應用系列之二 - 生醫資訊之BLESS演算法
时间:10-02
整理:3721RD
点击:
前言:
繼上一篇我們知道如何使用BLAST來擷取有用的DNA片段,但在這之前我們的Dataset是需要經過精煉過的,即任何DNA定序過程,因為多半透過生物或者化學反應,因此常會產生含有錯誤基因組(Base Pair)的DNA片段,因此我們必須在進行Alignment之前先對DNA片段進行Correction,以下提出近期發表的高效演算法-BLESS,此演算法已經演進到第二版,本Demo將以第一版作為應用,完整版Source code可在官方source forage下載https://sourceforge.net/p/bless-ec/wiki/Home/,本Demo只是闡述BLESS的核心邏輯
準備:
1. C6655開發板
2. TL-XDS200模擬器,箱內有附
3. 12V 2A Adapter(電源),箱內有附
4. USB TypeB傳輸線,箱內有附
1. 問題描述: Illumina是現今常用的Next-generation DNA定序技術,透過在玻璃片上的載子和打碎的DNA樣本進行DNA另一股的複製,在玻璃片上長出相對的一股DNA片段,其中使用有顏色的試劑輔助反應,因此DNA上的Base Pair就有4種顏色,之後雷射光進行判定顏色(A C T G),這是主要的過程,之間牽涉到了生物和化學反應,由生物反應DNA的另一股,由化學反應產生有顏色的標記,因此過程中可能會產生錯誤的基因組,我們必須將定序好的結果來作校正,才能作之後的相關研究
2. BLESS是2014年由UIUC提出的高效演算法http://www.ncbi.nlm.nih.gov/pubmed/24451628,此演算法用來改進以往的Correction演算法,大量的記憶體用量和執行時間,大幅度降低了設備的需求,因此被廣泛引用和推廣,本篇就是模擬BLESS演算法核心邏輯設計而成的Demo
