基于单片机的智能终端中汉字显示的处理
。从中找到需要下载的汉字,根据这些汉字的内码,从系统字库中得到汉字的字模,经过字模转化(在后面介绍),然后保存在字库下载文件中。
为了保证下传的汉字字模不会重复,在数据库中创建一个“汉字表”来存储每个经过筛选的汉字的信息。表中有两个字段,一个用来存储汉字的内码,另一个用来存储该汉字字模在字库下载文件中的偏移地址(终端程序可以通过某个汉字在字库下载文件中的偏移地址来唯一确定该汉字的字模存放位置)。每得到一个汉字的内码时,先到汉字表中查询表中是否已经包含了该汉字,再决定是否进行提取和下载处理。
然后,处理程序逐个遍历菜谱表、桌位表等数据表项来生成菜谱下载文件、桌位下载文件等。这些下载文件中涉及到的汉字,以该汉字的字模在终端下载字库文件中的偏移地址来标识。这样每个汉字可以用两个字节唯一标识。
最后,处理程序将以上这些下载文件通过串口下传给终端,终端将下载文件的内容保存在数据存储区中,并记录存放字库下载文件数据区的起始地址,记为A。当需要显示汉字时,终端程序先得到该汉字在下载文件中的偏移地址,记为B,然后计算出该汉字字模的存放位置(A+B),从此位置开始连续读取32字节,就得到了该汉字字模数据,之后通过驱动液晶屏将汉字显示出来。
3.需要注意的关键技术
3.1 汉字字模的提取
先说明一下在中文信息交换标准GB2312中涉及到的三个概念:区位码、国标码、内码。
中文国标字符集是一个94×94的矩阵,其中每一个汉字(包括数字、英文字母和标点符号)都是二维矩阵中的某个元素。这样,每一个汉字都可以用一个二元组来表示(x,y)。其中,x是该字所在的行号,y为列号。
GB2312在此基础上对矩阵进行划分,分为94个区,每区94位,x定义了该字所在的行号,y表示该字所在的位号,x和y均以二进制或十六进制表示。这就是“区位码”,例如:“啊”字的区位码为(0x10,0x01),表示位于16区第一位。于是汉字库中的字模存放位置(相对于字库文件头的偏移地址)可以由区位码计算得到:偏移地址=区码×94+位码。那么“啊”字的字模相对于字库文件头的偏移地址等于16×94+1=1505(十进制表示)。
但是许多低位数字已被其它领域所占用,比如:0x06表示通信确认回答标志。为了不与已经存在的信码相混淆,GB2312在每个区位码上加上0x20,这样形成的码叫国标码。例如:“啊”字的国标码为(0x30,0x21)。
由于通用的ASCII字符的最高位为0,为了在计算机内部和之间传输汉字时可以和ASCII码区别开来,将表示汉字的两个字节的最高位都置1。这样,相当于在国标码基础上高低字节同时加了0x80,这就是上面提到的内码。比如:“啊”字的内码为(0xB0,0xA1)。在计算机内部,用内码来唯一标识一个汉字。在程序中,通过调用系统函数取得某个汉字的ASCII字符表示,也就得到了这个汉字的内码。
在明白了内码和区位码之间的关系后,我们可以根据某个汉字的内码计算得到该汉字的区位码;再通过区位码计算得到该汉字的字模在汉字库表中的偏移地址;从此地址开始的连续32个字节就是该汉字的字模信息。
3.2 字模转换
图1中所示的汉字显示与字模存放的关系是PC机中的字模存储格式。而在单片机系统中,选择不同的液晶驱动器要求有不同的字模存储方式。比如我们在实际应用中,使用的是清华蓬远科贸公司的HD61202液晶驱动器。图5 指示了HD61202液晶驱动器所要求的字模存放与汉字显示的关系。图中标明了标出了第1、第2个字节和第31、第32个字节的存放位置。
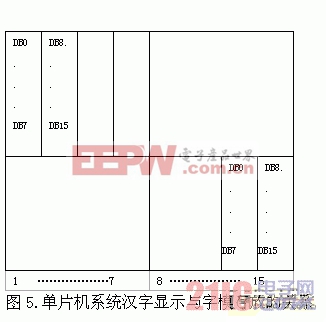
造成汉字显示与字模存放有这样关系是因为不同的液晶驱动器有不同的扫描显示方式。所以,为了能够将汉字正确的显示出来,针对不同的液晶驱动要做相应的字模转化。字模转化可以自编一个转化函数来实现,在写入终端字库下载文件前将32个字节的字模按位转化为需要的格式,再按字节顺序存入下载文件。
经过转化之后,“大”字的字模(32个字节)变成:(32,32,32,32,32,32,160,127,0,64,64,32,16,12,3,0,160,32,32,32,32,48,32,0,1,6,8,16,32,96,32,0), 这就是存放在终端下载字库中的字模格式。
参考资料:
1:《单片机应用系统设计》 何立民 北京航空航天大学出版社 1994
2:《汉字编码标准与识别》
- 蓄电池化成控制系统中显示功能的实现(11-05)
- 基于DSP实现的LCD液晶屏显示技术(06-04)
- 军事指挥系统中VxWorks下汉字显示技术(07-16)
- DSP在LED显示中的应用(08-21)
- 基于Android系统的影音播放器开发(03-25)
- 基于MC9S12XS128的单片机开发板的设计(08-13)