基于TMS320C64x的MPEG-4实时编码器设计与实现
时间:10-12
来源:互联网
点击:
信息时代对于视频通讯的需求越来越广,从较低码率的可视电话、视频会议、实时监控到高码率的空中侦察、数字电视等,迫切要求将高效率、高质量的视频压缩算法实用化。MPEG-4于2000年正式成为国际标准并不断地扩展。它不仅支持码率低于64kbps的多媒体通信,还能支持广播级的视频应用。与以前的视频标准相比,MPEG-4可以提供更高的压缩效率、更好的交互性以及更强的抗误码能力。目前,MPEG-4已经成为视频压缩标准的主流。
MPEG-4算法非常复杂,其编解码的实时性难以保证,通常只能实现对中低分辩率视频的实时编码。本文基于TI公司的C64x系列DSPs设计并实现了一种MPEG-4编码器,实现了对D1分辨率(720×576)视频的实时编码,且在保证输出码率低于1Mbps的同时,解码图像具有较高的峰值信噪比和较好的视觉效果。
1 编码系统的硬件结构
编码系统以TMS320DM642高性能通用DSP芯片为核心。图1为系统框图。
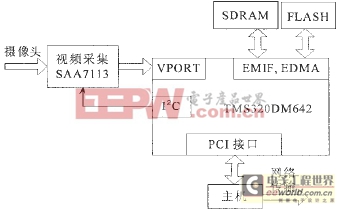
图1 编码器系统框图
1.1 TMS320DM642芯片的特点
DM642属于TI公司的C64x系列DSPs。Veloci TI结构使C6000 DSPs在视频和图像处理中得到广泛应用。CPU的VLIW结构由多个并行运行的执行单元组成,这些单元在单个周期内可执行多条指令。并行是C6000获得高性能的关键。C64x在C6000的基础上有一些重要的改进。除了有更高的时钟频率外,C64x从以前的Veloci TI结构扩展到Veloci TI.2结构,包含了许多新的指令,增加了额外的数据通道,寄存器的数量也增加了一倍。这些扩展使得CPU可以在一个时钟周期内处理更多的数据,从而获得更高的运算性能。
DM642芯片集成了各种片内外设,使得开发视频和图像领域的应用更为方便。它带有三个可配置的视频端口,提供与视频输入、视频输出以及码流输入的无缝接口。这些视频端口支持许多格式的视频输入/输出,包括BT.656、HDTV Y/C、RGB以及MPEG-2码流的输入。利用DM642开发视频编码器,其视频输入部分只需要一块视频采集芯片即可,如Phillips的SAA7113,无需外加逻辑控制电路和FIFO缓存,使硬件系统更为简单和稳定。DM642的其它外设包括:10Mbps/100Mbps的以太网口(EMAC)、多通道音频串口(McASP)、外部存储器接口(EMIF)、主机接口(HPI)、多通道缓冲串口(McBSP)以及PCI接口等。
1.2 系统工作流程
该编码系统可分为图像压缩卡和主机两部分。其工作流程如图2所示。

图2 系统工作流程图
首先主机通过PCI初始化DSP并对其加载程序;DSP开始运行MPEG-4编码程序,从视频端口获取实时采集的视频,如图1所示。SAA7113输出BT.656格式的数字视频,作为DM642 VPORT的输入,VPORT输出YUV(4:2:0)格式的图像,作为编码程序的输入;DSP完成一帧图像的编码,通过PCI向主机发出中断;主机响应中断,从DSP的存储空间读取原始图像数据和压缩后的码流。主机程序在VC++环境下编写,提供与用户交互的界面,可对数据进行各种处理,包括原始视频的实时播放、保存,压缩码流的实时解压播放、保存、回放、网络传输,从网络接收压缩码流实时解压回放等。
需要注意的是原始图像和压缩码流在DSP中的存储。视频端口、编码程序和主机都要访问原始图像,例如在某一时刻,编码程序访问当前帧图像,主机读取上一帧图像,而视频端口正在输入下一帧图像,为了避免访问冲突,原始图像在DSP中采用三缓冲区进行管理。压缩码流由编码程序写入,主机读取,所以采用乒乓制进行存储。
