Web文档聚类中k-means算法的改进
介绍了Web文档聚类中普遍使用的、基于分割的k-means算法,分析了k-means算法所使用的向量空间模型和基于距离的相似性度量的局限性,从而提出了一种改善向量空间模型以及相似性度量的方法。
关键词: 文档聚类 k-means算法 向量空间模型 相似性度量
Internet的快速发展使得Web上电子文档资源在几年间呈爆炸式增长,与数据库中结构化的信息相比,非结构化的Web文档信息更加丰富和繁杂。如何充分有效地利用Web上丰富的文档资源,使用户能够快速有效地找到需要的信息已经成为迫切需要解决的问题。
聚类能够在没有训练样本的条件下自动产生聚类模型。作为数据挖掘的一种重要手段,聚类在Web文档的信息挖掘中也起着非常重要的作用。文档聚类是将文档集合分成若干个簇,要求簇内文档内容的相似性尽可能大,而簇之间文档的相似性尽可能小。文档聚类可以揭示文档集合的内在结构,发现新的信息,因此广泛应用于文本挖掘与信息检索等方面。
文档聚类算法一般分为分层和分割二种,普遍采用的是基于分割的k-means算法。
k-means算法具有可伸缩性和效率极高的优点,从而被广泛地应用于大文档集的处理。针对k-means算法的缺点,许多文献提出了改进方法,但是这些改进大多以牺牲效率为代价,且只对算法的某一方面进行优化,从而使执行代价很高。
k-means算法中文档表示模型采用向量空间模型(VSM),其中的词条权重评价函数用TF*IDF表示。然而实际上这种表示方法只体现了该词条是否出现以及出现多少次的信息,而没有考虑对于该词条在文档中出现的位置及不同位置对文档内容的决定程度不同这一情况。另一方面,k-means算法使用基于距离的相似性度量,然而文档的特征向量一般超过万维,有时可达到数十万维,这种高维度使得这种度量方法不再有效。针对以上问题,本文提出相应的解决方法,即改进的k-means算法。实验表明改进后的k-means算法不仅保留了原算法效率高的优点,而且聚类的平均准确度有了较大提高。
1k-means算法简介
k-means算法是一种基于分割的聚类算法。基于分割的聚类算法可以简单描述为:对一个对象集合构造一个划分,形成k个簇,使得评价函数最优。不同的评价函数将产生不同的聚类结果,k-means算法通常使用的评价函数为:

k-means算法的具体过程如下:
(1)选取k个对象作为初始的聚类种子;
(2)根据聚类种子的值,将每个对象重新赋给最相似的簇;
(3)重新计算每个簇中对象的平均值,用此平均值作为新的聚类种子;
(4)重复执行(2)、(3)步,直到各个簇不再发生变化。
k-means算法的复杂度为:O(nkt)。其中:n为对象个数,k为聚类数,t为迭代次数。通常k、t n,所以k-means算法具有很高的效率。同时k-means算法具有较强的可伸缩性,除了生成k个聚类外,还生成每个聚类的中心,因此被广泛应用。
2 k-means算法的分析及其改进
2.1 权重评价函数的改进
k-means算法采用向量空间模型(VSM)将Web文档分解为由词条特征构成的向量,利用特征词条及其权重表示文档信息。向量d=(ω1,ω2,ω3,∧,ωm)表示文档d的特征词条及相应权重。其中:m为文档集中词条的数目,ωi(i=1,∧,m)表示词条ti在文档d中的权重。特征权重ωi的计算通常采用经典的TF*IDF算法,并进行规格化处理:
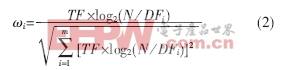
其中:TF表示该词条ti在文档d中的频数,DFi表示文档集中包含词条ti的文档数,N表示文档集中的文档数。从公式(2)可以看出,这种特征权重的计算方法是把文档当做一组无序词条,词条特征权重只是体现了该词条是否出现以及出现次数多少的信息,而对于词条在文档中的不同位置对文档内容的决定程度不同这一问题却未加考虑。
对于Web文档而言,由于XML(可扩展标识语言)已经成为Web上新一代数据内容描述标准,因此Web上的文档聚类应体现XML文档的特性。XML文档中的基本单位是元素(element)。元素由起始标签、元素的文本内容和结束标签组成。它的语法格式为:
标签> 文本内容
基于XML的Web文档中,用户把要描述的数据对象放在起始标签和结束标签之间,无论文本的内容多长或者多么复杂,XML都可以通过元素的嵌套进行处理。不同标签下,同一个词条也可能有不同含义。由此可见,XML文档中不同位置的词条对文档内容的决定程度会有很大的不同。
通常,一个文档的标题、摘要、关键词以及段首和段尾出现的词条对整个文档内容有很大的决定作用。在XML文档中,通过标签可以得出词条对文档内容的决定程度,但很难对这种决定程度进行准确的定义。因此,本文利用模糊集理论,根据XML文档特性计算词条从属关系系数,并且将其量化为介于0和1之间的隶属度,加入到原有权重评价函数,从而表明XML文档
- 非规则LDPC码译码改进算法及其DSP实现(10-13)
- 总线桥在污水厂的改进应用(12-16)
- 一个改进型的4*4矩阵键盘扫描(11-30)
- 袋式除尘器PLC控制系统改进(03-04)
- 热电厂DCS控制系统的应用与改进(11-08)
- 单片机的干扰分析及MCU的改进(07-31)