3. BLESS主要使用到Bloom-filter來加速運算,一般也用在機器學習(Machine Learning)的領域,以下就稍微講述其原理
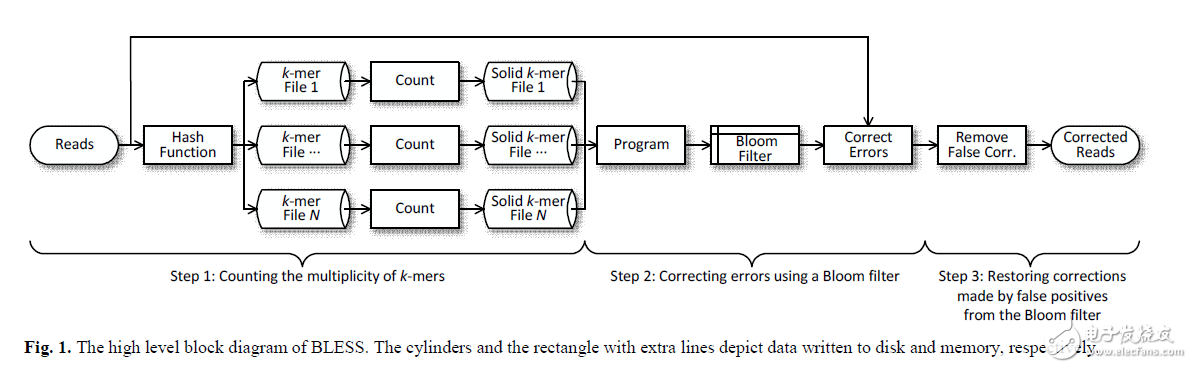
完整的BLESS演算法三步驟,這Demo簡化了第三步驟,假定誤判機率為0%,所以不做額外回復動作
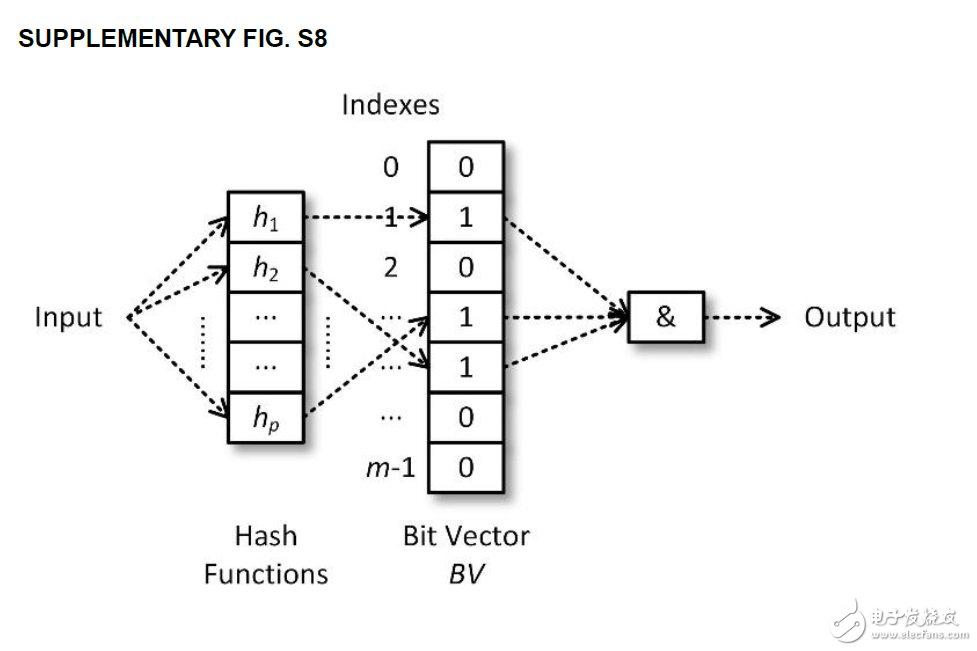
Bloom-filter將透過N個hash function作映射,將每個Bit vector上對應到的index的值改為1,之後進行查詢的時候,對應的index需要都為1,取AND運算之後結果才為1,若結果為1,則Input的k-mers(DNA小片段)即很可能為Solid的基因組,反之則為Weak的基因組
4. 而如何使用這些結果和整個Correction的過程,如下圖所示
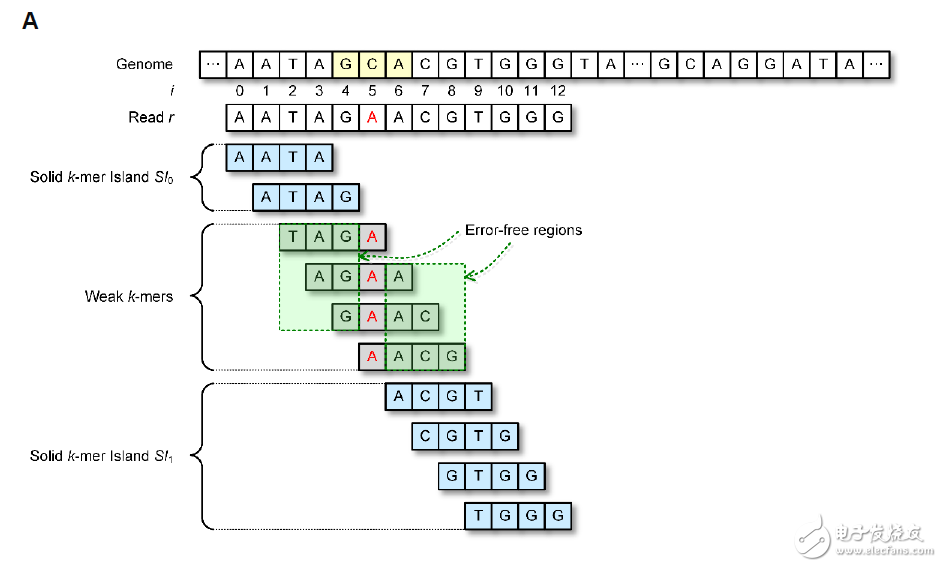
由圖中可得知A是一個錯誤的基因組,因此包含他的都屬於Weak的k-mers,利用Bloom-filter查詢後的結果來決定修正為哪個基因組,上述即是C G T三種可能,依照可能的基因組產生一條路徑
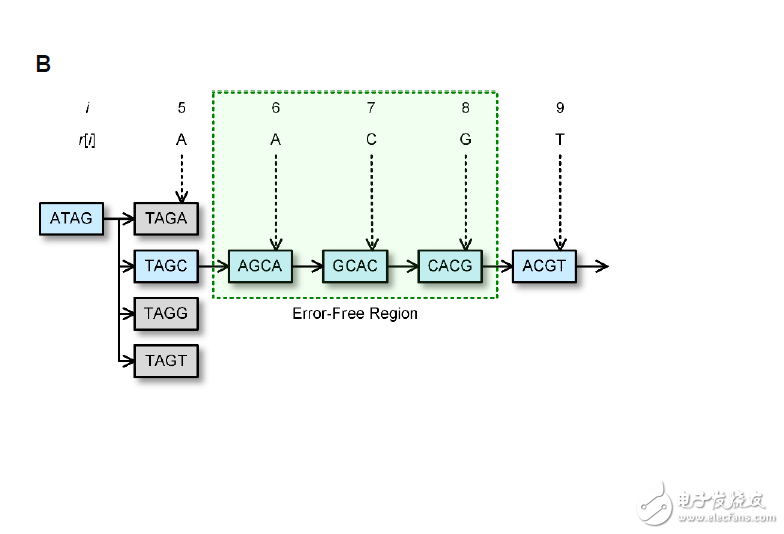
只有被判定為最有可能的基因組會繼續延伸,圖中選擇了TAGC這條路徑

同樣地,這個Case包含了兩個錯誤基因組,一樣進行Bloom-filter的查詢

透過數次的查詢比對,演算法可以決定出最正確的路徑,即最有可能的基因序列,將錯誤基因組的給更正
5. 理解了BLESS是如何運作後,開始編寫程式碼,這裡我們簡化Bloom-filter,只產生一個Hash function,創建一個SYS/BIOS專案工程,過程創龍文檔已有詳細的流程,這裡不再贅述
6. 和BLAST有少許類似的實作方式,先定義好一些參數值
