最小化ARM Cortex-M CPU功耗的方法与技巧
1理解Thumb-2
首先,让我们从一个看起来并不明显的起点开始讨论节能技术-指令集。所有Cortex-M CPU都使用Thumb-2指令集,它融合了32位ARM指令集和16位Thumb指令集,并且为原始性能和整体代码大小提供了灵活的解决方案。在Cortex-M内核上一个典型的Thumb-2应用程序与完全采用ARM指令完成的相同功能应用程序相比,代码大小减小到25%之内,而执行效率达到90%(当针对运行时间进行优化后)。
Thumb-2中包含了许多功能强大的指令,能够有效减少基础运算所需的时钟周期数。减少时钟周期数意味着现在你能够以更少的CPU功耗完成手头的工作。例如,假设要完成一个16位乘法运算(如图1所示)。在一个8位8051内核的MCU上执行这个运算将需要48个时钟周期,并占用48字节的Flash存储空间。使用一个16位内核的MCU(例如C166)执行相同的运算需要8个时钟周期,并占用8字节的Flash存储空间。相比之下,在使用Thumb-2指令集的Cortex-M3内核中完成相同运算仅仅需要1个时钟周期,并占用2字节的Flash存储空间。Cortex-M3内核能够通过使用更少时钟周期完成相同任务,节省了能耗;同时也能够通过占用极少的Flash存储空间,减少Flash存储器访问次数,实现最终能耗节省的目标(除此之外,更小的应用代码也使得系统可以选择更小的Flash存储器,进一步降低整体系统功耗)。

图1 时钟周期数对比
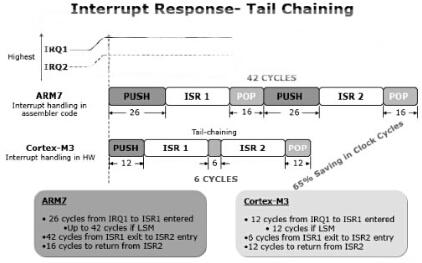
图2 ARM7和Cortex-M3的中断响应
2中断控制器节能技术
Cortex-M架构中的中断控制器(Nested Vectored Interrupt Controller or NVIC)在降低CPU功耗方面也起着关键作用。以前的ARM7-TDMI需要"多达"42个时钟周期,Cortex-M3 NVIC从中断请求发生到执行中断处理代码仅需要12个时钟周期的转换时间,这显然提高了CPU执行效率,降低了CPU时间浪费。除了更快进入中断处理程序之外,NVIC也使得中断之间切换更加高效。
在ARM7-TDMI内核实现中,需要先花费数个时钟周期从中断处理程序返回主程序,然后再进入到下一个中断处理程序中,中断服务程序之间的"入栈和出栈(push-and-pop)"操作就要消耗多达42个时钟周期。而Cortex-M NVIC采用更有效的方法实现相同任务,被称为"末尾连锁(tail-chaining)"。这种方法使用仅需6个时钟周期处理就能得到允许,进入下一个中断服务程序的所需信息。采用末尾连锁,不需要进行完整的入栈和出栈循环,这使得管理中断过程所需的时钟周期数减少65%(如图2所示)。
3存储器节能注意事项
存储器接口和存储器加速器能够明显影响CPU功耗。代码中的分支和跳转可能会对为CPU提供指令的流水线产生刷新影响,在这种情况下CPU需要延迟几个时钟周期以等待流水线重新完成填充。在Cortex-M3或Cortex-M4内核中,CPU配备了一条3级流水线。刷新整条流水线将导致CPU延迟3个时钟周期,如果有Flash存储器等待状态发生,时间会更长,以便完成重新填充过程。这些延迟完全浪费功耗,没有任何功用。为了帮助减少延迟,Cortex-M3和M4内核包括一个被称为推测取指(Speculative Fetch)的功能,即它在流水线中对分支进行取指的同时也取指可能的分支目标。如果可能的分支目标命中,那么推测取指能够把延迟降低到1个时钟周期。虽然这个特性是有用的,但显然不够,许多Cortex-M产品供应商都增加了自己的IP以增强这个能力。
举个例子,即使在广受欢迎的ARM Cortex-M类的MCU中指令缓冲的运行方法也有不同。采用简单指令缓冲的MCU,例如来自Silicon Labs的EFM32产品,可以存储128x32(512 bytes)的目前大多数当前执行指令(通过逻辑判断请求的指令地址是否在缓冲中)。EFM32参考手册指出典型应用在这个缓冲中将有超过70%的命中率,这意味着极少的Flash存取、更快的代码执行速度和更低的整体功耗。相比之下,采用64x128位分支缓冲器的ARM MCU能够存储最初的几条指令(取决于16位或32位指令混合,每个分支最多为8条指令,最少为4条指令)。因此,分支缓冲实现能够在1个时钟周期内为命中缓冲的任何分支或跳转填充流水线,从而消除了任何CPU时钟周期延迟或浪费。两种缓冲技术与同类型没有缓冲特性的CPU相比,都提供了相当大的性能改善和功耗减少。
4 M0+内核探究
对功耗敏感型应用来说每个nano-watt都很重要,Cortex-M0+内核是一个极好的选择。M0+基于Von-Neumann架构(而Cortex-M3和Cortex-M4内核是Harvard结构),这意味着它具有更少的门电路数量实现更低的整体功耗,并且仅仅损失极小的性能(Cortex-M0+的0.93DMIPS/MHz对比Cortex-M3/M4的1.25DMIPS/MHz)。它也使用Thumb-2指令集的更小子集(如图3所示)。几乎所有的指令都有16位的操作码(52x16位操作码和7x32位操作码;数据操作都是32位的),这使得它可以实现一些令人感兴趣的功能选项以降低CPU功耗。
CPU ARM DAC Cortex-M 功耗 Thumb-2 相关文章:
- Nut/OS和μC/OS—II的实时调度算法比较 (04-07)
- 基于AT89C51+DSP的双CPU伺服运动控制器的研究(05-26)
- 大容量无线传输技术中高性能DSP 的启动方法(05-04)
- 双CPU在多I/O口系统中的应用(07-05)
- Windows操作系统多核CPU内核线程管理方法(01-21)
- 基于DSP和80C196双CPU构成的高速实时控制系统(01-11)