基于32位CPU中Load Aligner模块数据通道的设计与实现
在CPU中,访问寄存器比访问主存速度要快。所以为了减少访问存储器而花的时间或延迟,MIPS4KC处理器采用了Load/Store设计。在CPU芯片上有许多寄存器,所有的操作都由存储在寄存器里的操作数来完成,而主存只有通过Load和Store指令来访问。这样做不仅可以减少访问主存的次数,有利于降低对主存储器容量的要求,而且可以精简指令集,有利于编译人员优化寄存器分配。Load Aligner就是数据存储器(DCACHE)和数据通道之间的接口。所以设计出性能优良的Load Aligner对提高CPU的整体性能是非常重要的。本文介绍了在一款32位CPU中Load Aligner模块的设计与实现,其中主要是数据通道部分的设计和实现。
设计目标
本设计中,Load Aligner模块要实现的指令有LB、LBU、LH、LHU、LW、LWL、LWR。CPU通过这些指令把从数据存储器中取出来的数据重新排序,然后放进寄存器堆RF中,进入CPU的数据通道。表1是对这些指令的介绍。

如果把从DCACHE中取出的一个32位的字表示成4字节:A、B、C、D,如表2所示。
31-24/ 23-16/ 15-18/ 7-0
A / B / C / D
那么经过上述指令操作后,这个字被重新排列的结果(即Load Aligner模块的输出,也用4字节来表示)见表3。

表3中,s表示符号扩展,*表示这个字节上的寄存器中的数保持不变。不过在Load Aligner模块,先将这些字节置0,在寄存器堆模块再控制这些字节是否直接写进寄存器。
以上是Load Aligner模块要实现的指令目标,另外由于此模块是CPU关键路径的一部分,因此数据通道部分最长时延不能超过0.7ns。
逻辑设计
分析比较经过上述指令后Load Aligner模块的输入输出变化可以看出:输入字的每一字节经过Load Aligner模块后可以在输出字的任意字节位置上。换言之,输出字的每一字节都可以有A、B、C、D四种情况。所以需要一个8位的控制信号Bit7:0>来控制四个四选一的数据选择器,称为字节组合模块,来获得所需要的字节组合。不过,经过这个字节组合模块选出来的4字节并不全是所需要的,还需要去掉冗余的字节或者进行符号扩展。因此需要有能够产生符号扩展或者0扩展的模块称为符号产生模块,然后把它的输出和一个4位的控制信号Mask3:0>一起控制一组二选一数据选择器,称为输出模块,来获得最后的排序结果。逻辑实现流程图见图1。
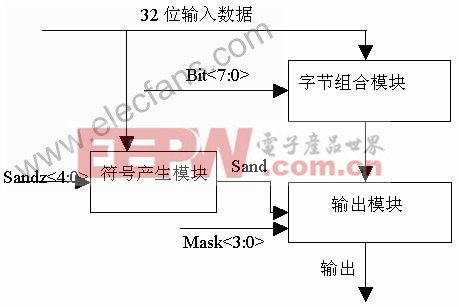
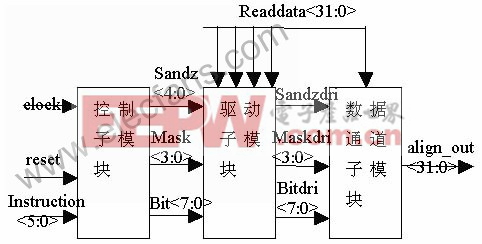
以上是Load Aligner模块数据通道部分的设计。它还需要有控制模块来产生上述控制信号,此外由于任何一个控制信号都要驱动数据通道子模块中的32个cell,所以还要有一个驱动模块来使控制信号有足够的驱动能力。由以上分析,整个Load Aligner模块的框图如图2所示。其中,控制模块采用自动布局布线生成,而驱动模块和数据通道模块均采用全定制设计。
功能验证
对此模块的RTL代码和所设计的电路分别进行了功能验证。设从DCACHE取出的32位数据用十六进制表示为AABBCCDD,对表3中的所有指令进行测试。图3所示的波形图就是依次测试指令LW、LH00、LHU00、LH10、LHU10、LB00、LBU00、LB01、LBU01、LB10等的结果。可以看出,结果与表3完全吻合。说明所设计的电路满足设计目标,可以实现所要求的所有指令。

电路仿真
根据图1可以看出,从符号选择信号Sandz4:0>到输出的路径为最长路径,我们选取这条路径进行仿真,并考虑在0.18μm时线电阻电容对时延的影响,用Hspice确定了所需器件的尺寸。仿真结果如图4所示。上升时时延为0.52ns,下降时时延为0.47ns,均满足小于0.7ns 的要求。

结论
在CPU中,Load Aligner模块是DCACHE和数据通道之间的接口。从DCACHE中取出的数据只有通过Load Aligner模块重新排序,才能进入CPU的数据通道。在设计中应用了自上而下的设计方法,所设计的电路实现了所有的指令,在时延上也达到了设计目标。
数据 通道 设计 实现 模块 Aligner 32位 CPU Load 基于 相关文章:
- Windows CE 进程、线程和内存管理(11-09)
- 基于虚拟仪器的特性测试参数数据库的设计(06-24)
- 一种基FPGA和DSP的高性能PCI数据采集处理卡设计(08-26)
- 嵌入式数据库在Java中的应用(03-03)
- 基于LabVIEW的USB实时数据采集处理系统的实现(03-26)
- 基于DSP和USB的高速数据采集与处理系统设计(05-01)