由上面的讨论我们得知,一个汉字点阵须要256个象素点阵来表示, 我们采用一个字节的8位来表示八个象素, 其须32个字节;字库中要存放的是所有常用的汉字的二进制点阵数据, 它的存放是有序的, 下面我们说一下这个顺序:首先,对于"我"字来说, 它的机内码是0xce,0xd2; 机内码每个字节均从0xa1开始, 那么我们已经采用的建立点阵字在库中的索引方法是将整个字库里面的汉字是94*94的二维数组, 要找任意一个汉字的点阵, 就须要知道这个汉字在这个二维数组当中的X维与Y维.
X维 = (机内码字节1-0xa1) & 0x7f;
Y维 = (机内码字节2-0xa1) & 0x7f;
求汉字在X,Y维后, 那么按照每个汉字占用32个字节, 则可以得出汉字相对于字库头的偏移是
offset = (x*94 + y)*32;
其实,X与Y就是汉字的区位码, 汉字的区位码是从0-94的。但实际上只用了16-87,其中一级汉字在16-55。二级汉字在56-87是按照一定的规则来确定区位码的。对于一级汉字,是按拼音首字母级笔划.二级汉字是按部首来的。比如‘啊’字可以知道:
啊----------区位码(x = 15, y = 0)offset=b040机内码:(0xb0,0xa1);
其中,区位码(x=0-14)与(88-94)都是没有对应汉字的。字库中实际的对应汉字点阵字数为94*72=6768个汉字。实际上,一个字库中有前16*32个字节没有表示具体的汉字的, 在字库里被用来表示什么东西没有什么具体的要求, 如果说你自己要做一个字库。那么这一段你可以自己发挥, 填充为一个中文的符号,笑脸,特别文字什么的.这些没有具体的要求。同理,对于(88---94)*32, 你也可以自己发挥. 然后告知别人如何使用,因为这个没有标准, 所以一定要有特别的说明,别人才可以使用。
15.4 汉字点阵在汉字库中的地址计算公式有了上面的基础,汉字点阵在汉字库中的地址也就很计算了。
汉字由两个字节来表示。前一个字节为该汉字的区号,后一个字节为该字的位号。每一个区记录 94 个汉字,位号则为该字在该区中的位置。
计算公式为: (94*(区号-1)+位号-1) * 一个汉字字模占用字节数
对于 16 点阵的字库,1 个汉字字模占用 32 字节。对于 12 点阵字库,字摸每行的位数均补齐为 8 的整数倍,于是实际该字库的位长度是 16*12,即占用 24 字节。
我们在计算机中常用的汉字编码为汉字内码,不是区位码,需要进行转换。因此最终的计算公式为:
ADDRESS = [(内码1-0xa1) * 94 + (内码2-0xa1)] * 32
这个计算结果是相对全角空格字符的相对地址。
下面再推荐给大家一个非常好用的工具,专门用于查看和分析国标点阵字库的软件

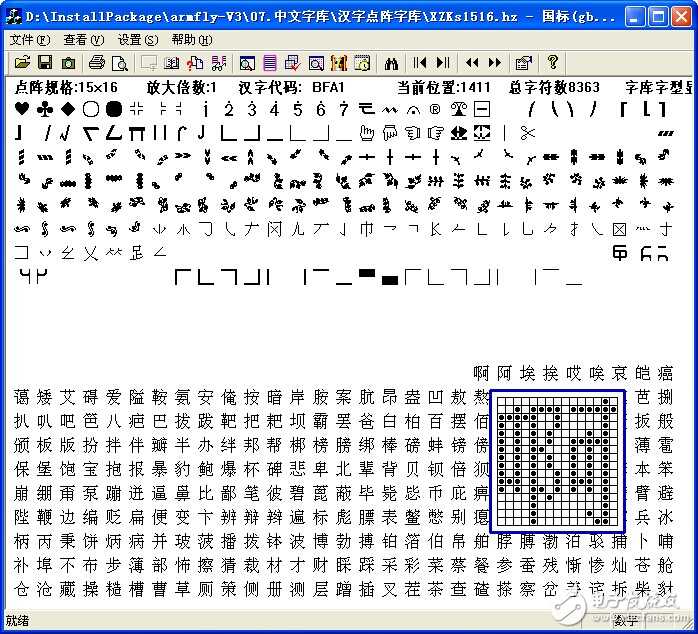
这个程序仅支持 8 个字符的文件名,要求文件名的最后 4 位数字表示点阵的大小。 比如我们要分析 HZK16 文件,可以将文件名修改 HZKs1616.hz , 然 后 用FONTSHOW.exe 程序打开。
15.5 总结关于汉字点阵的基础知识就跟大家说这么多,以前对点阵汉字还没有了解的同学可以在开发板上面写一个裸机的程序实现下,或者参考开发板现成的例子研究下。这样就能对点阵汉字有更好的理解了。