基于可复用构件思想的ETL架构设计
库项目之间平稳的移植ETL,在此设计了层间接口构件。从抽象层面上为各数据仓库项目提供一个相同的ETL处理框架,为ETL处理过程各层次的各种功能构件提供接口,实现构件具体处理过程对架构的透明化,为系统功能扩展留下了余地。
(3)KPI(关键绩效指标)自动测试构件。测试无疑是保证系统质量的一个重要方法,ETL也不例外,但是,ETL过程测试和一般的软件测试在测试过程、测试方法、*价标准等方面都有比较大的不同,它是一个非常繁琐、工作量巨大、有一定规律的过程。
从抽象层面上看,一类相似或相近的数据仓库项目每个KPI(关键绩效指标)的维度组合是相对固定的,测试标准和过程是一致的,所以,在ETL架构中,专门提供了KPI自动测试类构件,为每类KPI提供一个自动测试构件,其基本处理逻辑如图2所示。
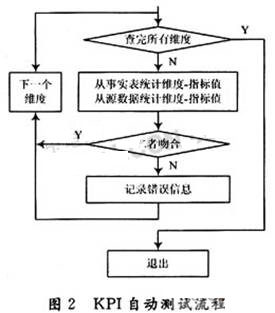
该类构件能够快速发现ETL架构中集成层和转换层中相关构件数据处理过程中隐藏的问题,从而降低ETL过程测试的难度和工作量,大幅度提高ETL架构的效率和质量。
2银联统计分析系统ETL构件识别与架构设计
为了说明基于可重用构建思想的ETL架构的有效性,下面介绍该架构在多家银联统计分析系统中的实际应用。
2.1 银联统计分析系统的介绍
银联统计分析系统是建立在数据仓库基础上的,为银联各分公司领导提供决策辅助信息的系统。其目的是为了更深入应用银联积累的大量跨行交易数据,是为了促进分公司、银行、金融监管机构和行业客户对业务进行全面、及时、准确的分析和定位,及时了解业务发展动态和预测,及时解决业务发展中存在的问题。
银联在全国有37家省级分公司。各分公司所关心的数据内容,关注的KPI体系,KPI的*价标准都是一致的。但是,各分公司由于当地经济发展水平不同,*应用深度不同,导致各分公司业务种类差异很大,即使是同一种业务,其成熟程度、规范程度差异也很大,体现在数据上就是数据源的种类不一致,即使是相同的业务数据源,在数据结构、业务判断规则、数据表现形式方面也有很大差异性。
现上采用自己开发的拥有自动知识产权决策支持系统产品:数据挖掘商业应用平台(Compass)。该平台包括智能流程管理子系统、报表专家子系统、多维分析子系统、数据挖掘子系统四个部分。其中智能流程子系统是一个独立的ETL开发工具,能够支持基于可复用构件思想ETL过程的实现。
2.2 银联统计分析系统ETL构件分层识别
在银联统计分析系统ETL设计阶段,依据图1所示的ETL架构和设计思想来设计和组织ETL各处理阶段可重用构件以及构件之间的接口规则:
(1)抽取层。银联统计分析系统抽取层处理的数据主要三类:业务数据、维度数据、辅助数据。业务数据主要包括全流水、二次清分数据、公共支付、固网支付、网上支付等业务交易数据;维度数据主要包括商户信息、机构信息、终端信息、地区信息等;辅助数据主要是卡bin信息、发卡信息等。
银联统计分析系统这个层面的数据除了全流水数据外,其他的内容在各个分公司表现形式、处理规则差异很大,封装成构件的价值不大,所以这个层面可以识别的构件只有全流水抽取。
(2)集成转换层。鉴于各分公司统计分析系统所关心的数据内容,关注的KPI体系,关注的维度数据(商户、机构、终端)信息相似度很高,所以这个层面可以识别的构件比较多,主要有两大类:流水数据集成转换构件;维度类数据集成转换构件,具体包括商户、机构、终端、商户类别、地区信息的集成转换构件。
辅助数据因为类型多样,差异比较大,可重用价值不高,所以不对其识别构件。
(3)特殊处理层。银联统计分析系统的特殊处理层的构件不再按照数据类别识别,而是根据每个指标的使用频率、涉及数据记录数的多少识别三类构件:交易指标类构件、调账指标类构件、维度统计指标类构件,分别负责交易类指标、调账类指标、商户和终端发展情况的统计。
(4)基础服务层。各分公司银联统计分析系统对元数据管理要求基本一致且没有特殊要求,银联统计分析系统将其识别为元数据管理构件。
考虑到银联统计分析系统处理的数据对象基本一致,差异主要体现在数据的表现形式和处理规则上,加上ETL过程构件之间传递数据量很大,这里选用数据池的形式而不采用函数调用的形式来定义构件接口。例如,所有分公司对商户关注的信息都是一样的,但是每个分公司提供的商户信息的表现形式却各不相同,抽取层接口数据池通过约定抽取层商户信息抽取过程生成内容和格式,为集成转换层商户信息集成转换构件提供一个稳定的数据源,使其不必关心用户提供的数据源是什么形式。
考虑到银联统