1.3 内存分配
DM642片内只有256KB的存储空间,因此当前帧、参考帧和当前帧的重建帧都必须放至片外存储器,压缩码流若被主机读取,也放至片外。其它数据如程序代码、全局变量、VLC码表、各编码模块产生的中间数据等均可放至片内。
由于CPU访问片外的速度通常要比访问片内慢几十倍,片外数据的传输通常成为程序运行时的瓶颈,即使代码效率很高,流水线也会因为等待数据而被严重阻塞。解决这一问题的有效方法是用EDMA传送数据。程序是逐个宏块进行编码的,在编码当前宏块的同时,EDMA将下一个宏块的数据、用到的参考帧数据由片外传送至片内;当前宏块做完运动补偿后,EDMA将重建后的宏块由片内传送至片外。这样CPU只对片内数据进行操作,使得流水线可以顺利进行,而压缩码流按逐个码字有时间间隔地写入,可由CPU直接写至片外。
2 采用预测技术的运动估计算法
运动估计是MPEG-4编码中计算量最大的一部分,占据整个编码时间的50%以上。各种快速运动估计算法也成为近年来研究的热点。本文通过实验证明,采用预测技术的运动估计不但可以大大缩短计算时间,而且也有助于提高图像的质量。
宏块(Macro Block)的运动矢量(Motion Vector)在时间和空间都具有相关性,预测的原理就是利用当前帧和参考帧内相邻位置宏块的MV来预测当前宏块的MV。下面详述本文所采用的预测算法。
(1)确定当前宏块MV的7个候选值PreMV1~7。
如图3所示。PreMV1=(0,0);PreMV4取当前宏块左边相邻宏块的MV值;PreMV5取上边相邻宏块的MV值;PreMV6取右上方相邻宏块的MV值;PreMV2=mid{PreMV4, PreMV5, PreMV6},即取三者的中值;PreMV3取参考帧相同位置宏块的MV值;PreMV7取参考帧右下方相邻宏块的MV值。
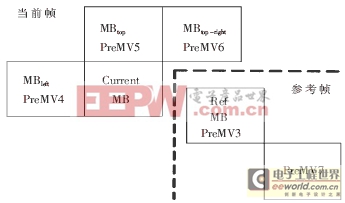
图3 预测运动矢量示意图
(2)确定筛选候选值的依据——SAD(绝对误差和)的门限值ThreshSAD。
SAD是确定最佳匹配块的准则。门限值ThreshSAD是指这样一个值:如果参考帧内某一宏块和当前宏块的SAD小于ThreshSAD,则当前宏块的MV值就可取作二者之间的位移。因此,ThreshSAD就可作为筛选7个候选值的依据。
由于SAD在空间上的相关性,ThreshSAD由相邻宏块的SAD值来确定:
ThreshSAD=Min{SADleft,SADtop,SADtop_left}
其中,SADleft、SADtop、SADtop-right分别为MBleft、MBtop、MBtop-right和其对应匹配块的SAD值,ThreshSAD取三者的最小值。
(3)从7个候选值中选出当前宏块的MV值。
按照PreMV1~7的顺序,依次计算当前宏块和7个匹配块的SAD值。如果有SAD值小于ThreshSAD,即停止计算,选用对应的PreMV作为当前宏块的MV值;如果7个SAD值均大于ThreshSAD,则采用运动搜索来确定当前宏块的MV值。该运动搜索并不以MV=(0,0)为中心,而是以对应SAD值最小的PreMV为中心,搜索采用简化的菱形算法。
对标准视频序列foreman.cif(352×288)进行编码(码率300kbps),测得表1所示数据。采用预测的运动估计算法利用视频序列在时间和空间上的相关性,无需对每个宏块都进行运动搜索,而且其搜索中心点也同样利用了相关信息,搜索算法也可进一步简化,因此大大减少了运动估计的计算量;同时,预测有助于提高图像质量,直接进行快速运动搜索通常会带来局部最小的问题,从而影响图像质量,而PreMV1~7取自位于当前宏块周围各个方向的宏块的MV值,避免陷入局部最小。
