基于TMS320DM3730的H.264编码器移植与优化方法研究
DSP芯片技术的快速发展为实现嵌入式多媒体技术提供了可能。TMS320DM3730(简称DM3730)作为TI公司2010年推出的高性能芯片,以其ARM+DSP结构体系、运算速度快、众多多媒体接口等优点成为进行嵌入式系统开发首选平台之一。
常用的H.264编码器有JM编码器、x264编码器,T264编码器,x264编码器作为其中应用最广,效率最好的编码器,是进行嵌入式开发的首选H.264编码器。故本文在DM3730数字媒体处理器上进行x264编码器的移植与优化。本文首先介绍了DM3730的基本的结构和特点;然后结合DM3730的DSP,介绍了x264编码器的移植和优化;最后进行编码测试,结果表明编码器移植的正确性,编码速度得到了极大提高。
1 DM3730简单介绍
DM3730数字媒体处理器是美国德州仪器(TI)推出的一款高性能达芬奇(DaVinci)芯片,由1 GHz的ARM Coretex—A8和800 MHz的TMS320 C64x+DSP Core两部分组成,并集成了包括3D图像处理器,图像采集,USB2.0等模块。其整体结构如图1所示。

DM3730中ARM核作为主控制部分,负责整个芯片部分的设备的配置和控制、内存的分配、同外部接口的数据的交换;DSP核主要进行数据的处理和计算,其主频高达800MHz,采用VLIW(超长指令字)体系结构,包含8个独立的功能单元,每个功能单元在每个时钟周期执行一条指令,最高运算速度高达6 400 MMACS(百万乘法累加周期每秒)。同时拥有A、B两个通用寄存器组。每个都有32个32-bits寄存器组成,每个通用寄存器都可以存放数据、地址和指针。
2 x264的移植
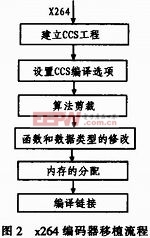
CCS(Code Composer Stdio)是TI公司提供的用于C语言开发的开发平台,该平台可以使用C语言进行DSP程序的开发。本文基于CCS4.2平台进行x264编码器的移植,具体流程如图2所示。
 2.1 CCS工程的建立
2.1 CCS工程的建立
在CCS环境下分别建立两个工程:静态库工程Libx264.pjt和可执行工程x264.pjt。静态库工程Libx264.pjt包含x.264编码所需要的绝大部分的函数,编译链接生成可进行调用的Libx264.lib文件。可执行工程x264.pjit工程是x264编码程序的主体的框架,包括编码参数的初始化、文件的输入输出以及图像的编码循环等主函数实现部分。该工程添加对Libx264.lib文件的引用,最终编译链接生成x264.out可执行文件。
2.2 CCS中编译选项的设置
在CCS4.2平台下必须对Libx264.pjt和x264.pjt工程设置合适编译选项:
1)DM3730的DSP核为C64x+版本,故目标处理器版本选项选择为-mv64004+
2)编译器默认的内存模式为Near模式,而在Near模式下要求.BSS段必须小于32 kB,.BSS段存取的是工程中的全局变量和静态变量,x264工程中的全局变量和静态变量已经远大于32 kB,故将Data access model和Const access model设置为Far。
3)在DM3730中使用的是小端模式的字节存储即低位字节先存储,故在CCS4.2中Device Endianess(设备字节存储次序)设置为little-endian。
2.3 算法的剪裁
1)MMX、SSE汇编指令的去除
在x264中有很多计算量大的函数例如DCT变换、运动估计、量化等都是使用MMX、SSE汇编指令进行实现的,但是这些汇编都是针对X86平台、AMD平台,在DSP的结构下不能用,需要删除这些汇编实现文件,并将宏定义_HAVE_MMX_进行删除。
2)精简代码
考虑到x264的编码的效率,采用了H.264中的baseline级别进行编码,去除了CABAC(基于内容的自适应二进制编码)和B帧(双向预测帧)这两个特性。这样虽然一定程度上增加了编码的码率,但是对编码速度的提高很明显。编码采用固定量化参数,不使用码率控制,保留所有帧内预测模式和帧间预测分块模式进行编码,同时去除x264的多余的打印信息和help信息以提高编码速度。
2. 4 函数、数据类型的修改
在编译过程中函数名为isfinite的函数会出现重定义的错误,原因是在CCS4.2包含的头文件中对该函数名有定义的,而x264中也有对其的定义,只需要将函数名进行修改一些即可。
同时由于硬件平台的差异,C语言中有些数据类型对应的字节长也会有差异的,为了让程序更好的兼容硬件平台,x264程序使用了通用的数据类型定义。通用数据类型一般在stdint.h中定义,VC++中并没有提供通用数据类型,而CCS中则提供了stdint.h,同时它包含于intty pe.h中,故移植到CCS中时应该包含#includeinttype.h>。
2.5 内存的分配
x264程序中存在很多使用malloc进行动态的内存分配,这样会大大提高占用堆栈的大小,应该尽量的将动态内存分配使用静态的数组进行替代。同时在嵌入式系统中,合理的分配堆栈的大小对一个程序也是相当重要的。由于x264中动态内存的申请、静态的表格数组和全局变量比较多,故在cmd文件中对堆栈的大小定义设为:
-stack 0x8000
-heap 0x400000
同时将x264程序中的代码和数据的段地址全部放置到外部寄存器中。
3 x264编码器的优化
x264成功移植后在DM3730上进行CIF(通用影像传输格式)格式图像编码测试,平均编码速度只有1fps(帧每秒)左右,离实时编码差距很大,需要对x264编码器进行优化工作。优化的方法包括编译器优化、内存优化、C语言优化和汇编优化。
3.1 编译器优化
在使用C编译器连接和生成最终DSP可执行代码时,CCS上的C编译器拥有非常出色的优化性能,可以通过设置编译优化选项进行编译器的自我优化。表1所示是CCS4.2中一些优化选项及其功能列表。
TMS320DM3730 H.264 编码器 相关文章:
- 基于ARM Linux的3G无线车载视频监控系统(03-05)
- 基于ARM的移动视频监控终端设计与实现(08-09)
- Reed Solomon编解码器的可编程逻辑实现(06-21)
- WinCE下光电编码器的驱动程序设计(04-12)
- 一种基于DSP的张力、深度、速度测量系统(04-15)
- 用数字信号处理器优化视频编码器(03-11)