- MAXNUM=1000 待測的DNA序列為1000個
- threshold=3; 設定的閥值,超過此值判定為正確的基因組
- r=20; 打散後產生的Reads數,這裡隨機以50為基礎,可多可少,即50~99連續基因組為一個Reads進行打散,將待測DNA序列打散
- Bloom filter的Hash function數=1
- k-mers長度=4
- One Task in SYS/BIOS
- A = 0
- C = 1
- G = 2
- T = 3
7. 打開main.c,輸入以下程式碼:
- /*
- * ======== main.c ========
- */
- #include
- #include
- #include
- #include
- #include
- #include
- int hash[256];
- int bloom[256];
- const int MAXNUM=1000;
- const int threshold=3;
- const int r=20;
- int** reads;
- int* a;
- /*
- * ======== taskFxn ========
- */
- int** spliting (int* data)
- {
- int i,j;
- System_printf("Counting...start,size = %d\n",sizeof(data));
- reads=(int**)malloc(sizeof(int*)*r);
- for(i=0;i =threshold)
- b[i]=1;
- }
- return b;
- }
- int query_bloom (int index)
- {
- return bloom[index];
- }
- int** correction (int** ref,int k)
- {
- int i,j,l;
- System_printf("Correction...start,size = %d\n",sizeof(ref));
- for(i=0;i =threshold)
- {
- hash[ref[i][j]*64+ref[i][j+1]*16+ref[i][j+2]*4+ref[i][j+3]]--;
- hash[l*64+ref[i][j+1]*16+ref[i][j+2]*4+ref[i][j+3]]++;
- ref[i][j]=l;
- System_printf("Reads %d-%d..be corrected\n",i,j);
- break;
- }
- else if(hash[ref[i][j]*64+l*16+ref[i][j+2]*4+ref[i][j+3]]>=threshold)
- {
- hash[ref[i][j]*64+ref[i][j+1]*16+ref[i][j+2]*4+ref[i][j+3]]--;
- hash[ref[i][j]*64+l*16+ref[i][j+2]*4+ref[i][j+3]]++;
- ref[i][j+1]=l;
- System_printf("Reads %d-%d..be corrected\n",i,j+1);
- break;
- }
- else if(hash[ref[i][j]*64+ref[i][j+1]*16+l*4+ref[i][j+3]]>=threshold)
- {
- hash[ref[i][j]*64+ref[i][j+1]*16+ref[i][j+2]*4+ref[i][j+3]]--;
- hash[ref[i][j]*64+ref[i][j+1]*16+l*4+ref[i][j+3]]++;
- ref[i][j+2]=l;