表1 预测技术对运动搜索性能的提高
MPEG-4算法非常复杂,其编解码的实时性难以保证,通常只能实现对中低分辩率视频的实时编码。本文基于TI公司的C64x系列DSPs设计并实现了一种MPEG-4编码器,实现了对D1分辨率(720×576)视频的实时编码,且在保证输出码率低于1Mbps的同时,解码图像具有较高的峰值信噪比和较好的视觉效果。
1 编码系统的硬件结构
编码系统以TMS320DM642高性能通用DSP芯片为核心。图1为系统框图。
图1 编码器系统框图
1.1 TMS320DM642芯片的特点
DM642属于TI公司的C64x系列DSPs。Veloci TI结构使C6000 DSPs在视频和图像处理中得到广泛应用。CPU的VLIW结构由多个并行运行的执行单元组成,这些单元在单个周期内可执行多条指令。并行是C6000获得高性能的关键。C64x在C6000的基础上有一些重要的改进。除了有更高的时钟频率外,C64x从以前的Veloci TI结构扩展到Veloci TI.2结构,包含了许多新的指令,增加了额外的数据通道,寄存器的数量也增加了一倍。这些扩展使得CPU可以在一个时钟周期内处理更多的数据,从而获得更高的运算性能。
DM642芯片集成了各种片内外设,使得开发视频和图像领域的应用更为方便。它带有三个可配置的视频端口,提供与视频输入、视频输出以及码流输入的无缝接口。这些视频端口支持许多格式的视频输入/输出,包括BT.656、HDTV Y/C、RGB以及MPEG-2码流的输入。利用DM642开发视频编码器,其视频输入部分只需要一块视频采集芯片即可,如Phillips的SAA7113,无需外加逻辑控制电路和FIFO缓存,使硬件系统更为简单和稳定。DM642的其它外设包括:10Mbps/100Mbps的以太网口(EMAC)、多通道音频串口(McASP)、外部存储器接口(EMIF)、主机接口(HPI)、多通道缓冲串口(McBSP)以及PCI接口等。
1.2 系统工作流程
该编码系统可分为图像压缩卡和主机两部分。其工作流程如图2所示。
图2 系统工作流程图
首先主机通过PCI初始化DSP并对其加载程序;DSP开始运行MPEG-4编码程序,从视频端口获取实时采集的视频,如图1所示。SAA7113输出BT.656格式的数字视频,作为DM642 VPORT的输入,VPORT输出YUV(4:2:0)格式的图像,作为编码程序的输入;DSP完成一帧图像的编码,通过PCI向主机发出中断;主机响应中断,从DSP的存储空间读取原始图像数据和压缩后的码流。主机程序在VC++环境下编写,提供与用户交互的界面,可对数据进行各种处理,包括原始视频的实时播放、保存,压缩码流的实时解压播放、保存、回放、网络传输,从网络接收压缩码流实时解压回放等。
需要注意的是原始图像和压缩码流在DSP中的存储。视频端口、编码程序和主机都要访问原始图像,例如在某一时刻,编码程序访问当前帧图像,主机读取上一帧图像,而视频端口正在输入下一帧图像,为了避免访问冲突,原始图像在DSP中采用三缓冲区进行管理。压缩码流由编码程序写入,主机读取,所以采用乒乓制进行存储。
1.3 内存分配
DM642片内只有256KB的存储空间,因此当前帧、参考帧和当前帧的重建帧都必须放至片外存储器,压缩码流若被主机读取,也放至片外。其它数据如程序代码、全局变量、VLC码表、各编码模块产生的中间数据等均可放至片内。
