PMC联合Mellanox推动NVMe over RDMA及P2P的数据传输
加快数据传输并将CPU及DDR总线的使用效率推到极致是一个好的数据中心架构的评估标准。日前,PMC将其NVRAM技术与高速网卡公司Mellanox联合,共同展示了NVMe over RDMA 以及P2P的高速传输实例,有效将CPU以及DDR总线资源解放出来,并显著地提升了数据传输速度。此次联合演示包含两部分,首先展示了如何将NVMe和RDMA组合起来,在远端大规模提供低延迟、高性能、基于块的NVM访问。第二部分的演示则将Mellanox的RDMA对端发起操作与PMC的Flashtec NVRAM加速卡集成在一起,将内存映射的I/O(MMIO)作为一个RDMA目标,以实现远端大规模的持久性内存访问。下面将逐一作详细介绍:
NVM Express over RDMA
NVMe over RDMA (NoR) 展示出将NVMe协议延展到RDMA之上的潜在可能。该项演示中共采用了两台电脑,一台作为客户端,另一台则作为服务器--其中配备Mellanox ConnectX-3 Pro NIC,且通过RoCEv2相连。演示中所采用的NVMe设备即为性能极高而延迟极低的PMC Flashtec NVRAM 加速卡。下图为该演示的框图。
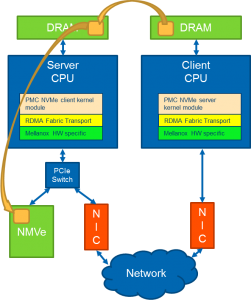
此演示显示出,利用RDMA来传送NVMe命令及数据结果带来了微乎其微的额外延迟,且不影响吞吐量。
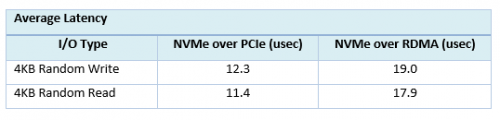
对比本地NVMe设备与远端NVMe设备的平均延迟,如下表所示,NoR方案中延迟增加低于10微妙。
而另外这组数据则对比了本地NVMe设备与远端NVMe设备吞吐量的测试结果。从下表中可以看出,NoR方案中吞吐量并无减少。

RDMA与PCIe设备之间的点到点传输
此项演示中,通过在标准 RDMA之上增加服务器CPU和DRAM的分流,采用对端发起的方式来将远端客户端与一台服务器的NVRAM/NVMe设备直连。我们将Mellanox提供的RoCEv2-capable ConnectX-3 Pro RDMA NIC与PMC的Flashtec NVRAM加速卡组合在一起,实现NIC和NVRAM之间的对端发起操作。对端发起操作可以实现远端客户对NVRAM加速卡的直接访问,相比传统的RDMA流程,可降低延迟,且有效地释放CPU和DRAM资源。
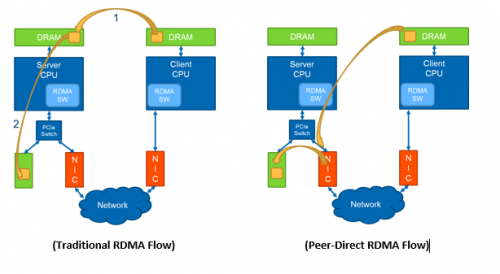
同样,该演示采用的两台电脑,一台作为客户端,另一台则作为服务器。利用服务器中的PCIe交换设备可以将对端发起操作的性能大大提升。
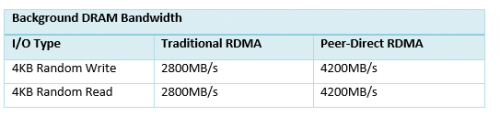
对比采用传统RDMA和对端发起的RDMA时服务器上可用的后台DRAM带宽,用perftest得出的数据如下:
下表则对采用传统RDMA和对端发起的RDMA时的平均延迟作出了比较,结果得自于RDMA mode of fio:

RDMA以及NVMe两项技术均处于蓬勃上升的阶段,RDMA能提供远距离、大规模的低延迟及高效率的数据移动,而NVMe则能提供对SSD的低延迟访问。将两项技术相结合能实现非凡的性能。
NVMe over RDMA PMC Mellanox P2P 相关文章:
- 配置PIX Failover-----配置实例(03-02)
- 配置PIX Failover----系统需求(03-02)
- 配置PIX Failover------基于LAN的Failover(03-02)
- 配置PIX Failover------验证Failover配置(03-02)
- IP Over ASON:提升保护能力 快速提供业务(03-01)
- PMC-Sierra推出高容量单芯片光纤接入汇聚方案 (02-19)