- System_printf("Reads %d-%d..be corrected\n",i,j+2);
- break;
- }
- else if(hash[ref[i][j]*64+ref[i][j+1]*16+ref[i][j+2]*4+l]>=threshold)
- {
- hash[ref[i][j]*64+ref[i][j+1]*16+ref[i][j+2]*4+ref[i][j+3]]--;
- hash[ref[i][j]*64+ref[i][j+1]*16+ref[i][j+2]*4+l]++;
- ref[i][j+3]=l;
- System_printf("Reads %d-%d..be corrected\n",i,j+3);
- break;
- }
- }
- }
- }
- }
- return ref;
- }
- Void taskFxn(UArg a0, UArg a1)
- {
- a =(int*)malloc(sizeof(int)*MAXNUM);
- int i,j,sum=0;
- System_printf("size = %d\n",sizeof(a));
- for(i=0;i<256;i++)
- hash[i]=0;
- for(i=0;i<256;i++)
- bloom[i]=0;
- for(i=0;i<MAXNUM;i++)
- {
- a[i]=rand()%4;
- System_printf("%d",a[i]);
- }
- System_printf("\n");
- spliting(a);
- for(i=0;i<r;i++)
- {
- System_printf("%d...READS\n",i);
- for(j=1;j<reads[i][0]+1;j++)
- System_printf("%d",reads[i][j]);
- System_printf("\n");