由于CPU访问片外的速度通常要比访问片内慢几十倍,片外数据的传输通常成为程序运行时的瓶颈,即使代码效率很高,流水线也会因为等待数据而被严重阻塞。解决这一问题的有效方法是用EDMA传送数据。程序是逐个宏块进行编码的,在编码当前宏块的同时,EDMA将下一个宏块的数据、用到的参考帧数据由片外传送至片内;当前宏块做完运动补偿后,EDMA将重建后的宏块由片内传送至片外。这样CPU只对片内数据进行操作,使得流水线可以顺利进行,而压缩码流按逐个码字有时间间隔地写入,可由CPU直接写至片外。
2 采用预测技术的运动估计算法
运动估计是MPEG-4编码中计算量最大的一部分,占据整个编码时间的50%以上。各种快速运动估计算法也成为近年来研究的热点。本文通过实验证明,采用预测技术的运动估计不但可以大大缩短计算时间,而且也有助于提高图像的质量。
宏块(Macro Block)的运动矢量(Motion Vector)在时间和空间都具有相关性,预测的原理就是利用当前帧和参考帧内相邻位置宏块的MV来预测当前宏块的MV。下面详述本文所采用的预测算法。
(1)确定当前宏块MV的7个候选值PreMV1~7。
如图3所示。PreMV1=(0,0);PreMV4取当前宏块左边相邻宏块的MV值;PreMV5取上边相邻宏块的MV值;PreMV6取右上方相邻宏块的MV值;PreMV2=mid{PreMV4, PreMV5, PreMV6},即取三者的中值;PreMV3取参考帧相同位置宏块的MV值;PreMV7取参考帧右下方相邻宏块的MV值。
图3 预测运动矢量示意图
(2)确定筛选候选值的依据——SAD(绝对误差和)的门限值ThreshSAD。
SAD是确定最佳匹配块的准则。门限值ThreshSAD是指这样一个值:如果参考帧内某一宏块和当前宏块的SAD小于ThreshSAD,则当前宏块的MV值就可取作二者之间的位移。因此,ThreshSAD就可作为筛选7个候选值的依据。
由于SAD在空间上的相关性,ThreshSAD由相邻宏块的SAD值来确定:
ThreshSAD=Min{SADleft,SADtop,SADtop_left}
其中,SADleft、SADtop、SADtop-right分别为MBleft、MBtop、MBtop-right和其对应匹配块的SAD值,ThreshSAD取三者的最小值。
(3)从7个候选值中选出当前宏块的MV值。
按照PreMV1~7的顺序,依次计算当前宏块和7个匹配块的SAD值。如果有SAD值小于ThreshSAD,即停止计算,选用对应的PreMV作为当前宏块的MV值;如果7个SAD值均大于ThreshSAD,则采用运动搜索来确定当前宏块的MV值。该运动搜索并不以MV=(0,0)为中心,而是以对应SAD值最小的PreMV为中心,搜索采用简化的菱形算法。
对标准视频序列foreman.cif(352×288)进行编码(码率300kbps),测得表1所示数据。采用预测的运动估计算法利用视频序列在时间和空间上的相关性,无需对每个宏块都进行运动搜索,而且其搜索中心点也同样利用了相关信息,搜索算法也可进一步简化,因此大大减少了运动估计的计算量;同时,预测有助于提高图像质量,直接进行快速运动搜索通常会带来局部最小的问题,从而影响图像质量,而PreMV1~7取自位于当前宏块周围各个方向的宏块的MV值,避免陷入局部最小。
表1 预测技术对运动搜索性能的提高
TMS320C64x MPEG-4 编码器 相关文章:
- TMS320C64x的16-bit Flash加载的可行性分析与实现(10-16)
- 基于TMS320C64x 的MPEG-4实时编码器设计与实现(11-01)
- 用定制DSP设计MPEG-4无线视频产品(04-11)
- TMS320C6201在MPEG-4视频解码器中的应用 (07-13)
- 基于DSP设计MPEG-4无线视频产品(02-16)
- 基于DSP的数码相机中的MPEG-4压缩方案设计(03-24)