基于虚拟化与分布式技术的存储系统
摘要:介绍了一套基于云计算(cloud computing)技术的数据应用平台系统设计方案。该系统由多组服务器集群组成,可提供数据存储、备份和并行运算服务。并可采用虚拟化应用端与分布式(Hadoop)技术相结合的方式为用户提供高容量和异构应用存储系统,以便结合iSCSI协议在硬件层获得更灵活的部署。
关键词:虚拟化;数据处理;分布式存储;云计算
0 引言
通过FreeBSD系统搭建开源的Hadoop存储应用基础,依托在服务器虚拟化(VMware)的平台上进行运行,这样能够拥有更快、更稳定、更安全的硬件保障,使用iSCSI技术,尽可能降低存储部署成本。本系统利用VMware虚拟化平台将服务器硬件存储资源进行整合,通过建立Lun将服务器的磁盘阵列进行划分,组成多个磁盘逻辑,然后通过在Lun上安装FreeBSD操作系统及搭建iSCSI服务器端,使得存储硬件资源能够灵活地应用在Hadoop系统中。Hadoop将部署在虚拟化硬件平台上构成一个分布式的文件系统,通过WebDAV协议建立与客户端服务器的应用通信。用户可以通过访问客户端服务器,将文件通过WebDAV以HTTPS方式传输到Hadoop存储集群中保存。
该平台的设计充分利用了虚拟化与分布式技术的特点,采用多层次的模块化应用将整个存储系统从硬件架构到软件应用方式都变得灵活和易扩展,同时又因为虚拟化与分布式技术本身的安全特性,系统在数据安全性上具有先天优势,从而实现数据存储服务的低成本部署。
1 系统设计原理
存储系统采用底层云存储技术与应用层iSCSI技术来为用户提供跨系统应用平台支持。其工作原理如图1所示。
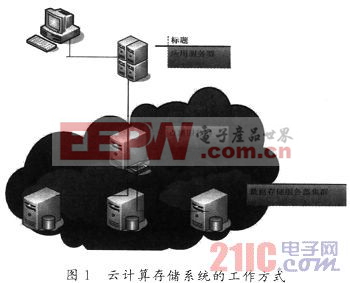
系统首先由多台数据存储服务器通过iSCSI网络构成一个庞大的数据存储服务集群,每一台数据服务器的配置是相同的。当数据达到存储池饱和状态时,可以将同样配置的服务器加入到这个存储网络中,在不改变原有系统运行状态下实现扩容。
系统采用VMware ESXi Server虚拟系统作为应用服务器集群底层系统,各应用服务器系统可在VMware虚拟系统之上建立逻辑上的关联。 VMware允许多个操作系统并行运行于一台高性能服务器之上和多个高性能服务器运行同一任务,同时通过网络对操作系统进行备份和管理,能够依据应用服务使用状况对操作系统实施迁移和复制,从而扩大网络应用处理带宽。
在VMware层上安装FreeBSD系统平台搭建Hadoop分布式存储系统,Hadoop系统能将数据同时分割成许多小块和备份,通过点播服务器(NameNode)存放于不同的数据存储服务器中。在Hadoop系统中,会有一台Master,主要负责NameNode的工作以及JobTracker的工作。Job Tracker的主要职责就是启动、跟踪和调度各个Slave的任务执行。还会有多台Slave,每一台Slave通常具有DataNode的功能并负责Task Tracker的工作。TaskTracker根据应用要求来结合本地数据执行Map任务以及Reduce任务。
在NameNode上部署WebDAV应用,实现应用服务器对存储资源的通信,从而让用户调用Hadoop上的数据。WebDAV(Web-based Distributed Authoring and Versioning)是基于HTTP 1.1的一个通信协议。它为HTTP 1.1添加了一些扩展(就是在GET、POST、HEAD等几个HTTP标准方法以外添加了一些新的方法),使得应用程序可以直接将文件写到Web Server上,从而替代传统的FTP传输文件模式。
2 系统关键技术实现
存储平台通过在Hadoop上部署WebDAV,可实现客户端(应用服务器)对服务器端(Hadoop节点服务器)的复制和移动文件,并可进行多用户同时读取一个文件等操作。
实施步骤(以四台服务器为例,结合局域网内DNS服务器):
第一步:Hadoop环境搭建使用Hadoop的用户,机器名和IP依次为域名vc1(192.168.1.1),域名vc2(192.168.1.2),域名vc3(19 2.168.1.3)和域名vc4(192.168.1.4)。这是因为四台机器中vc3作为Hadoop的Namenode,其他的作为Datanode。
详细环境配置介绍如下:
Hadoop版本为0.20.2;
JDK版本为1.6.0;
操作系统为FreeBSD8.0(最小化安装)。
ve3(192.168.1.3)是NameNode(Master),其他三台作为DateNode(slave).
Hadoop是Java语言编写的机群程序,它的安装是建立在ssh和JDK之上的,所以在配置Hadoop之前首先要对系统进行ssh和JDK的安装与配置。
(1)通过ssh来实现Hadoop节点之间用户的无密码访问
①在各个节点的/etc/hosts文件中添加节点IP及对应机器名,并在各个节点上建立相同用户名与密码的账户。
修改/etc/hosts文件如下:
192.168.1.1 vc1
192.168.1.2 vc2
192.168.1.3 vc3
192.168.1.4 vc4
修改成功后就可以实现IP地址与机器名的对应解析。
在各个节点建立用户名为Hadoop,密码为123456的用户。
②实现节点间通过ssh无密码访问。
③测试是否配置成功。
通过ssh+机器名命令测试能否无密码访问其他计算机,如果无密码访问,则配置成功。
例:vc1使用ssh vc3是否能无密码访问vc3,vc3使用ssh vc1是否能无密码访问vc1(其他主机方法类似)?