- }
- counting(reads,4);
- for(i=0;i<256;i++)
- {
- System_printf("%d = %d\n",i,hash[i]);
- sum+=hash[i];
- }
- bloom_set(bloom);
- correction(reads,4);
- System_printf("Print result\n");
- for(i=0;i<r;i++)
- {
- System_printf("%d...READS\n",i);
- for(j=1;j<reads[i][0]+1;j++)
- System_printf("%d",reads[i][j]);
- System_printf("\n");
- }
- //Task_sleep(10);
- System_printf("exit taskFxn(),Counting...%d\n",sum);
- }
- /*
- * ======== main ========
- */
- Int main()
- {
- Task_Handle task;
- Error_Block eb;
- System_printf("enter main()\n");
- Error_init(&eb);
- task = Task_create(taskFxn, NULL, &eb);
- if (task == NULL) {
- System_printf("Task_create() failed!\n");
- BIOS_exit(0);
- }
- BIOS_start(); /* does not return */
- System_printf("This line should not be in the buffer!\n");
- return(0);
- }
Step1: spliting函式用來將main函式中初始化的1000個Base Pair做打散的動作,將會產生20條Reads,長度介於50~99之間
Step2: counting函式用來將每個Reads中每Shfit一個Base Pair就產生一組4個Base Pair長度的k-mers,可想像是一個長度為4的Window每次Shift的一個單元,之後對該k-mers做Counting,有再出現過這個k-mers就將該index的hash function+1,index決定方式為4進制4個bit,即4^3,4^2,4^1,4^0,共256個entry
Step3: bloom_set函式用來將hash function中,超過threshold的index都標記為1,因為本Demo只有產生1個hash function,所以只要為1,AND運算結果判定就是為1
Step4: 最後在corrcetion函式中,跟每個k-mers所對應的bloom filter index做查詢,若值為0,則進行更正,從最左邊Base Pair開始查詢,A C T G 是否在hash function中=1,如果為1則將這個Base Pair更正為該A C T G其中之一,然後Shift下一個Base Pair為首繼續比對
Step5: 將所有過程和結果,做輸出,包含亂數產生的20條Reads,Counting結果,哪些被更正過的index,和經過更正步驟的20條Reads
8. 同樣設定好app.cfg檔案的參數,以防止系統資源不足
- BIOS.heapSize = 0xFFFF;
- SysMin.bufSize = 51200;
9. 將專案工程編譯,並執行Debug session,創龍文件已詳述步驟,這裡不贅述
10. 和BLAST類似,打開ROV視窗,我們來觀看輸出結果,對核心開啟執行,數秒鐘後按下暫停,觀看SysMin的Output Buffer
