嵌入式多媒体应用的多核编程框架
台执行传输操作,而不会因为数据项请求使处理器核暂停工作。
由于每个DMA控制器上都有两组MDMA通道,因此系统可以将MDMA通道在处理器核上均匀分配,从而可以对称地进行并行处理。
对于数据存取模式粒度较小的应用,可以轻松地利用对L1和L2存储器的快速访问。也可以直接将独立的数据块从外设接口传送到L1或L2存储器,而不需要访问慢速的外部存储器,这样可以节省宝贵的外存储器带宽和MDMA资源,并缩短数据传输时间。
对于数据存取模式粒度较大的应用,存储器可能成为瓶颈,因为较小的L1和L2存储器级不足以容纳大量的数据帧。然而,大量数据帧之间虽然存在数据关联性,但这种关联通常也仅存在于跨数据帧的较小数据块上。如果能将所有关联的数据帧存放在一个较大的存储空间(外部存储器)中,就可以将每一帧中的独立数据块相继送入空闲的处理器核进行处理。如果这些独立的数据块比数据帧小得多,符合L1或L2存储器的容量,就可以减少存储器存取延迟,高效地处理数据。
虽然L2和外部存储器都有独立的总线连接,但两个处理器核仍共享这些存储器接口总线。因此,应当尽量避免两个处理器核同时对同一级别的存储器进行存取操作,以免因总线冲突而停止工作。为了减少总线冲突状况,框架应考虑代码和数据对象的映射,让一个处理器核主要访问L2存储器核,而另一处理器核则主要访问外部存储器。在这种情况下,虽然处理器核完成多数外部存储器访问会出现较大的访问延迟,但总的访问延迟仍然小于总线冲突的代价。
框架把所有输入外设接口分配给一个处理器核,把所有输出外设接口分配给另一处理器核。框架利用视频输入/输出接口,例如PPI(并行外设接口)来输入和输出视频帧。BF561架构有两个PPI接口。
如果中断处理时间比数据流的处理时间要短,则可将所有的外设接口分配给一个处理器核以便于编程,较短的中断处理时间不会影响两个处理器核的负荷平衡。
软件框架的建议模型
基于数据存取模式的粒度,可以定义四种软件框架:行处理(空间域)、宏块处理(空间域)、帧处理(时间域)以及GOP处理(时间域)。如果某个应用程序的数据存取模式适于这四种模型中的任何一种,就可以采用相应的框架。如果一个数据流有两种或更多的处理算法,还可以将多种框架结合起来,实现非对称的并行处理。
在行处理模式中,关联性只存在于行级,也就是说,只存在于相邻像素之间。每行数据形成一个数据块,各处理器核都可以独立处理。
图3显示了行处理框架的数据流模型。处理器核A处理视频输入,处理器核B处理视频输出。核A和B之间的数据由独立的MDMA通道组进行管理。L1存储器使用多个缓神器,可以避免处理器核与外设DMA访问总线的冲突。两个处理器核之间每行数据的同步通过计数信号量实现。在这种框架中,采用单处理器核方式将数据直接存入L1存储器也具有优势,可以节省外部存储器带宽和DMA资源。这种框架的应用实例包括色彩变换、直方图均衡化、滤波和采样。
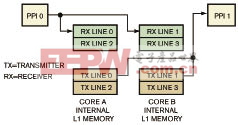
图3 行处理框架的数据流模型。处理器核A处理视频输入,处理器核B处理视频输出。
图4显示了宏块数据访问模式的数据流模型,可以在两个处理器核之间交替传送宏块。L2存储器具有多个片段缓冲器,独立的MDMA通道将宏块从每个处理器核的L2存储器传输到L1存储器。L1存储器也有多个缓神器,用以避免DMA与处理器核访问总线的冲突。与行处理框架类似,该框架中处理器核A控制输入视频接口,处理器核B控制输出接口,计数信号量实现两个处理器核之间的同步。这种框架的应用实例包括边缘检测、JPEG/MPEG编码/解码算法和卷积编码。
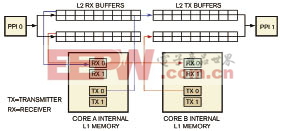
图4 在双核宏块数据访问模式中,L2存储器具有多个片段缓冲器,独立的MDMA通道将宏块从每个处理器核的L2存储器传输到L1存储器。
在帧级处理模式中,外部存储器存储关联帧。根据数据帧(宏块或行)之间的关联性粒度,系统将数据帧的子块传送到L1或L2存储器。图5显示了帧级处理框架的数据流模型。在这种情况下,假定某个宏块在多个帧之间存在关联,则系统将数据帧的宏块传送至L1存储器。与其它框架类似,该框架中处理器核A控制输入视频接口,处理器核B控制输出接口,通过计数信号量实现两个处理器核之间的同步。这种框架的应用实例包括运动检测算法。
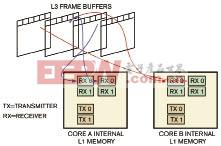
图5 在帧级处理流程中,外部的存储器存储独立帧
在GOP级处理模式中,每个处理器核处理多个相继的数据郑帧级处理框架与GOP级处理框架之间的区别在于,前者是在帧内完成空间划分,后者则通过时间划分(帧序列)实现并行处理。对于GOP数据访问模式,关联性存在于一组数据帧内部,两组帧之间数据不存在关联性。因
- CAN通信卡的Linux设备驱动程序设计实现(04-25)
- 基于嵌入式的多媒体应用的多处理器核软件设计框架(04-08)
- 基于RF5框架的视频处理系统的研究(09-22)
- USB驱动程序框架搭建(12-15)
- 3.4.2内核下的I2C驱动框架解析(11-21)
- Android 框架简介(09-12)