(2)JDK的安装
在这里利用ports安装JDK。在安装时要先下载如下几个文件:
下载设置环境变量,修改/etc/profile文件。在该文件中添加如下代码:
保存后键入命令:
source/etc/profile
使环境变量设置生效。
安装好JDK后可以通过which命令来测试JDK是否安装成功:
which java
若是第一种方法,则显示信息如下:
/usr/local/jdk1.6.0/bin/java
若是第二种方法,则显示信息如下:
/usr/java/jkd1.6.0_12/bin/java
(3)进行Hadoop的安装和配置。
下载hadoop-0.20.2.tar.gz到/home/hadoop目录,并解压:
tar-vxzf hadoop-0.20.2.tar.gz//解压hadoop到当前目录
解压完后进入/home/hadoop/hadoop-0.20.2/conf目录进行配置。

配置文件修改完毕后格式化NameNode(运行Hadoop之前必须先进行格式化),进入/home/hadoop/hadoop-0.20.2/目录,命令如下:
.bin/hadoop namenode-format
格式化完毕后就可以运行Hadoop了,命令如下:
./bin/start-a11.sh //在/home/hadoop/hadoop-0.20.2/目录下运行
如果要停止运行如下命令:
./bin/stop-a11.sh //在/home/hadoop/hadoop-0.20.2/目录下运行
到此,Hadoop的配置已经完成了。
第二步:WebDAV部署
(1)修改配置
修改hdfs-webdav.war里面的WEB-INF/classes/hadoop-site.xml。
修改fs.default.name属性,以确定hdfs-webdav要连接的hadoopNameNode Server。示例:
property>
name>fs.default.name/name>
value>hdfs://192.168.52.129:9000//value>
description>namenode/description>
/property>
(2)替换hadoop-xxxx-core.jar版本
由于hadoop有自己的rpc远程调用实现,并且各个版本间可能不兼容(0.17.X与0.18.x之间就不兼容),所以需要将WEB-INF/lib/ha doop-XXXX-core.jar的版本与NameNode Server的版本一致,现war自带的是hadoop-0.18.1-core.jar的版本。
(3)部署至tomcat
以上修改完,将war包部署至tomcat或是jboss中,部署在其它服务器中时需要tomcat的catalina.jar与tomcat-coyote.jar,拷贝至WEB-INF/lib目录,因为现在项目是从tomcat的WebdavServlet中修改而来的。
(4)测试是否部署成功
访问http://localhost:8080/hdfs-webdav
第三步:webdav客户端访问
实现webdav的hdfs可以映射为windows或是linux本地文件夹。
(1)window网上邻居访问
打开“网上邻居”,添加网上邻居,在“请键入网上邻居的位置”中输入Web文件夹的URL。
http://loealhost:8080/hdfs-webdav
然后按照向导的提示继续下一步就可以了。
(2)Linux mount WebDav为本地文件系统
linux下想要mount WebDAV server为本地文件系统,必须要使用davfs2,项目网址为http://day.sourceforge.net/。
安装davfs2请使用编译安装。
davfs2编译时依赖于neon,neon是一个WebDAV client library.neon网址为http://www.webdav.org/neon/。
dsvfs2在mount时会使用fuse或是coda这两个文件系统,其中一个文件系统linux一般都有自带,davfs2在mount时会首先尝试使用fuse,失败时再使用coda。
但在CentOs中使用coda时发生如下错误,所以后面安装fuse,fuse网址为http://fuse.sourceforge.net/。
/sbin/mount.davfs:no free coda device to mount
/sbin/mount.davfs:trying fuse kernel file system
/sbin/mount.davfs:can't open fuse device
(3)neon,davfs2,fuse编译安装
项目的linux_mount_lib目录自带如下三个包:
①运行./configure;
②运行make;
③运行make install。
运行davfs2的mount命令
在mount之前,davfs2需要创建davfs2用户及用户组
[root@datacenter5 usr]# mkdir/data/hdfs
[root@datacenter5 usr]# groupadd davfs2
[root@datacenter5 usr]# useradd-g davfs2 davfs2
[root@datacenter5 usr]# mount.davfshttp://192.168.55.104:8080/hdfs-webdav/data/hdfs
3 系统应用拓补分析
基于服务器虚拟化(VMware)系统,制作出的云存储阵列,其中云主机控制云系统内的服务器集群,进行数据的写入与读出,由云主机提供的API接口(主要是WebDAV协议,也可采用其他协议)进行与客户应用服务器之间的数据存储、数据备灾、数据应用,这样能够尽可能地利用云的效率,如图2所示。
- dsPIC33F系列DSC的 SD存储卡接口设计(01-05)
- 基于闪烁存储器的TMS320VC5409 DSP并行引导装载方法(05-23)
- DSP外部Flash存储器在线编程的软硬件设计(07-10)
- DSP片外高速海量SDRAM存储系统设计(01-18)
- 一种新型的多DSP红外实时图像处理系统设计(02-03)
- 浅谈Win CE应用程序的可移植性(03-02)