基于ARM7控制器的中英文翻译器的设计
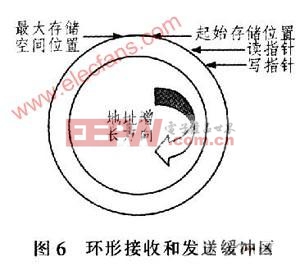
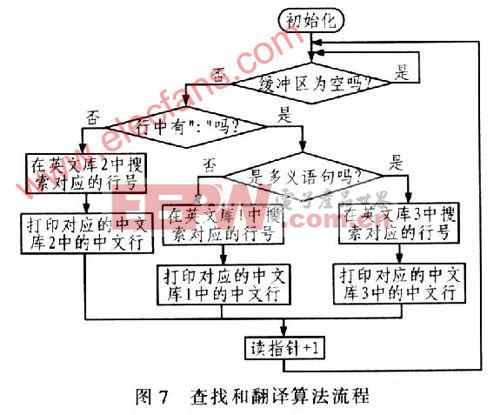
2.2 环形接收和发送缓冲区算法 设备传输的数据量很大,共有几百组数据,而每组数据又包含几十行英文字符和数字,如果采用全部接收完设备传输的数据后再查找对应的中文,找到后再依次控制打印机打印输出,则不但需要相当大的缓冲区用于存储,而且从接收数据开始到打印机输出打印要延误很长时间。因此,这里采用前后台程序方式即边接收、边查找、边打印,该方式既节省时间又节省存储空间。在系统中开一段存储空间作为接收缓冲区,如图6所示。设置2个指针:写指针和读指针,初始化时令这2个指针分别指向存储区的起始位置。接收设备数据采用UART0串口接收中断处理方式,以便不丢失设备发送的任何一个字符。在UART0每接收一行英文数据后,写指针加1,当写指针达到最大存储空间位置时,令写指针复位为起始存储位置,这样就形成一个环形缓冲区。当接收缓冲区非空,即有需要翻译的英文行数据时,读指针指向当前需要翻译的英文行数据,和写指针类似,每翻译一行数据后通过UARTl控制打印机输出打印且读指针加1,当读指针到达最大存储空间位置时,令读指针复位为起始存储位置。实验表明,设置成很少的几行接收和发送缓冲区都可以正常接收数据和打印数据。 2.3 查找和翻译算法 查找和翻译算法是在主程序中进行的,就是将接收和发送缓冲区中接收的每一行英文数据和三个英文库中的存储的英文行数据进行比较,如果一致,就返回所在当前英文库中的行号,然后根据行号再找到对应的中文库巾的数据行号即可,最后就可以控制打印机按一定格式输出打印。整个算法的流程如图7所示。 3 实验结果 图8给出了英文和中文打印效果的对比,由于数据量非常大,此处只是截取了很少的一段。可以看出中文打印输出翻译准确、格式整齐,字体大小合适。另外,由于选取了更快速的热敏打印机,从调试过程中可以明显看出中文打印的速度远远快于原来配套的英文打印速度。 本系统实现的英文转中文翻译器在软硬件方面都采取较好的方案,硬件集成度高,电路板尺寸小,软件算法简洁,编程时除了启动代码采用汇编语言外其他大部分功能代码均采用了模块化的C语言编程,所以针对其他相关的应用领域,在硬件和软件上只需作相应改动即可方便实现。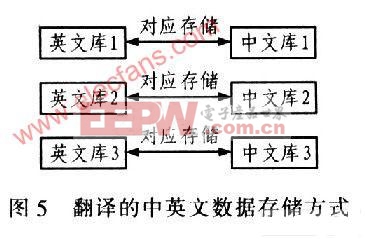

4 结论
- Windows CE 进程、线程和内存管理(11-09)
- RedHatLinux新手入门教程(5)(11-12)
- uClinux介绍(11-09)
- openwebmailV1.60安装教学(11-12)
- Linux嵌入式系统开发平台选型探讨(11-09)
- Windows CE 进程、线程和内存管理(二)(11-09)