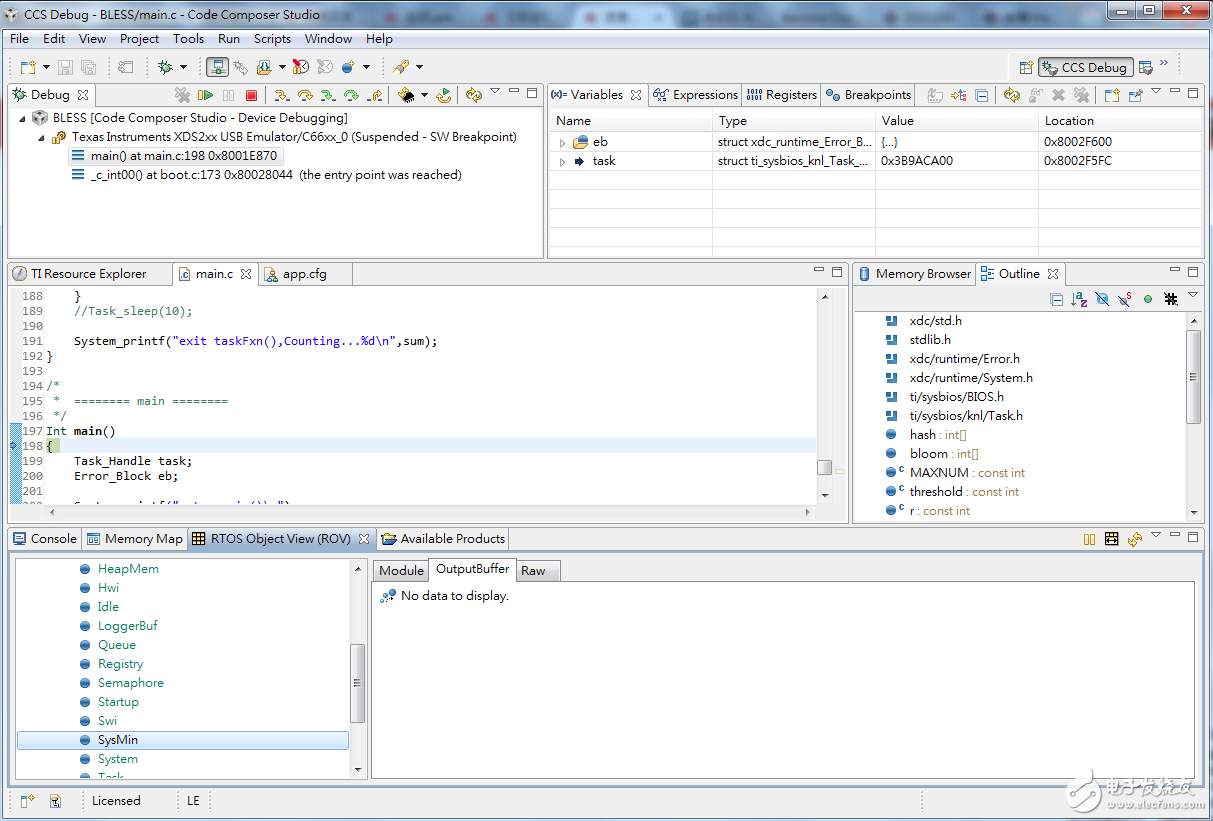
執行前
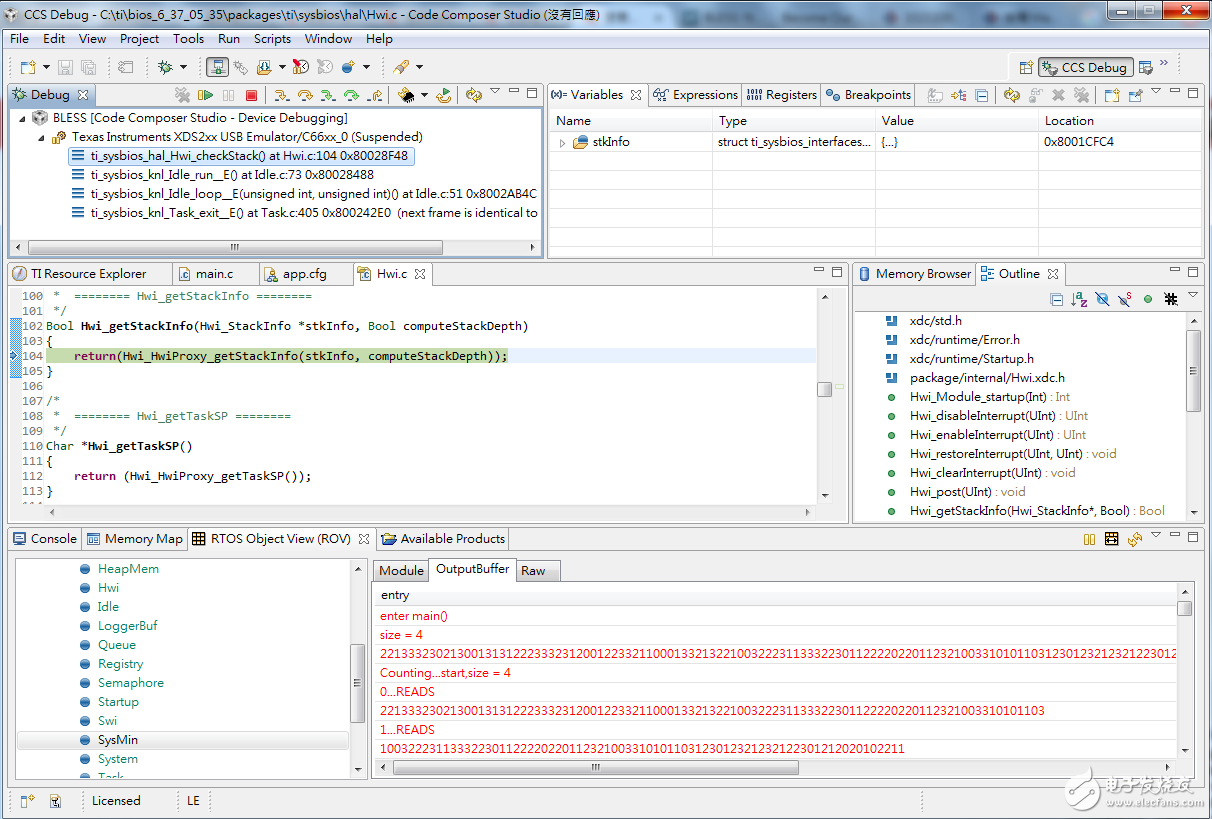
執行後
11. 按一下右上方的放大視窗,來觀看整個輸出結果
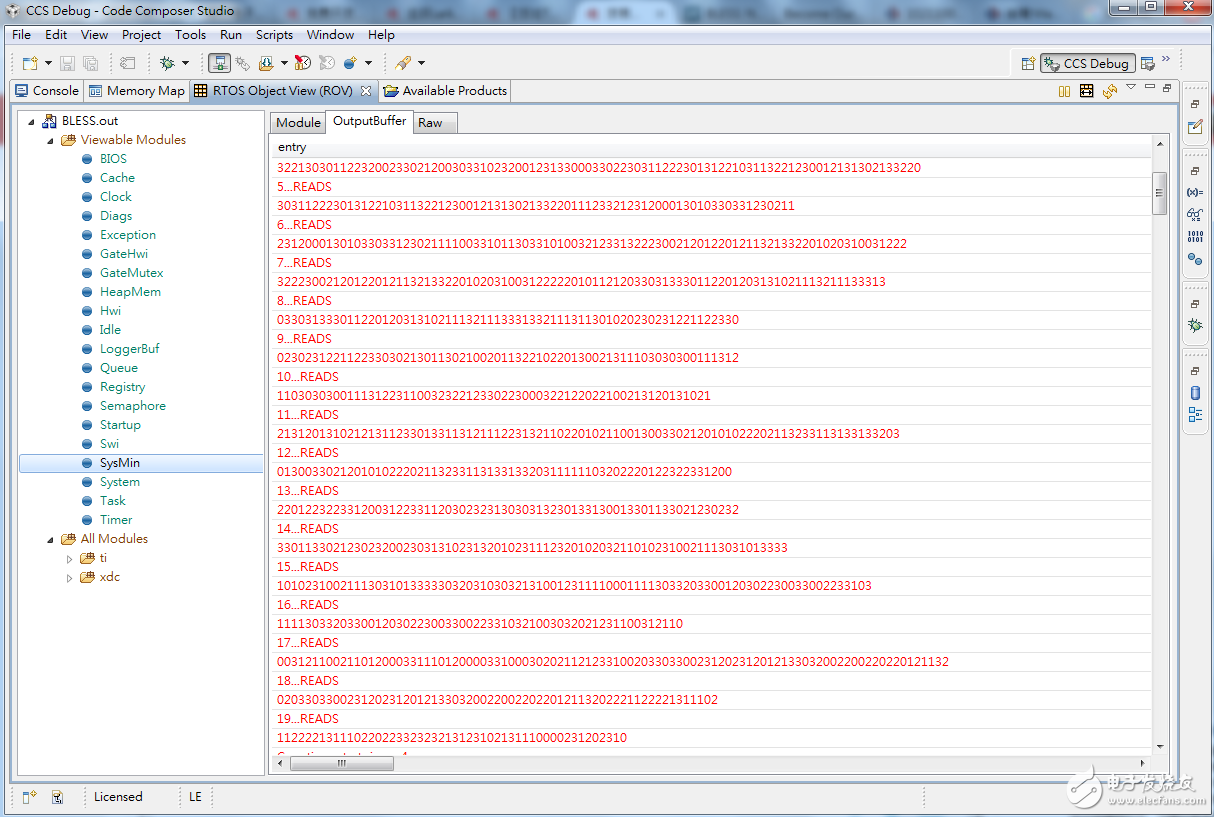
圖中為更正前,剛打散的20條Reads(0~19)

圖中為更正後的20條Reads
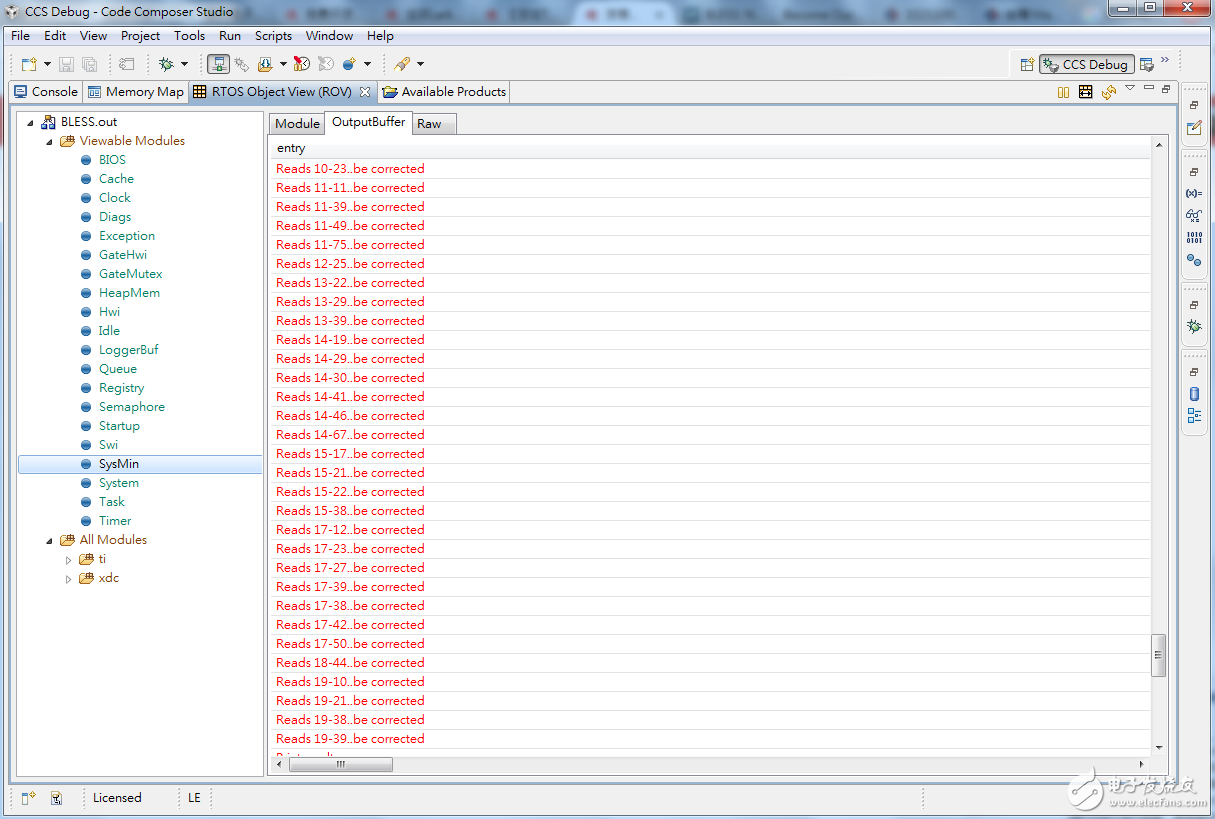
也輸出了哪個Reads之哪個Index的Base Pair被更正
12. 我們來驗證一下,選一個Reads來驗證即可,標號第19組的Reads
- 更正前:11222213111022022332323213123102131110000231202310
- 更正後:11222213101022022332023213123102131111100231202310
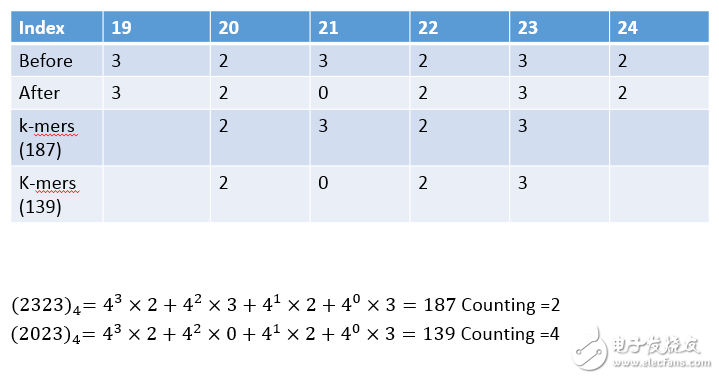
算法如圖,因為第187組的k-mers的Counting值未大於等於threshold = 3,故被認定為Weak,而更正過來
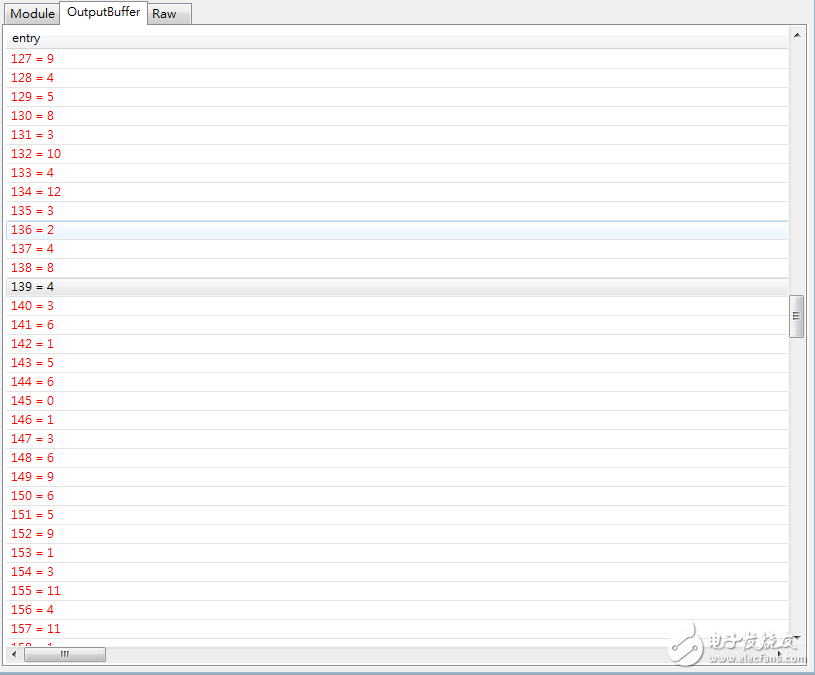
第139組的Counting值=4
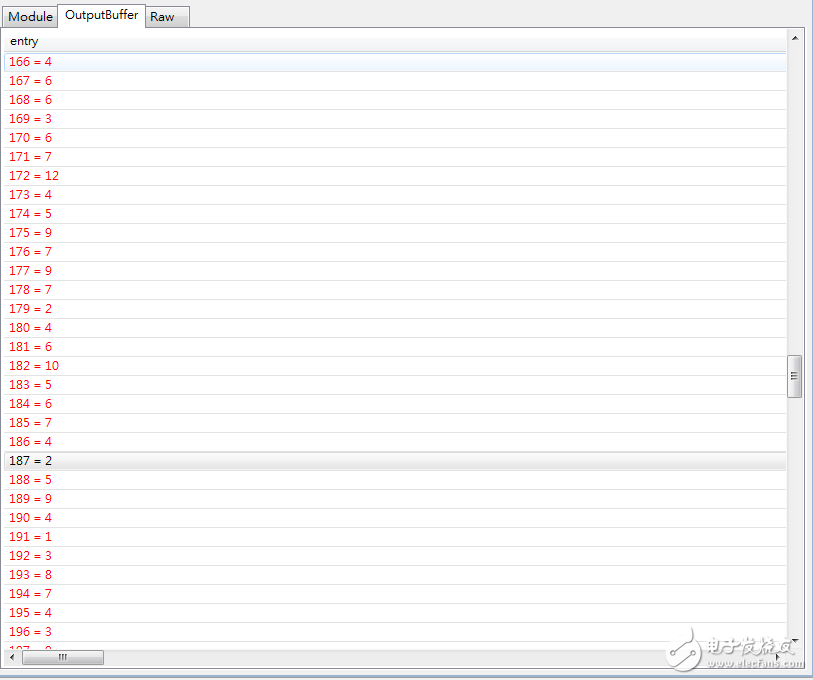
第187組的Counting值=2
完成了驗證
小結
本篇利用BLESS演算法來實際Demo一個較為複雜的應用,透過推廣和衍生,就可以用大數據的DNA資料更正,將最有可能的DNA序列產生出來,並給下一階段的Alignment工具來進行重組,產生較為正確的DNA定序,本兩篇演算法為實際應用在DSP和SYS/BIOS的案例,完整的官方原始碼更為複雜,但結果也更為精確,本Demo只是簡易反映其演算法核心邏輯,供小伙伴們參考